Updated April 6, 2023

Introduction to PySpark Left Join
PYSPARK LEFT JOIN is a Join Operation that is used to perform a join-based operation over the PySpark data frame. This is part of join operation which joins and merges the data from multiple data sources. It combines the rows in a data frame based on certain relational columns associated.
A left join returns all records from the left data frame and matches the records from the right data frame, the result is null if there is no match from the right side of the data frame. This is used for data analysis by merging the data frame together and including the data from the left table. All the records from the left data frame is published using the left join even if there is no match from the right data frame.
In this article, we will try to analyze the various ways of using the LEFT JOIN operation.
Syntax for PySpark Left Join
The syntax are as follows:
df_inner = b.join(d , on=['ID'] , how = 'left').show()Parameters:
b: The First data frame
d: The Second data frame used.
on: The condition over which the join operation needs to be done.
how: The condition over which we need to join the Data frame.
df_inner: The Final data frame formed
Screenshot:
![]()
Working of Left Join in PySpark
The join operations take up the data from the left data frame and return the data frame from the right data frame if there is a match.
Null is returned if there is no match of data in the right data frame.
The data from the left data frame is returned always while doing a left join in PySpark data frame.
The data frame that is associated as the left one compares the row value from the other data frame, if the pair of row on which the join operation is evaluated is returned as True, the column values are combined and a new row is returned that is the output row for the same.
If there is a no match case null is associated with the right data frame in each case and the data frame is returned with null values embedded in it.
Let’s check the creation and working of PySpark LEFT JOIN with some coding examples.
Example
Let us see some examples of how PySpark LEFT JOIN operation works. Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:

data2 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhons','ID':7.5, 'Add':'USA'},{'Name':'Jode','ID':6.3,'Add':'INA'}]A sample data is created with Name , ID, and ADD as the field
c = sc.parallelize(data2)RDD is created using sc.parallelize
d = spark.createDataFrame(c)Created Data Other Data Frame using Spark.createDataFrame.
Screenshot:

Let’s do a LEFT JOIN over the column in the data frame. We will do this join operation over the column ID that will be a left join taking the data from the left data frame and only the matching data from the right one.
df_inner = b.join(d , on=['ID'] , how = 'left').show()Analysis of data output shows that the data from the left data frame is put together and the one the matches the right column is collected. We can see null is returned once there is no matching of data from the right data frame.
This null can be ignored also taking only the matched data.
Screenshot:
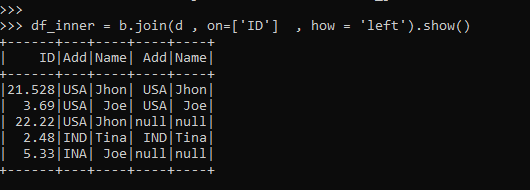
All the data from the Left data frame is selected and data that matches the condition and fills the record in the matched case in Left Join.
The operation is performed on Columns and the matched columns are returned as result. Missing columns are filled with Null.
Note:
1. PySpark LEFT JOIN is a JOIN Operation in PySpark.
2. It takes the data from the left data frame and performs the join operation over the data frame.
3. It involves the data shuffling operation.
4. It returns the data form the left data frame and null from the right if there is no match of data.
5. PySpark LEFT JOIN references the left data frame as the main join operation.
Conclusion
From the above article, we saw the working of LEFT JOIN in PySpark. From various examples and classifications, we tried to understand how this LEFT JOIN function works in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of LEFT JOIN in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark Left Join. Here we discuss the introduction, syntax, and working of along with examples and code implementation. You may also have a look at the following articles to learn more –

