Updated March 16, 2023

Introduction to PySpark Cheat Sheet
Pyspark cheat sheet is the API for apache, we can use python to work with RDS. Apache spark is known as the fast and open-source engine for processing big data with built-in modules of SQL and machine learning and is also used for graph processing. It allows us to speed the analytic applications 100 times faster as compared to the other technologies.
Definition of PySpark Cheat Sheet
PySpark cheat sheet is important in data engineering, while increasing the requirement for a crunch of data, businesses will incorporate the data stack for processing large amounts of data which was maintained by apache. The important thing in the Cheat Sheet is data bricks. We can say that the Cheat Sheet is faster compared to Pandas cheat sheet. It contains initializing and loading our data to retrieve the information of RDD which sorts, filters and samples our data. It is also used to create an informative and attractive sheet in python PySpark.
PySpark Cheat Sheet Configuration
We can configure the cheat sheet as follows. For configuring we need to follow the below steps. In the first example, we are installing PySpark by using the pip command.
1. In the first step, we are installing the PySpark module by using the pip command as follows. We can also install the same by using another command.
pip install pyspark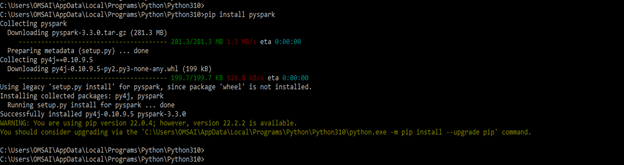
2. To check the PySpark model is installed in our system we need to login into the python module. The below example shows that login into the python shell.
python
3. While login into the shell of python in this step we are importing the PySpark module. We are importing the module by using the import keyword as follows. In the below example, we are importing the spark conf and spark context module as follows.
from pyspark import SparkConf, SparkContext
4. After importing the module in this step, we are configuring the Cheat Sheet module as follows. We are giving the application name as PySpark config.
pyspark_conf = (SparkConf()
.setMaster ("local")
.setAppName ("Pyspark config")
. set ("spark. executor.memory", "lg"))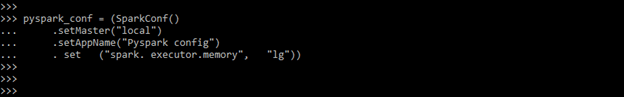
5. After defining the configuration of the Cheat Sheet now we are configuring the Cheat Sheet. In the below example we are defining the variable name as pyspark_cheat.
pyspark_cheat = SparkContext (conf = pyspark_conf)
Initialization
At the time of working with the Cheat Sheet, the initialization is a very important step, without initialization we cannot create the cheat sheet. The below steps show how we can initialize this as follows.
a) In the first step, we are importing the PySpark module. We are importing the spark context module by using the import keyword as follows.
from pyspark import SparkContext
b) After importing the module in this step we are creating the spark context as follows. We are defining the variable name as config.
config = SparkContext(master = 'local[2]')
c) After creating the spark context in this step we are checking the version of spark context and python as follows. In the below example, the spark context version is 3.3.0 and the python version is 3.10.
config.version
config.pythonVer
d) After defining the version now in this step we are connecting to the master URL, also we are checking the path where our spark is installed.
config.master
str(config.sparkHome)
e) After connecting to the master URL now we are retrieving the name of the master user. We can see that the name of the master user is OMSAI.
str(config.sparkUser())
f) In the below example we are checking the application name and application id of initialized application as follows. In the below example, we can see that the application name pyspark-shell.
config.applicationId
config.appName
g) After checking the application name and application ID, in this step, we are returning the default level of parallelism and partitioning as follows.
config.defaultParallelism
config.defaultMinPartitions
How to Create PySpark Cheat Sheet DataFrames?
The below steps show how we can create data frame.
1. In the first step, we are importing the PySpark sql module by using the import command as follows.
from pyspark.sql.types import*![]()
2. After importing the module in this step we are configuring the spark context and also loading the data for the data frame as follows.
py = sc.parallelize ([('p', 5), ('q', 3), ('r',3)])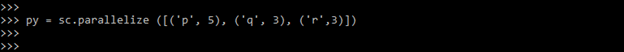
3. In the below example we are also loading the data for creating the data frame as follows.
pyspark1 = sc.parallelize ([('p', 3), ('s', 2), ('r', 2)])
pyspark2 = sc.parallelize(range (100))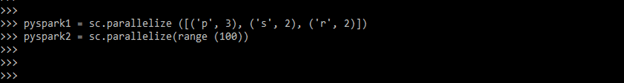
4. After loading the data now in this step, we are creating the data frame by using the above data as follows.
py = sc.parallelize ([("p",["a", "b", "c"]),
("q" ["x", "z"])])
Examples
Below are the examples as follows.
Example #1
Here we are configuring the cheat sheet.
Code:
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setMaster ("py_local")
.setAppName("Pyspark local config")
. set ("spark.executor.memory", "lg"))
pyspark_cheat = SparkContext (conf = conf)Output:

Example #2
In the below example, we are loading the data.
Code:
from pyspark.sql import Row
py1 = Row (original_title = 'ABC', budget = '1', year = 2001)
py2 = Row (original_title = 'PQR', budget = '2', year = 2002)
pyspark = [py1, py2]
cheat = spark.createDataFrame (pyspark)
cheat.show ()Output:

Key Takeaways
- At the time of working on the PySpark cheat sheet, we need to initialize the PySpark cheat sheet first and without initializing the same we cannot create the cheat sheet.
- While using this cheat sheet we need to import the PySpark module by using the import keyword.
FAQ
Given below is the FAQ mentioned:
Q1. What is the use of the PySpark cheat sheet in python?
Answer: We are using a python cheat sheet to read data more clearly and informally. A python cheat sheet is important in python.
Q2. What is the use of data frame in the PySpark cheat sheet?
Answer: Data frame is useful for creating the same. We can use a text file or CSV file to create a PySpark cheat sheet.
Q3. How we can modify the data frame in the PySpark cheat sheet?
Answer: Data frame will abstract away from RDD. Dataset is not coming in tabular, we are loading the dataset by text or CSV file.
Conclusion
The important thing in the PySpark cheat sheet is data bricks. The PySpark cheat sheet is important in data engineering. Apache spark is known as the fast and open-source engine for the processing of big data with built-in modules of SQL, and machine learning and is also used for graph processing.
Recommended Articles
This is a guide to PySpark Cheat Sheet. Here we discuss the introduction, configuration, initialization, and how to create PySpark Cheat Sheet data frames along with examples. You may also have a look at the following articles to learn more –
