Updated April 18, 2023

Introduction to PySpark GroupBy Agg
PySpark GroupBy is a Grouping function in the PySpark data model that uses some columnar values to group rows together. This works on the model of grouping Data based on some columnar conditions and aggregating the data as the final result. It is an Aggregate function that is capable of calculating many aggregations together, This Agg function takes up several aggregate functions at one time and the grouped data record is then aggregated using the value from that. The functions can be like Max, Min, Sum, Avg, etc.
Syntax:
The syntax for the PySpark GroupBy AGG function is:
from pyspark.sql.functions import sum,avg,max,min,mean,count
b.groupBy("Name").agg(sum("Sal").alias("sum_salary"),max("Sal").alias("MaximumOfSal")).show()- B: The Data frame to be used for Group By Agg function.
- GroupBy (“ColName”): The Group By Function that needs to be used for Grouping of Data.
- Agg: The Aggregate Function can take multiple agg functions together and the result can be computed at once.
Screenshot:
![]()
Working of Aggregate with GroupBy in PySpark
The GroupBy function follows the method of Key value that operates over PySpark RDD/Data frame model.
The data with the same key are shuffled using the partitions and are brought together being grouped over a partition in PySpark cluster. The shuffling operation is used for the movement of data for grouping. The same key elements are grouped and the value is returned. The aggregate function in Group By function can be used to take multiple aggregate functions that compute over the function and the result is then returned at once only. The function can be sum, max, min, etc. that can be triggered over the column in the Data frame that is grouped together.
The function applies the function that is provided with the column name to all the grouped column data together and result is returned.
Examples
Let’s start by creating a sample data frame in PySpark.
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains the Name, Salary, and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc.parallelize will be used for the creation of RDD with the given Data.
b = spark.createDataFrame(a)Post creation we will use the createDataFrame method for the creation of Data Frame.
This is how the Data Frame looks.
b.show()Screenshot:

Let’s first start by importing the necessary imports needed.
from pyspark.sql.functions import sum,avg,max,min,mean,countLet’s apply the Group By function with several Agg over it and compute it at once to analyze the result.
b.groupBy("Name")
<pyspark.sql.group.GroupedData object at 0x00000238AAAAD3C8>Screenshot:
![]()
This will group Data based on Name as the SQL.group.groupedData.
We will use the aggregate function sum to sum the salary column grouped by Name column.
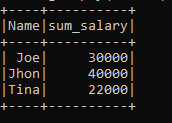
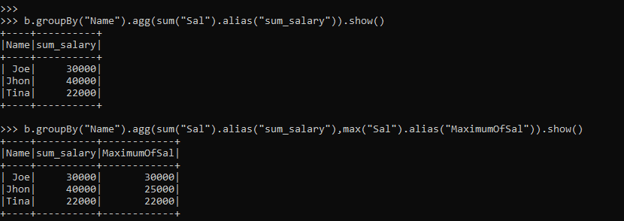
b.groupBy("Name").agg(sum("Sal").alias("sum_salary")).show()This will return the sum of the salary column grouped by the Name column. This is one function that we applied and analyzed the result.
The salary of Jhon, Joe, Tine is grouped and the sum of Salary is returned as the Sum_Salary respectively.
Screenshot:
The Multiple Agg Function Example
Here we will take more than one different Agg function over the column value and analyze the result out of it.
b.groupBy("Name").agg(sum("Sal").alias("sum_salary"),max("Sal").alias("MaximumOfSal"),min("Sal").alias("MinOfSal")).show()The three agg function used here is SUM SALARY, MIN SAL and the MAX of the SAL, this will be computed at once and the result is computed in a separate column.
Output Analysis:
Screenshot:

These column values and the AGG function can be changed as per the analysis requirement.
Screenshot:
These are some of the Examples of PySpark GroupBy AGG in PySpark.
Note:
1. PySpark GroupBy Agg is a function in the PySpark data model that is used to combine multiple Agg functions together and analyze the result.
2. PySpark GroupBy Agg can be used to compute aggregation and analyze the data model easily at one computation.
3. PySpark GroupBy Agg converts the multiple rows of Data into a Single Output.
4. PySpark GroupBy Agg includes the shuffling of data over the network.
Conclusion
From the above article, we saw the working of GroupBy AGG in PySpark. From various examples and classifications, we tried to understand how this GroupBy AGG is used in PySpark and what are is used in the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of GroupBy AGG in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark GroupBy Agg. Here we discuss the introduction, syntax, and working of Aggregate with GroupBy in PySpark along with different examples and code implementation. You may also have a look at the following articles to learn more –

