Updated April 11, 2023

Introduction to PySpark collect
PYSPARK COLLECT is an action in PySpark that is used to retrieve all the elements from the nodes of the Data Frame to the driver node. It is an operation that is used to fetch data from RDD/ Data Frame. The operation involves data that fetches the data and gets it back to the driver node.
The collect operation returns the data as an Array of Row Types to the driver; the result is collected and further displayed for PySpark operation. The data, once is available on the node, can be used in the loops and displayed. The collect operation is widely used for smaller Data Set the data which can be fit upon memory or post that can cause some certain memory exception too. Let’s check the Collect operation in detail and try to understand the functionality for the same.
Syntax For PySpark collect
The syntax for the COLLECT function is:-
cd = spark.sparkContext.parallelize(data1)
cd.collect()explanation:
Cd:- The RDD made from the Data
.collect () :- The function used for Collecting the RDD.
Screenshot:
![]()
Working of Collect in Pyspark
Let us see somehow the COLLECT operation works in PySpark:-
- Collect is an action that returns all the elements of the dataset, RDD of a PySpark, to the driver program. It is basically used to collect the data from the various node to the driver program that is further returned to the user for analysis.
- The data post-collection is held into memory returned, so it is not advisable to collect huge data. Data with low volume is advisable for data collection, or data with a filter can be used further.
- Retrieving the huge data set can sometimes cause an out-of-memory issue over data collection.
- This is a network movement action call where all the elements from the different nodes are sent to the driver memory where the data is collected, so the data movement is much over the collect operation. Since it is an action call of PySpark so every time it is called, all the transformations are done prior to implementing its action.
- It retrieves the element in the form of Array [Row] to the driver program.
Let’s check the creation and usage with some coding examples.
Example of PySpark collect
Let us see some Example of how the PYSPARK COLLECT operation works:-
Let’s start by creating simple data in PySpark.
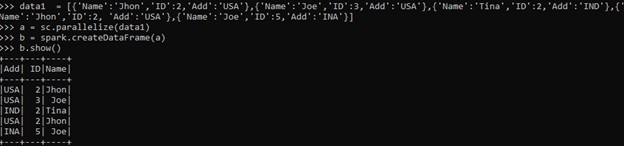
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'},{'Name':'Jhon','ID':2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc. parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:
Now let us try to collect the elements from the RDD.
a=sc.parallelize(data1)
a.collect()This collects all the data back to the driver node, and the result is then displayed as a result at the console.
Screenshot:

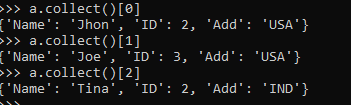
a.collect()[0]
a.collect()[1]
a.collect()[2]The above code shows that we can also select a selected number of the column from an RDD/Data Frame using collect with index. The index is used to retrieve elements from it.
Screenshot:
Collecting larger data can cause a memory exception; the point is if the data that needs to be collected is more than that of the cluster’s memory.
Let’s try to understand this with more Example:-
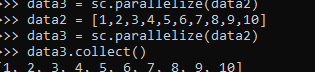
data3 = sc.parallelize(data2)
data2 = [1,2,3,4,5,6,7,8,9,10]
data3 = sc.parallelize(data2)
data3.collect()This is a very simple way to understand more about collect where we have made a simple RDD of type Int. Post collecting, we can get the data back to driver memory as a result. All the data Frames are called back to the driver, and the result is displayed back. Once the data is available, we can use the data back for our purpose, data analysis and data modeling.
Screenshot:-
These are some of the Examples of PYSPARK ROW Function in PySpark.
Note:-
- COLLECT is an action in PySpark.
- COLLECT collects the data back to the driver node.
- PySpark COLLECT returns the type as Array[Row].
- COLLECT can return data back to memory so that excess data collection can cause Memory issues.
- PySpark COLLECT causes the movement of data over the network and brings it back to the driver memory.
- COLLECTASLIST() is used to collect the same but the result as List.
Conclusion
From the above article, we saw the use of collect Operation in PySpark. We tried to understand how the COLLECT method works in PySpark and what is used at the programming level from various examples and classification.
We also saw the internal working and the advantages of having Collected in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to the PySpark collect. Here we discuss the use of collect Operation in PySpark with various examples and classification. You may also have a look at the following articles to learn more –

