Updated April 4, 2023

Introduction to PySpark fillna
PySpark FillNa is a PySpark function that is used to replace Null values that are present in the PySpark data frame model in a single or multiple columns in PySpark. This value can be anything depending on the business requirements. It can be 0, empty string, or any constant literal. This Fill Na function can be used for data analysis which removes the Null values that sometimes can cause problems for data analysis and further operations.
The FillNa function will be used to replace the null values with an empty string, 0 values. The value can be used to replace the function of a single column value
In this article, we will try to analyze the various ways of using the PYSPARK FillNa operation PySpark. Let us try to see about PYSPARK FillNa in some more detail.
Syntax for PYSPARK FillNa
The syntax for PYSPARK FILLNA Function is:-
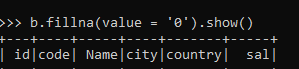
b.fillna(value ='0').show()Parameters:
- b: The data frame needed for PySpark operation.
- fillna: The fillNa function is used to fill up the null value with a certain value out of it.
- .show(): The function used for showing up the filled data.
Screenshot:-
Working of PySpark fillna
Let us see how PYSPARK FILLNA Operation works in PySpark:-
The Fill Na function finds up the null value for a given data frame in PySpark and then fills the value out of it that is passed as an argument. The value can be passed to the data frame that finds the null value and applies the value out of it.
The fillNa value replaces the null value and it is an alias for na.fill(), it takes up the value based on the and replaces the null values with the values associated. If the value is a dictionary then the value must be mapped from column name as the replacement value and the subset is ignored.
The second parameter takes up the optional list of column names to be considered. The column having the matching data type is taken and the one with unknown data types are ignored.
Let’s check the creation and working of the PySpark FILLNA Operation with some coding examples.
Example
Let us see some examples of how the PySpark FILLNA operation works:
We will start by creating a data frame by reading a CSV File that is present in a location that will be used for creating the data frame.
The spark.read.csv will be used to create the data frame out of it.
b = spark.read.options(header='true',inferSchema='true').csv("path\\sample.csv")
b.show()This contains the column name id, Name, code, city, country, and sal as the column name in the data frame. This CSV file has some null values embedded in it that will be used to fill the null value out of it.
Let’s check the data out of it:-
Screenshot:-
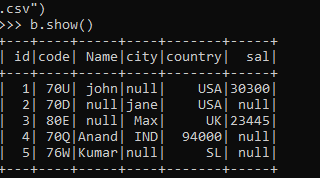
The null values are highlighted by the bold marked. That will be used to fill the null values out of it. This takes up the integer data type as the column value and fills the null value out of it.
b.fillna(value =0).show()Screenshot:
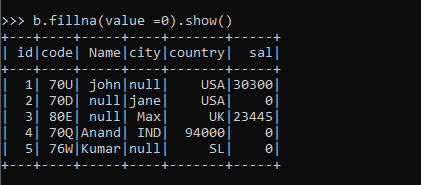
Here are important things to note that is the data type value with Integer are only replaced by the fillNa method, and if the value is given a string it will fill the string value NA column leaving the integer one.
b.fillna(value ='0').show()Screenshot:
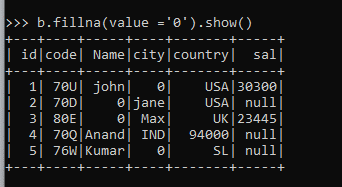
We can also manually define the subset value as the column name value whose null function needs to be Filled up by some value.
b.fillna(value ='0',subset =['Name']).show()This will just take the column value Name and fill the nulls out of it.
Screenshot:
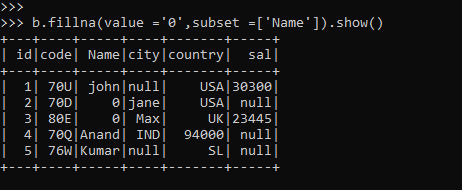
Only Name columns null values are filled and the rest of the other column null are left as it.
This subset matching purely works on the data type that is used for filling the null value out of it. If a column with another data type name is used it is skipped while filling up the value thereafter.
b.fillna(value ='0',subset =['Name','sal']).show()The column sal will be skipped in this case while filling up the value.
Screenshot:
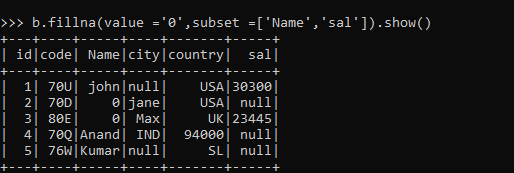
These are some of the Examples of FILLNA operations in PySpark.
Note:-
- PySpark FillNa is used to fill the null value in PySpark data frame.
- FillNa is an alias for na.fill method used to fill the null value.
- FillNa takes up the argument as the value that needs to be filling up the null value.
- PySpark FillNa can be applied to single or multiple columns in a data frame.
- FillNa ignores the column name with a different data type.
Conclusion – PySpark fillna
From the above article, we saw the working of FillNa in PySpark. From various example and classification, we tried to understand how this FillNa are used in PySpark and what are is used in the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of FillNa in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark fillna. Here we discuss the internal working and the advantages of FillNa in PySpark Data Frame and its usage for various programming purposes. You may also have a look at the following articles to learn more –

