Updated April 12, 2023

Introduction to PySpark Column to List
PYSPARK COLUMN TO LIST is an operation that is used for the conversion of the columns of PySpark into List. The data frame of a PySpark consists of columns that hold out the data on a Data Frame. The PySpark to List provides the methods and the ways to convert these column elements to List.
Converting to a list makes the data in the column easier for analysis as list holds the collection of items in PySpark , the data traversal is easier when it comes to the data structure with list. There are various ways by which we can convert a column element into List. In this article, we will try to analyze the various method used for conversion in detail.
Syntax:
The syntax are as follows:
b_tolist=b.rdd.map(lambda x: x[1])- b: The data frame used for conversion of the columns.
- .rdd: used to convert the data frame in rdd after which the .map() operation is used for list conversion.
(lambda x :x[1]):- The Python lambda function that converts the column index to list in PySpark.
Screenshot:

Working of Column to List in PySpark
This is a conversion operation that converts the column element of a PySpark data frame into list. The return type of a Data Frame is of the type Row so we need to convert the particular column data into List that can be used further for analytical approach. There are various methods that can be opt-out for the conversion that includes the looping of every element in the column and then putting it down to list.
The list in python is represented as Arrays. The elements are stored in a list are stored as the type of index that stores each and every element though. The elements are traversed via loops in the columns and stored at a given index of a list in PySpark. There can be various methods for conversion of a column to a list in PySpark and all the methods involve the tagging of an element to an index in a python list.
The list operation is easier to iterate, add and delete columns. so it is generally preferred to use the same.
Let’s check the creation and conversion method with some coding examples.
Examples
Let us see some examples of how PYSPARK COLUMN TO LIST operation works. Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:

Lets us check some of the methods for Column to List Conversion.
1. Using the Lambda function for conversion.
We can convert the columns of a PySpark to list via the lambda function .which can be iterated over the columns and the value is stored backed as a type list.
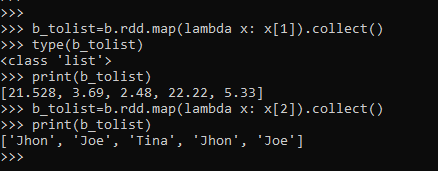
b_tolist=b.rdd.map(lambda x: x[1]).collect()
type(b_tolist)
print(b_tolist)The others columns of the data frame can also be converted into a List.
b_tolist=b.rdd.map(lambda x: x[2]).collect()
print(b_tolist)We can change the index and then the columns can be converted.
Screenshot:
2. Using the FlatMap function for list conversion.
The same conversion can be done using the Flat Map method that converts the columns into List.
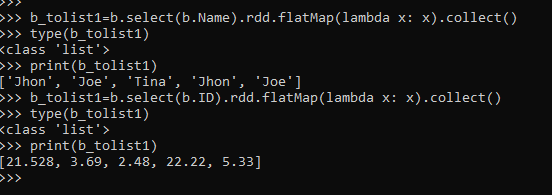
b_tolist1=b.select(b.Name).rdd.flatMap(lambda x: x).collect()
type(b_tolist1)
print(b_tolist1)
b_tolist1=b.select(b.ID).rdd.flatMap(lambda x: x).collect()
type(b_tolist1)
print(b_tolist1)This converts the column into List using the Flat Map operation.
Screenshot:
Even we can use the python inbuilt library also. The conversion can also be done by using the .toPandas() library. The panda’s library first converts it of the type <class ‘pandas.core.series.Series’>
That can be post used out for conversion using the list function of PySpark.
Let us check that with an example:
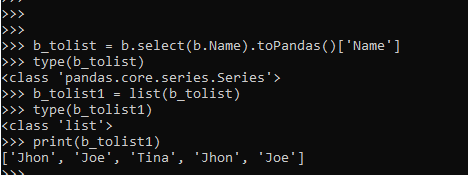
b_tolist = b.select(b.Name).toPandas()['Name']
type(b_tolist)
b_tolist1 = list(b_tolist)
type(b_tolist1)
print(b_tolist1)This is a column-to-list conversion via the Pandas method.
Screenshot:
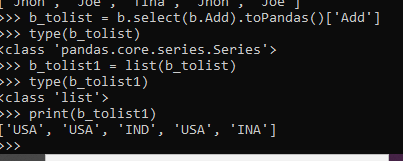
More columns can be done via the same.
b_tolist = b.select(b.Add).toPandas()['Add']
type(b_tolist)
b_tolist1 = list(b_tolist)
type(b_tolist1)
print(b_tolist1)Screenshot:
Note:
1. PySpark COLUMN TO LIST is a PySpark operation used for list conversion.
2. It convert the column to list that can be easily used for various data modeling and analytical purpose.
3. It allows the traversal of columns in PySpark Data frame and then converting into List with some index value.
4. It uses the function Map, Flat Map, lambda operation for conversion.
5. Conversion can be reverted back and the data can be pushed back to the Data frame.
Conclusion
From various examples and classifications, we tried to understand how this conversion from PySpark data frame column to list happens in PySpark and what are is use in the programming level.
We also saw the internal working and the advantages of converting the COLUMN TO LIST in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
We hope that this EDUCBA information on “PySpark Column to List” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

