Updated May 3, 2023

Introduction to PostgreSQL GROUP BY
The group by a statement in PostgreSQL divides the rows from the select statement into groups; we can apply an aggregate function to each group in PostgreSQL group by clause, group by clause is very important in PostgreSQL to divide rows from the select statement into no of groups. It is also used to collaborate the select statement to group the output data to this group which was identical in nature; this is used to eliminate redundancy of data into the output to compute aggregates that apply to those groups.
Syntax
Select expr1, expr2, …. , exprN, (Column name)
aggregate_function (expr)
From tables
Where [ condition ]
GROUP BY expr1, expr2, …. , exprNSelect column_list (list of column we have used to fetch data from table)
From table_name (table name)
Where [ condition ]
GROUP BY col1, col2, …, colN (List of column that used in group by clause)
ORDER BY col1, col2, …, colN (List of column that used in order by clause)Select expr1, expr2, …. , exprN, (Column name which is used fetch data from table)
From table_name (Name of table)
Where [ condition ]
GROUP BY col1, col2, …, colN (Column list)
ORDER BY col1, col2, …, colNBelow is the parameter description of the above syntax:
- expr 1 to expr N: It is nothing but the column name that we have used in the table to fetch data from the table.
- An aggregate function: The aggregate function that we have used in group by clause to fetch data from the table can be (SUM, MIN, AVG, MAX, and COUNT).
- Table name: The table name from which we are retrieving data.
- Where condition: This is optional. This is used to select specific data.
- Group by: Group by clause used to retrieve data from the table.
- Column1 to columnN: Number of columns used to retrieve data from the table.
How PostgreSQL GROUP BY clause works?
- In PostgreSQL, you use the “GROUP BY” clause to group rows that have identical data.
- To choose the statement or get identical data from the database, use this clause.
- This clause will collect data across multiple records and group results with one or more columns.
- This clause is also used to reduce the redundancy of data.
- Group by clause is used to reduce the redundancy of data into no rows in PostgreSQL.
- The records will be grouped into summary rows by this clause, which will then return a vast amount of data in smaller groupings.
- This clause divides the rows into smaller groups that have the same values in the specific column.
- A select statement utilizes the “GROUP BY” clause to group rows together based on their values for a specific expression or group.
Examples
