Updated April 3, 2023

Introduction to PySpark AGG
PYSPARK AGG is an aggregate function that is functionality provided in PySpark that is used for operations. The aggregate operation operates on the data frame of a PySpark and generates the result for the same. It operates on a group of rows and the return value is then calculated back for every group. The function works on certain column values that work out and the result is displayed over the PySpark operation.
There are certain aggregate functions in PySpark that are used for the operation in the Python PySpark model. Some of them include the count, max ,min,avg that are used for the operation over columns in the data frame. The function calculates on the set of values given and returns a single value.
In this article, we will try to analyze the various method used for the Aggregation of data in PySpark.
Syntax for PySpark Agg
The syntax is as given below:
c.agg({'ID':'sum'}).show()- c: The new data frame post group by.
- agg: The Aggregate function to be used based on column value.
- sum: Aggregation valueas Sum.
Output:

How does AGG Operation Work in PySpark?
Aggregation is a function that aggregates the data based on several logical rules over the PySpark data frame. It operates over a group of rows and calculates the single return value based on every group. The aggregate function returns the same values every time when they are called. We have a defined set of aggregate functions that operate on a group of data in PySpark and the result is then returned back in memory.
We have several defined aggregate function having a defined functionality for several functions, some of the aggregate function includes avg , max , min ,count , the sum that are used for various data level operation.
Let’s check the creation and working of the Aggregate function with some coding examples.
Examples of PySpark AGG
Let us see some examples of how PYSPARK AGG operation works. Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Output:

Let us try to aggregate the data of this PySpark Data frame.
We will start by grouping up the data using data.groupBy() with the name of the column that needs to be grouped by.
c = b.groupBy('Name')This groups the column based on the Name of the PySpark data frame. Post which we can use the aggregate function.
c.count()
c.count().show()Output:
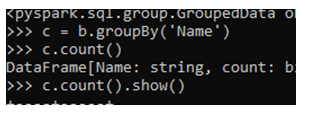
The dataframe.agg function takes up the column name and the aggregate function to be used. Let’s check this with examples. The SUM function sums up the grouped data based on column value.
c.agg({'ID':'sum'}).show()The MAX function checks out the maximum value of the function based on the column name provided.
c.agg({'ID':'max'}).show()The COUNT function count of the total grouped data was included.
c.agg({'ID':'count'}).show()Output:
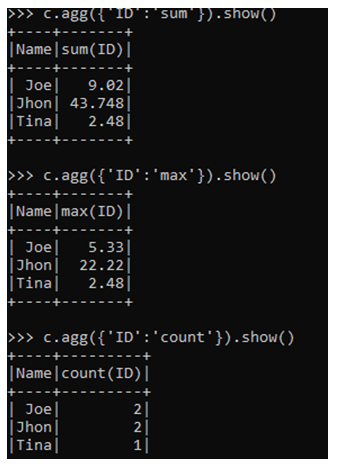
The first function aggregates the data and collects the first element from the PySpark data frame.
c.agg({'ID':'first'}).show()The last function aggregates the data and fetches out the last value.
c.agg({'ID':'last'}).show()The AVG function averages the data based on the column value provided.
c.agg({'ID':'avg'}).show()Output:
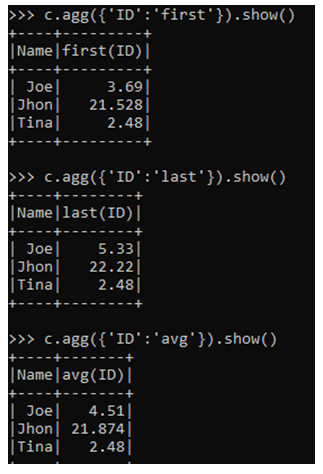
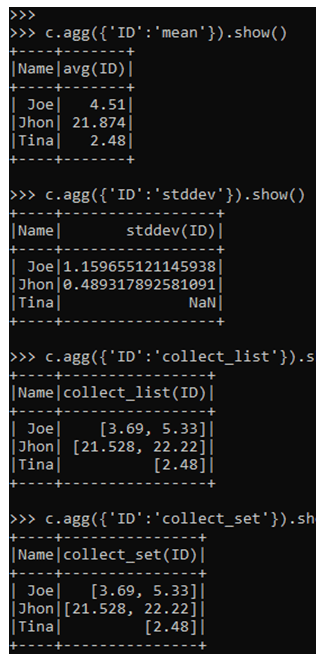
The MEAN function computes the mean of the column in PySpark. It is an aggregate function.
c.agg({'ID':'mean'}).show()The STDDEV function computes the standard deviation of a given column.
c.agg({'ID':'stddev'}).show()The collect_list function collects the column of a data frame as LIST element.
c.agg({'ID':'collect_list'}).show()The collect_set function collects the data of the data frame into the set and the result is displayed.
c.agg({'ID':'collect_set'}).show()Output:
Note:
- PySpark AGG is a function used for aggregation of the data in PySpark using several column values.
- PySpark AGG function returns a single value out of it post aggregation.
- PySpark AGG function is used after grouping of columns in PySpark.
- PySpark AGG functions are having a defined set of operations for a list of columns passed to them.
- PySpark AGG involves data shuffling and movement.
Conclusion
From the above article, we saw the working of AGG in PySpark. From various examples and classification, we tried to understand how this AGG operation happens in PySpark AGG and what are is used at the programming level. We also saw the internal working and the advantages of AGG in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark AGG. Here we also discuss the introduction and how AGG operation works in PySpark along with different examples and its code implementation. You may also have a look at the following articles to learn more –

