Updated April 4, 2023

Introduction to PySpark DataFrame
PySpark Data Frame is a data structure in Spark that is used for processing Big Data. It is an easy-to-use API that works over the distributed system for working over big data embedded with different programming languages like Spark, Scala, Python. It is an optimized way and an extension of Spark RDD API that is cost-efficient and a model and powerful tools for data operation over big data.
There are several ways of creating a data frame in Spark which we will discuss further and certain advantages like the table model which it follow up. We have can SQL-level operation with the help of Data Frame and it has a defined schema for working. In this article, we will try to analyze the various ways of using the PYSPARK Data Frame operation PySpark.
Let us try to see about PYSPARK Data Frame operation in some more detail.
Syntax for PySpark DataFrame
The syntax for PYSPARK Data Frame function is:
a = sc.parallelize(data1)
b = spark.createDataFrame(a)
b
DataFrame[Add: string, Name: string, Sal: bigint]a: RDD that contains the data over .
b: spark.createDataFrame(a) , the createDataFrame operation that works takes up the data and creates data frame out of it.
The return type shows the DataFrame type and the column name as expected or needed to be.
Screenshot:

Working on DataFrame in PySpark
Let us see how PYSPARK Data Frame works in PySpark:
A data frame in spark is an integrated data structure that is used for processing the big data over-optimized and conventional ways. It is easy to use and the programming model can be achieved just querying over the SQL tables. Several properties such as join operation, aggregation can be done over a data frame that makes the processing of data easier. It is an optimized extension of RDD API model. It is just like tables in relational databases which have a defined schema and data over this.
The data are in defined row and columnar format with having the column name, the data type, and nullable property.
Data Frames are distributed across clusters and optimization techniques is applied over them that make the processing of data even faster. The catalyst optimizer improves the performance of the queries and the unresolved logical plans are converted into logical optimized plans that are further distributed into tasks used for processing. We can perform various operations like filtering, join over spark data frame just as a table in SQL, and can also fetch data accordingly.
There are several ways of creation of data frame in PySpark and working over the model. Let’s check the creation and working of PySpark Data Frame with some coding examples.
Examples
Let us see some Examples of how PySpark Data Frame operation works:
Type 1: creating a sample data frame in PySpark.
From an RDD using the create data frame function from the Spark Session. It takes the RDD objects as the input and creates Data fame on top of it.
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains Name, Salary, and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc.parallelize will be used for creation of RDD with the given Data.
b = spark.createDataFrame(a)Post creation we will use the createDataFrame method for creation of Data Frame.
This is how the Data Frame looks.
b.show()Screenshot:

Type 2: Creating from an external file.
The spark. read function will read the data out of any external file and based on data format process it into data frame.
Df = Spark.read.text("path")The type of file can be multiple like:- CSV, JSON, AVRO, TEXT.
Sample JSON is stored in a directory location:
{"ID":1,"Name":"Arpit","City":"BAN","State":"KA","Country":"IND","Stream":"Engg.","Profession":"S Engg","Age":25,"Sex":"M","Martial_Status":"Single"},
{"ID":2,"Name":"Simmi","City":"HARDIWAR","State":"UK","Country":"IND","Stream":"MBBS","Profession":"Doctor","Age":28,"Sex":"F","Martial_Status":"Married"},
a.show()The spark.read.json(“path ”) will create the data frame out of it.
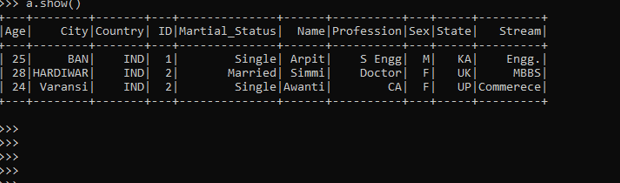
These are some of the Examples of PySpark Data Frame in PySpark.
Note:
1. PySpark Data Frame is a data structure in spark model that is used to process the big data in an optimized way.
2. PySpark Data Frame has the data into relational format with schema embedded in it just as table in RDBMS
3. PySpark Data Frame follows the optimized cost model for data processing.
4. PySpark Data Frame data is organized into Columns.
5. PySpark Data Frame as also lazily triggered.
6. PySpark Data Frame does not support the compile-time error functionality.
7. PySpark Data Frame uses the off-heap memory for serialization.
Conclusion
From the above article, we saw the working of Data Frame in PySpark. From various examples and classification, we tried to understand how this Data Frame function is used in PySpark and what are is use in the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of having Data Frame in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark DataFrame. Here we discuss the Introduction, syntax, Working of DataFrame in PySpark, and examples with code implementation. You may also have a look at the following articles to learn more –

