Updated February 21, 2023

Definition of PySpark GitHub
PySpark GitHub is a process in PySpark that we are using for a specified time. For creating the PySpark GitHub user submits the application of spark by using apache. Drive module is used in the GitHub project which takes the application from the spark side. The PySpark driver will identify the application from the spark side. As per the program driver, it will identify the transformation which is present in the application.
What is PySpark GitHub?
Python module for PySpark GitHub will contain the apache spark definition of the ETL job which implements the best practices in the ETL job which we are running in production. We can submit the same by using the spark cluster by using the smart submit command, the same command we have found in the bin directory of the spark distributions. The zip package will contain the python module which was required for the ETL job. GitHub is available in every process of executor and each mode in the cluster.
We need to send the config file to the cluster which contains the json object which contains all the configuration parameters required to run the project on GitHub. The file of the PySpark GitHub project contains the application of spark which is executed in a driver process into the node of spark master. For using PySpark GitHub we need to install git bash in our system. We can install the same by downloading it from the git website. We can also use the py charm to set up the GitHub project.
At the time of working on the PySpark project, we need to import the module of PySpark in our project. We can import the PySpark model by using the import keyword. Also, we need to import the required libraries of the GitHub project.
PySpark GitHub Projects
We can download the GitHub project by using the git command. In the below project, we are downloading the dataset from Kaggle where we can download the dataset of transactions. We are defining online banking analysis. While developing the project we also need to download the dataset. After downloading the dataset, we need to clean the data.
Code:
git clone */pyspark-project.gitOutput:

After downloading the dataset we are checking the downloaded project files as follows. We can also use PySpark for executing the new cases in the dataset which we have downloaded. Basically, PySpark is a framework that was used to process large datasets as follows.
Code:
cd pyspark-project/Output:
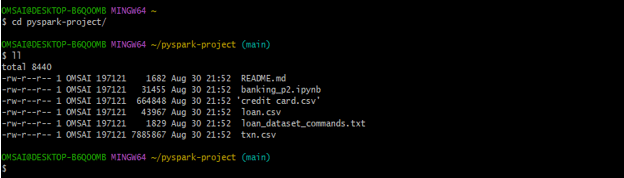
We can also check the data of project files, we are retrieving the data files as follows.
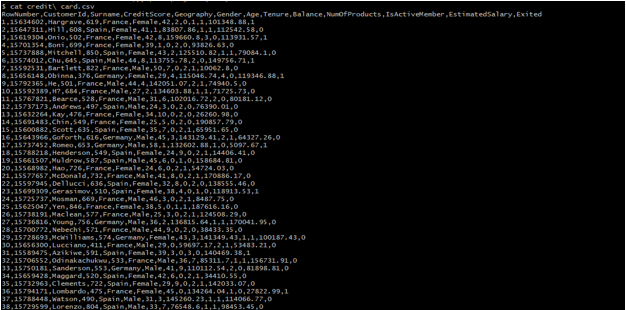
PySpark is a good language for performing the analysis and building the pipeline of machine learning it is also used to create the data platform ETL. PySpark is used anywhere when someone is dealing with big data. It is used for processing data which was large then data was distributed for managing large-scale tasks for gaining the insights of a business.
After cloning the project in the below example, we are defining the order by operation on data.
Code:
import PySpark
from PySpark. Sql import Spark Session
gith = SparkSession.builder.appName("pysparkdf").getOrCreate()
func = gith.read.option ("header", "true").csv("spark2.csv")
func.orderBy ("AUTHOR_ID").show()Output:
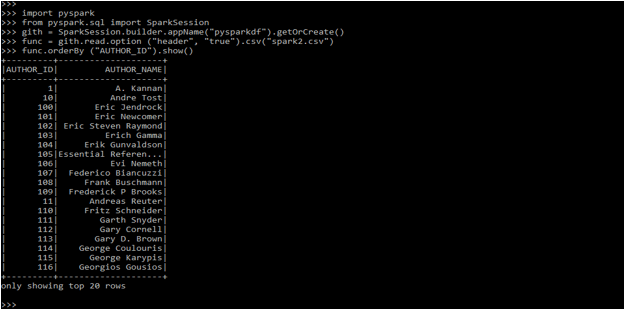
PySpark GitHub Functions
There are multiple functions of PySpark GitHub in python. The same function we are using for data frames also. To use PySpark GitHub function first we need to import the package of PySpark as follows.
Code:
import pyspark
from pyspark.sql import SparkSessionOutput:

In the below example, we are using the show function to display the data from the gitlab csv file as follows.
