Updated March 31, 2023

Introduction to PySpark Count
PySpark Count is a PySpark function that is used to Count the number of elements present in the PySpark data model. This count function is used to return the number of elements in the data. It is an action operation in PySpark that counts the number of Rows in the PySpark data model. It is an important operational data model that is used for further data analysis, counting the number of elements to be used. The count function counts the data and returns the data to the driver in PySpark, making the type action in PySpark. This count function in PySpark is used to count the number of rows that are present in the data frame post/pre-data analysis.
Syntax:
b.count()- b: The data frame created.
- count(): The count operation that counts the data elements present in the data frame model.
Output:
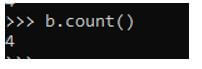
Working of Count in PySpark
- The count is an action operation in PySpark that is used to count the number of elements present in the PySpark data model. It is a distributed model in PySpark where actions are distributed, and all the data are brought back to the driver node. The data shuffling operation sometimes makes the count operation costlier for the data model.
- When applied to the dataset, the count operation aggregates the data by one of the executors, while the count operation over RDD aggregates the data final result in the driver. This makes up 2 stages in the Data set and a single stage with the RDD. The data will be available by explicitly caching the data, and the data will not be in memory.
Examples of PySpark Count
Different examples are mentioned below:
But, first, let’s start by creating a sample data frame in PySpark.
Code:
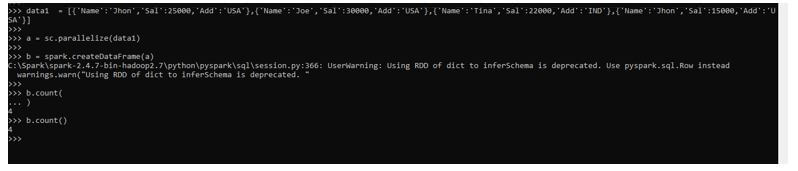
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains the Name, Salary, and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc.parallelize will be used for the creation of RDD with the given Data.
b = spark.createDataFrame(a)Post creation, we will use the createDataFrame method for the creation of Data Frame.
This is how the Data Frame looks.
b.show()Output:

Now let us try to count of a number of elements in the data frame by using the Dataframe.count () function. The counts create a DAG and bring the data back to the driver node for functioning.
b.count()This counts up the data elements present in the Data frame and returns the result back to the driver as a result.
Output:
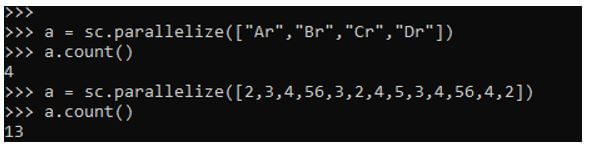
Now let’s try to count the elements by creating a Spark RDD with elements in it. This will make an RDD and count the data elements present in that particular RDD data model.
The RDD we are taking can be of any existing data type, and the count function can work over it.
a = sc.parallelize(["Ar","Br","Cr","Dr"])
a.count()Now let’s try to do this by taking the data type as Integer. This again will make an RDD and count the elements present in that. Note that all the elements are counted using the count function, not only the distinct elements but even if there are duplicate values, those elements will be counted as part of the Count function in the PySpark Data model.
a = sc.parallelize([2,3,4,56,3,2,4,5,3,4,56,4,2])
a.count()Output:
Conclusion
From the above article, we saw the working of Count in PySpark. From various examples and classifications, we tried to see how these counts are used in PySpark and what are is use at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same. We also saw the internal working and the advantages of Count Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark Count. Here we discuss the introduction, working of count in PySpark, and examples for better understanding. You may also have a look at the following articles to learn more –

