Updated April 1, 2023

Introduction to PySpark join two dataframes
PYSPARK JOIN is an operation that is used for joining elements of a data frame. The joining includes merging the rows and columns based on certain conditions. There are certain methods in PySpark that allows the merging of data in a data frame. Joining a data frame makes the analysis sometimes easier for data analysts.
The methods look up for the elements in the data frame based on a condition or column over which the join operation needs to be done and perform the operation returning the new joined data frame. The joining of data frames is an important part of data analysis as it allows the user to easily work over multiple data sources and fetch the value out of them.
This article will try to analyze the various ways of using the PySpark join two dataframes.
Let us try to see about PySpark join two dataframes in some more details
The syntax for PySpark join two dataframes
The syntax for PySpark join two dataframes function is:-
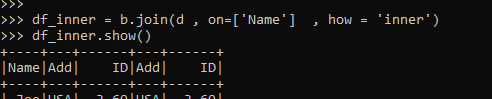
df = b.join(d , on=['Name'] , how = 'inner')b: The 1st data frame to be used for join.
d: The 2nd data frame to be used for join further.
The Condition defines on which the join operation needs to be done.
df: The data frame received.
Working of PySpark join two dataframes
Let us see somehow the JOIN OPERATION FOR DATAFRAME function works in PySpark:-
The joining of a data frame in PySpark is based on some condition that forms out a rule over which the join function needs to be done. The join function takes up certain parameters, which include the first one over the column condition on which the join needs to happen, then the second includes the type of join needed. This type decides the data type that needs to be chosen for joining purposes.
There are several join conditions that can be used for joining a data frame, be it Inner join, Outer Join, Left Join, Right Join. These types of join first look for the condition over the column and then selects the data that falls over that condition as a result.
This is how JOINS between data frames are used in PySpark.
Example of PySpark join two dataframes
Let us see some examples of how the PYSPARK ORDERBY function works:-
Let us start by creating a PySpark Data Frame.
A data frame of Name with the concerned ID and Add is taken for consideration, and a data frame is made upon that.
Code:
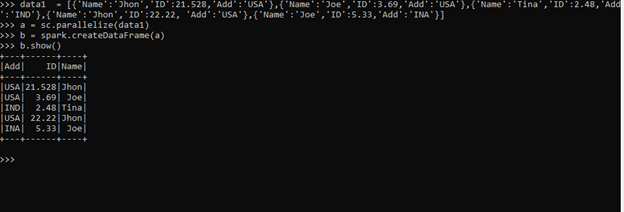
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]The sc.parallelize method is used for creating an RDD from the data.
a = sc.parallelize(data1)The spark.createDataFrame method is then used for the creation of DataFrame.
b = spark.createDataFrame(a)Screenshot:
Let us create one more data frame for joining.
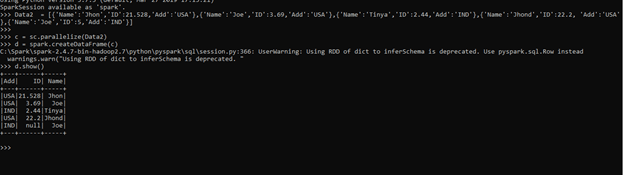
Data2 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tinya','ID':2.44,'Add':'IND'},{'Name':'Jhond','ID':22.2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'IND'}]The sc.parallelize method is used for creating an RDD from the data.
c = sc.parallelize(Data2)The spark.createDataFrame method is then used for the creation of the Data Frame.
d = spark.createDataFrame(c)Screenshot:
We will use the two data frames for the join operation of the data frames b and d that we define.
Let us start by joining the data frame by using the inner join.
There are several ways we can join data frames in PySpark. Let us start by doing an inner join.
df_inner = b.join(d , on=['Name'] , how = 'inner')
df_inner.show()Screenshot:
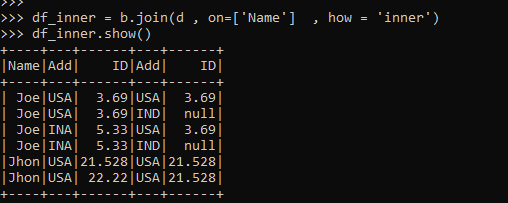
The output shows the joining of the data frame over the condition name. The condition joins the data frames matching the data from both the data frame.
The condition can be on other columns also, which does the joining, and the data is then returned based on the values it got.
df_inner = b.join(d , on=['Add'] , how = 'inner')
df_inner.show()Here the join condition is on column ADD. The process is the same just the column joining condition is changed.
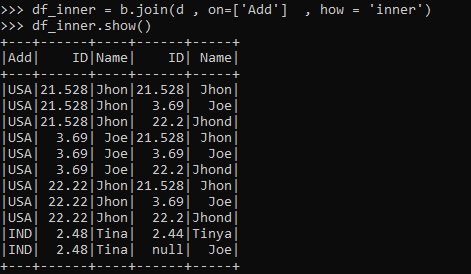
If we want to select all the data from the data frame, we can use the JOIN type as OUTER. This outer join selects all the data frames from both the Data frame and performs a JOIN operation over the same.
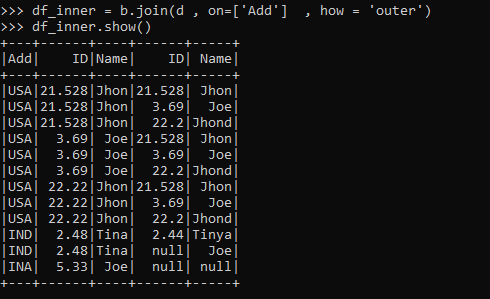
df_inner = b.join(d , on=['Add'] , how = 'outer')
df_inner.show()df_inner = b.join(d , on=['Name'] , how = 'outer')
df_inner.show()The join operation can also be over multiple columns and over the different columns also from the data frame used.
The left and right joins are also a way of selecting data from specific data frames in PySpark.
The left is the data fetching from the LEFT table and the RIGHT being the one from the right table based on column values.
df_inner = b.join(d , on=['Add'] , how = 'left').show()df_inner = b.join(d , on=['Add'] , how = 'Right').show()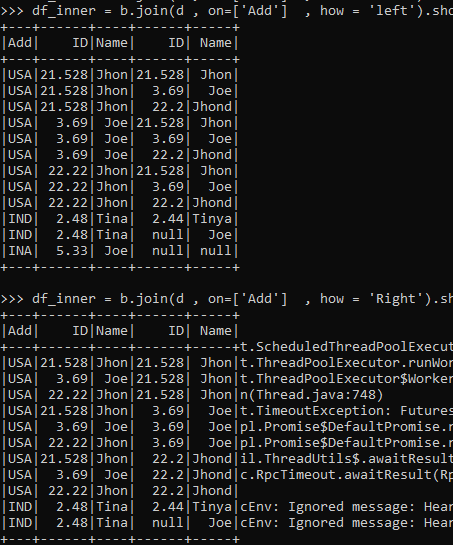
The data frames are joined, and the result is then stored in a new data frame.
From the above example, we saw the use of the JOIN Operation with PySpark
Conclusion
From the above article, we saw the working of JOIN OPERATION in PySpark. We tried to understand how this JOIN function works in PySpark and what is used at the programming level from various examples and classification. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of JOINING DATAFRAMES in PySpark Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark join two dataframes. Here we discuss the introduction, working and examples of joining two dataframes in PySparak. You may also have a look at the following articles to learn more –