Code:
func = spark.read.option("header", "true").csv("spark1.csv")
func.show()Output:
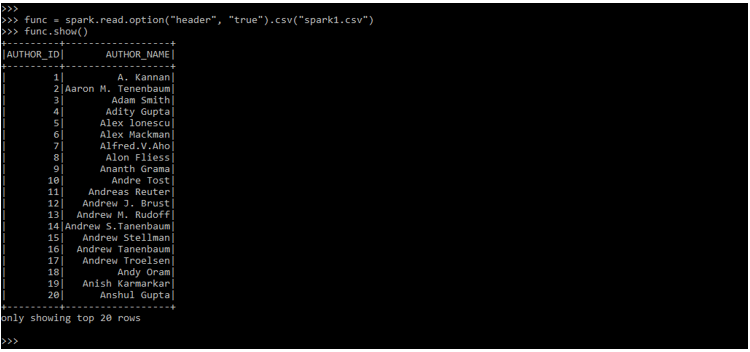
We can print the schema by using the print schema function. In the below example we can see that it will show two columns as follows.
Code:
func = spark.read.option("header", "true").csv("spark1.csv")
func.printSchema()Output:

The below example shows the select function. The select function helps us to display the selected column from all the data frames, we have to pass the column name as follows.
Code:
func = spark.read.option("header", "true").csv("spark1.csv")
func.select('AUTHOR_ID').show(10)Output:
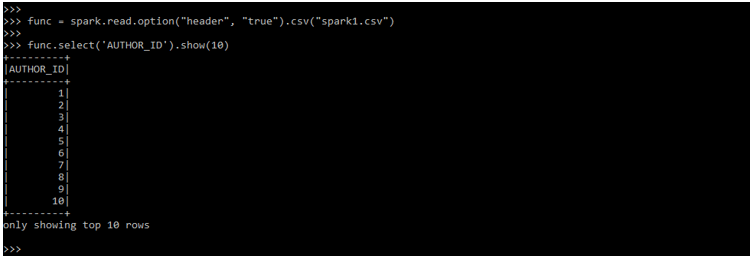
The pyspark group by function is used to collect the data from the data frame and allows us to perform the aggregate function in the data which was grouped. This is a common operation in the group by clause.
Code:
func = spark.read.option("header", "true").csv("spark1.csv")
func.groupBy("AUTHOR_ID", "AUTHOR_NAME").count().show()Output:
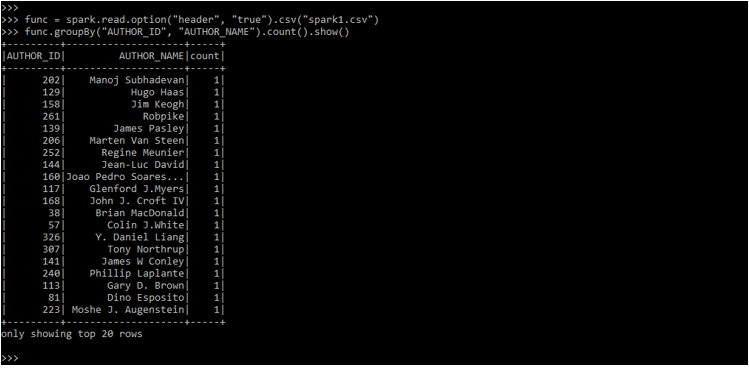
The order by function in pyspark github is used to sort all the data frames as per the column which we have used. It will be sorting data frames as per the values of a column.
Code:
func = spark.read.option("header", "true").csv("spark1.csv")
func.orderBy ("AUTHOR_ID").show()Output:
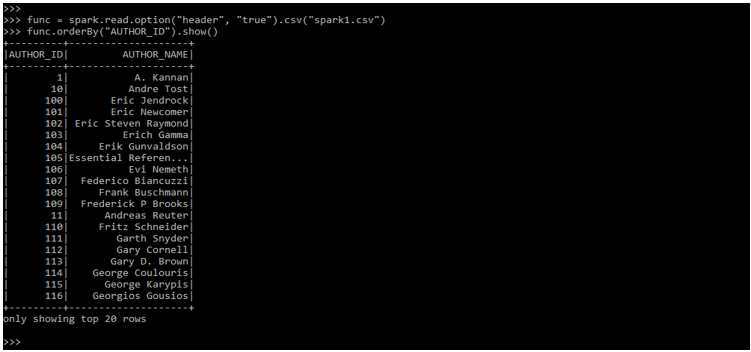
Examples
In the below example, we are cloning the PySpark simple project. We are cloning the project by using the git clone command. After cloning the project, we can see that all the files of the project are copied in a specified directory.