We have using the employee table to describe the group by clause in PostgreSQL.
Code:
CREATE TABLE Employee ( emp_id INT NOT NULL, emp_name character(10) NOT NULL, emp_address character(20) NOT NULL, emp_phone character(14), emp_salary INT NOT NULL, PRIMARY KEY (emp_name));Output:
![]()
Code:
# INSERT INTO Employee (emp_id, emp_name, emp_address, emp_phone, emp_salary) VALUES (1, 'ABC', 'Pune', '1234567890', 20000);
# INSERT INTO Employee (emp_id, emp_name, emp_address, emp_phone, emp_salary) VALUES (1, 'PQR', 'Pune', '1234567890', 20000);
# INSERT INTO Employee (emp_id, emp_name, emp_address, emp_phone, emp_salary) VALUES (1, 'XYZ', 'Mumbai', '1234567890', 35000);
# INSERT INTO Employee (emp_id, emp_name, emp_address, emp_phone, emp_salary) VALUES (2, 'BBS', 'Mumbai', '1234567890', 45000);
# INSERT INTO Employee (emp_id, emp_name, emp_address, emp_phone, emp_salary) VALUES (2, 'RBS', 'Delhi', '1234567890', 50000);Output:
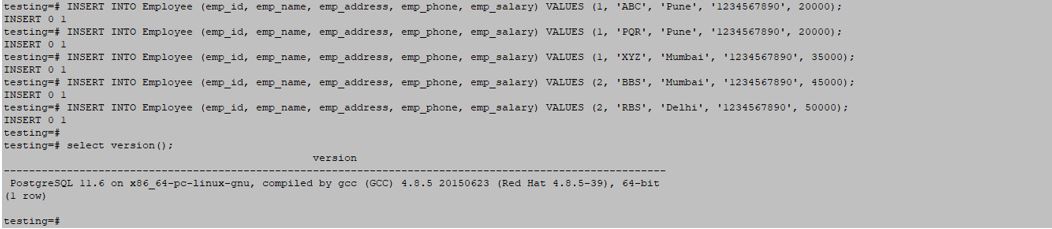
Example #1 – Using SUM function
Code:
testing=# SELECT emp_id, sum(emp_salary) AS "Salary of employee" FROM employee GROUP BY emp_id;Output:
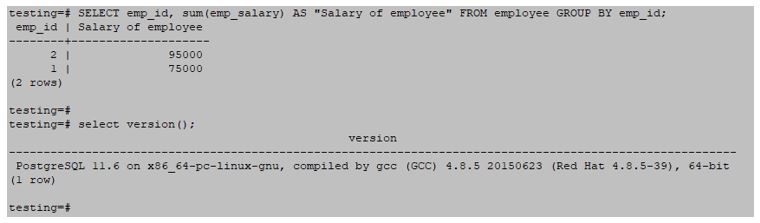
Example #2 – Using MIN function
Code:
SELECT emp_id, MIN(emp_salary) AS "Salary of employee" FROM employee GROUP BY emp_id;Output:
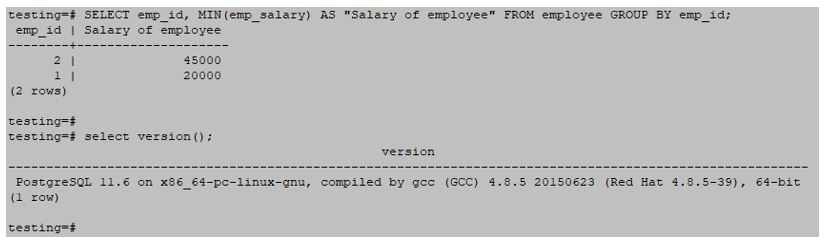
Example #3 – Using MAX function
Code:
SELECT emp_id, MAX(emp_salary) AS "Salary of employee" FROM employee GROUP BY emp_id;Output:
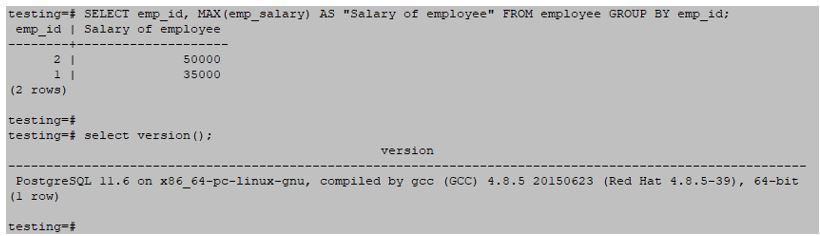
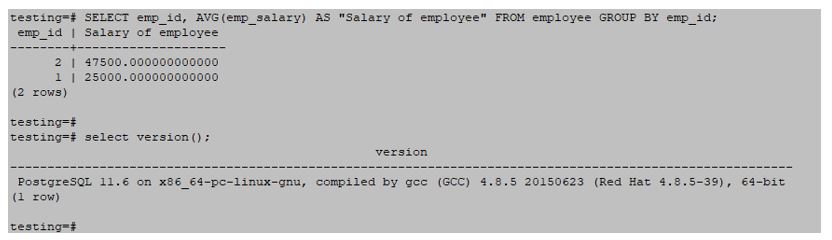
Example #4 – Using the AVG function
Code:
SELECT emp_id, AVG(emp_salary) AS "Salary of employee" FROM employee GROUP BY emp_id;Output:
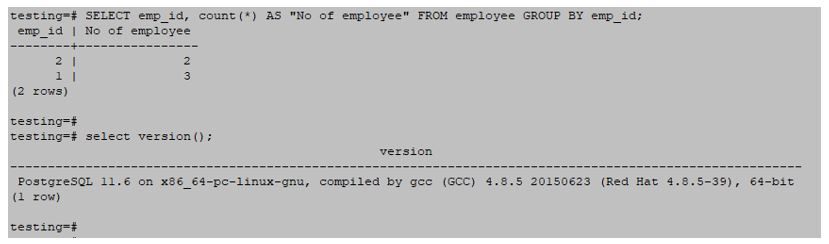
Example #5 – Using COUNT function
Code:
SELECT emp_id, count(*) AS "No of employee" FROM employee GROUP BY emp_id;Output:
Importance of PostgreSQL GROUP BY
- The set combines or consolidates the number of columns using this clause.
- You can use the “JOIN” clause to combine rows from different tables based on identical data selected in the select statements
- Identical data will merge in the clause. Group by clause is most important in PostgreSQL.
- It follows after where clause in the select statement and after the order by clause.
- This clause is most important in PostgreSQL.
Conclusion
Group by clause is most important in PostgreSQL to retrieve data from a single set. When using a select statement, one utilizes the group by clause to consolidate data from multiple rows into one or more columns. Identical data will merge in this clause.
Recommended Articles
We hope that this EDUCBA information on “PostgreSQL GROUP BY” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
