Updated April 1, 2023

Introduction to PySpark LIKE
PySpark LIKE operation is used to match elements in the PySpark data frame based on certain characters that are used for filtering purposes. We can filter data from the data frame by using the like operator. This filtered data can be used for data analytics and processing purpose. It can be used with single or multiple conditions to filter the data or can be used to generate a new column of it. This can also be used in the PySpark SQL function, just as the like operation to filter the columns associated with the character value inside.
Syntax of PySpark LIKE
Given below is the syntax mentioned:
b.filter(col('Name').like("%Jhon%")).show()- b: The data frame used.
- filter: The filter operation used for filtering the data.
- like: The Like operator is used with the character value.
The parameter used by the like function is the character on which we want to filter the data.
Output:

Working of PySpark LIKE
Given below is the working:
- The LIKE operation is a simple expression that is used to find or manipulate any character in a PySpark SQL or data frame architecture.
- This takes up two special characters that can be further used up to match elements out there.
- These are called as the wildcard operator in Like.
- The percent(%) sign represents one, zero or multiple characters.
- The underscore(_) represents a single character.
- The value before the percent makes it available for the data, which starts with that character. The data is then filtered, and the result is returned back to the PySpark data frame as a new column or older one.
- The value written after will check all the values that end with the character value.
Examples of PySpark LIKE
Given below are the examples of PySpark LIKE:
Start by creating simple data in PySpark.
Code:
data1 = [{'Name':'Jhon','ID':21.528,'Add':'U SA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name , ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Output:

Let us try to use the like function in the Data frame.
Code:
b.filter(col('Name').like("%Jhon%")).show()This filters the data based on column name Jhon, and the data is then used for the purpose of data analysis. The column is given as the column name with the character name provided within the like clause.
Output:
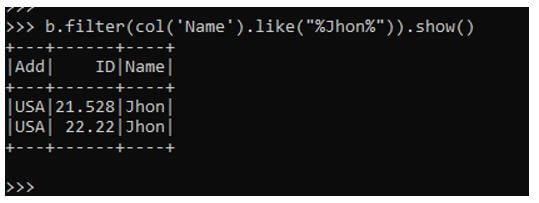
The same can be applied to multiple columns, also providing the result further.
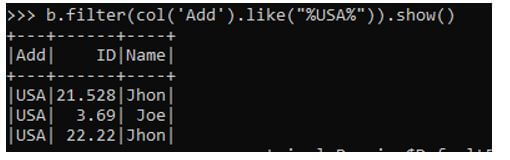
Let us try to filter the column based on ADD using the filter column function.
Code:
b.filter(col('Add').like("%USA%")).show()Output:
Code:
b.filter(col('Name').like("%J%")).show()Output:
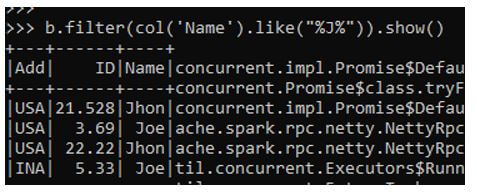
Let us see this by the _ operator.
This selects the Name that starts with J filling the spaces that satisfies the data and filters the data accordingly.
The same spaces can be filled accordingly by adding the underscores to the like operator in PySpark.
Code:
b.filter(col('Name').like("J__")).show()Output:
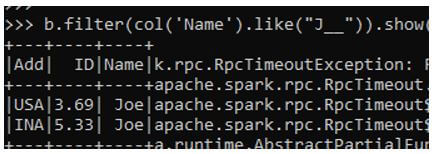
This will look for the Name starting with J upto 3 places.
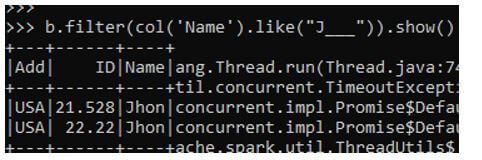
Code:
b.filter(col('Name').like("J___")).show()The output will print the Name starting with J and will select upto 3 decimal places.
Output:
The same can be used with the PySpark SQL model by creating a temporary table and then using the SQL statements.
Conclusion
From the above article, we saw the working of the LIKE Function. From various examples and classification, we tried to understand how this LIKE function works in columns and what are is use at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same. We also saw the internal working and the advantages of LIKE in Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark LIKE. Here we discuss the introduction, working of LIKE PySpark and examples for better understanding. You may also have a look at the following articles to learn more –