Code:
git clone */pyspark-examples.git
cd pyspark-examples.gitOutput:
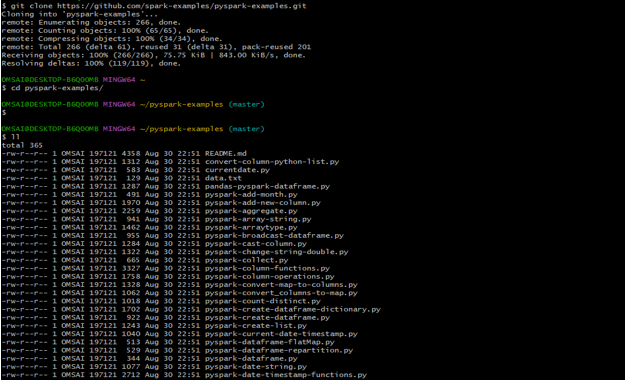
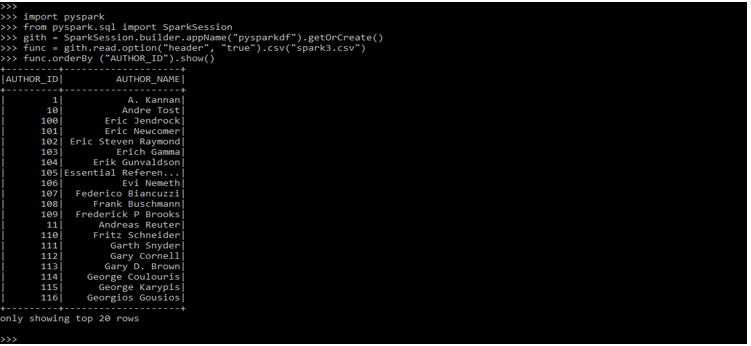
After cloning the project in the below example, we are defining the order by operation on data.
Code:
import pyspark
from pyspark.sql import SparkSession
gith = SparkSession.builder.appName("pysparkdf").getOrCreate()
func = gith.read.option ("header", "true").csv("spark3.csv")
func.orderBy ("AUTHOR_ID").show()Output:
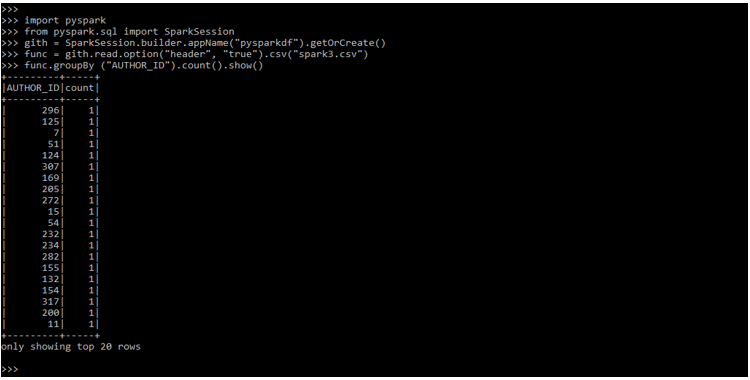
In the below example, we are defining the group by operation on data.
Code:
import pyspark
from pyspark.sql import SparkSession
gith = SparkSession.builder.appName("pysparkdf").getOrCreate()
func = gith.read.option("header", "true").csv("spark3.csv")
func.groupBy ("AUTHOR_ID").count().show()Output:
Key Takeaways
- GitHub transformation requires the shuffling of data between partitions and the transformation of the stage boundary. The scheduler will be creating an execution pan of PySpark GitHub.
- Basically, there are two types of transformation available in GitHub. The catalyst is defining the query optimizer of the spark integral planner.
FAQ
Below given are the FAQs mentioned.
Q1. How do we download PySpark GitHub project?
Answer: At the time of using GitHub project we can download the same from anywhere we want and we can download and run the same project easily.
Q2. How many types of transformation are available in PySpark GitHub?
Answer: There are mainly two types of transformation available in PySpark GitHub i.e. wide transformation and narrow transformation. The wide transformation is used in many cases.
Q3. Which library do we need to use at the time of running PySpark GitHub project?
Answer: We need to use and import the PySpark library at the time of running PySpark GitHub project.
Conclusion
At the time of working on PySpark project, we need to import the module of PySpark in our project. PySpark GitHub is a process by which we are using the PySpark for a specified time. For creating the PySpark GitHub users need to submit the application of spark by using apache.
Recommended Articles
This is a guide to PySpark GitHub. Here we discuss the Definition, What is PySpark GitHub, projects, functions, examples with code implementation, and Key Takeaways for better understanding. You may also have a look at the following articles to learn more –

