Updated March 30, 2023

Introduction to PySpark apply function to column
PySpark Apply Function to Column is a method of applying a function and values to columns in PySpark; These functions can be a user-defined function and a custom-based function that can be applied to the columns in a data frame.
The function contains the needed transformation that is required for Data Analysis over Big Data Environment. We can update, apply custom logic over a function-based model that can be applied to the Column function in PySpark data frame / Data set model.
This article will try to analyze the various ways of using the PYSPARK Apply Function to Column operation PySpark.
Let us try to see about PYSPARK Apply Function to Column operation in some more details.
The syntax for Pyspark Apply Function to Column
The syntax for the PYSPARK Apply function is:-
from pyspark.sql.functions import lower,colb.withColumn("Applied_Column",lower(col("Name"))).show()The Import is to be used for passing the user-defined function.
B:- The Data frame model used and the user-defined function that is to be passed for the column name. It takes up the column name as the parameter, and the function can be passed along.
Screenshot:-

Working of Apply Function to Columns in Pyspark
Let us see how Apply Function to Column works in PySpark:-
The function can be a set of transformations or rules that a user can define and apply to a column in the data frame/data set. This function allows the user a set of rules, and that rules can be used by registering over a spark session and apply to the columns needed. There are inbuilt functions also provided by PySpark that can be applied to columns over PySpark. The result is then returned with the transformed column value. The function is loaded first in the PySpark memory if it is a user-defined function, and then the column values are passed that iterates over every column in the PySpark data frame and apply the logic to it.
The inbuilt functions are pre-loaded in PySpark memory, and these functions can be then applied to a certain column value in PySpark. The result then is stored and returned back over columns in the PySpark data model.
Let’s check the creation and working of Apply Function to Column with some coding examples.
Example of PySpark apply function to column
Let us see some examples of how PySpark Sort operation works:-
Let’s start by creating a sample data frame in PySpark.
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains Name, Salary and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc.parallelize will be used for the creation of RDD with the given Data.
b = spark.createDataFrame(a)Post creation, we will use the createDataFrame method for the creation of Data Frame.
This is how the Data Frame looks.
b.show()Screenshot:-

Let’s start by using a pre-defined function in the Spark Data frame and apply this to a column in the Data frame and check how the result is returned.
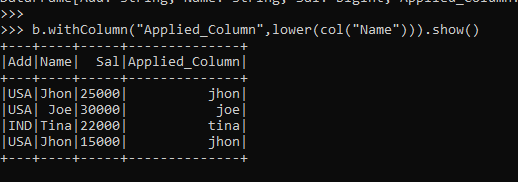
from pyspark.sql.functions import lower,colThe Import statement is to be used for defining the pre-defined function over the column.
b.withColumn("Applied_Column",lower(col("Name"))).show()The with Column function is used to create a new column in a Spark data model, and the function lower is applied that takes up the column value and returns the results in lower case.
Screenshot:-
We will check this by defining the custom function and applying this to the PySpark data frame. We will start by using the necessary Imports.
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import lower,col,udfWe will define a custom function that returns the sum of Sal over and will try to implement it over the Columns in the Data Frame.
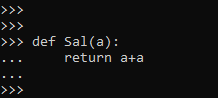
def Sal(a):
... return a+a
...Screenshot:-
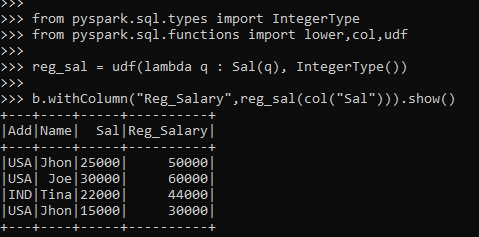
We will start by registering the UDF first, indicating the return type. After that, the UDF is registered in memory and is this can be used to pass it over column value.
This function is returning a new value by adding the SUM value with them.
reg_sal = udf(lambda q : Sal(q), IntegerType())The custom user-defined function can be passed over a column, and the result is then returned with the new column value.
b.withColumn("Reg_Salary",reg_sal(col("Sal"))).show()Screenshot:-
These are some of the Examples of Apply Function to Column in PySpark.
Note:-
- Apply Function to Column is an operation that is applied to column values in a PySpark Data Frame model.
- Apply Function to Column applies the transformation, and the end result is returned as a result.
- Apply Function to Column uses predefined functions as well as a user-defined function over PySpark.
- Apply Function to Column can be applied to multiple columns as well as single columns.
Conclusion
From the above article, we saw the working of Apply Function to Column. From various examples and classification, we tried to understand how this Apply function is used in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of having Apply function in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark apply function to column. Here we discuss the internal working and the advantages of having Apply function in PySpark Data Frame and its usage in various programming purpose. You may also have a look at the following articles to learn more –

