Updated March 31, 2023

Introduction to PySpark list to dataframe
PYSPARK LIST TO DATAFRAME is a technique in a Data frame that converts a List in PySpark to a Data frame. This conversion allows the conversion that makes the analysis of data easier in PySpark. A list is PySpark is used to store multiple items in a single variable. They are ordered and allow duplicate values; the conversion of the list to data frame allows the data analysis easier in the PySpark environment. The conversion of List to data frame makes the data optimized and operation easier over-analysis.
Data frames are organized into name columns which are optimized. Several data techniques can be applied to elements that are converted into a data frame in PySpark.
In this article we will try to analyze the various ways of using the LIST TO DATAFRAME operation PySpark.
Let us try to see about LIST TO DATAFRAME in some more details.
The syntax for PySpark list to dataframe
The syntax for LIST TO DATAFRAME function is:-
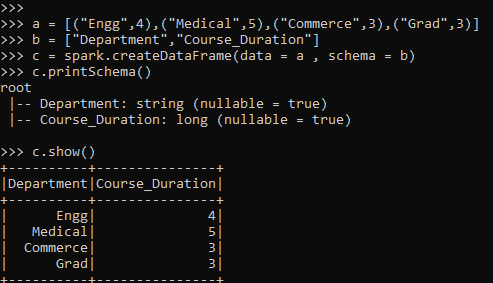
a = [("Engg",4),("Medical",5),("Commerce",3),("Grad",3)]
b = ["Department","Course_Duration"]
c = spark.createDataFrame(data = a , schema = b)
c.printSchema()
c.show()- a: The List included that will be used further for conversion.
- b: The Schema used.
- c: spark.createDataframe to be used for the creation of dataframe. This takes up two-parameter the one with data and schema that will be created.
Screenshot:-
Working of PySpark list to dataframe
Let us see how LIST TO DATAFRAME works:
The list is an ordered collection that stores the multiple items in a single variable. They are used to create and store data in PySpark. They are ordered and allow duplicate values. Generally, list items handle data, and data is iterated over for analysis of data. Sometimes the data iteration becomes costly while dealing with a large dataset; for this, the conversion of List to data frame makes it easier for data analysis.
List are converted into Data frame by passing the schema and using the spark functionality to create a data frame. There are many ways to create a data frame from the list in the PySpark framework. This makes the data analysis easier, and we several operations can be done with the data using the PySpark model.
Data frames are optimized in PySpark, and iterating the data is easier, so is the operation. A simple method spark.createdataframe accepts two parameters, the data and the schema, which applies optimization techniques with the data and creates a data frame out of it.
Let’s check the creation and working of PySpark LIST TO DATA FRAME with some coding examples.
Example of PySpark list to dataframe
Let us see some examples of how the PySpark LIST TO DATA FRAME operation works:-
Let’s start by creating a simple List in PySpark.
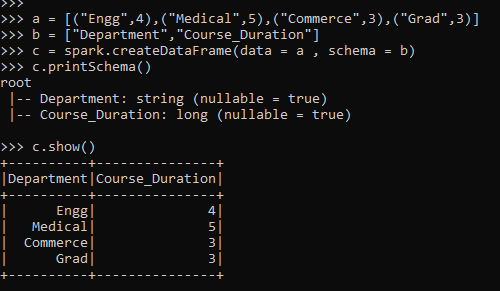
a = [("Engg",4),("Medical",5),("Commerce",3),("Grad",3)]Let’s create a Schema that will be used for the creation of a data frame.
b = ["Department","Course_Duration"]The Spark.createDataFrame takes up a two-parameter, which accepts the data and the schema together and results out the data frame out of it.
c = spark.createDataFrame(data = a , schema = b)The Schema is just like the table schema that prints the schema passed.
c.printSchema()Let’s check the data using the data frame .show() prints the converted data frame in the PySpark data model.
c.show()Screenshot:-
Let us see one more method for the creation of a data frame in PySpark.
This uses the Struct Type for defining the Schema. The schema can be put into spark.createdataframe to create the data frame in the PySpark. Let’s import the data frame to be used.
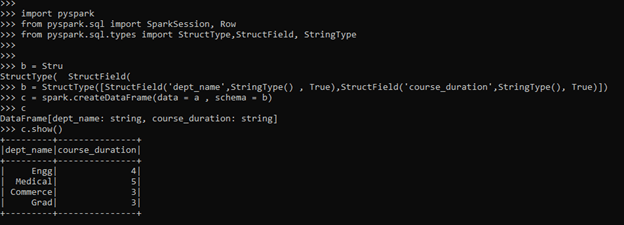
import pyspark
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StructType,StructField, StringType
b = StructType([StructField('dept_name',StringType() , True),StructField('course_duration',StringType(), True)])
c = spark.createDataFrame(data = a , schema = b)
c DataFrame[dept_name: string, course_duration: string]
c.show()Screenshot:-
The same can be done using the Row Type as List. Again, the list elements are inserted as the Row Type, which can be further used for the creation of the dataframe in PySpark.
Let us check with some examples:-
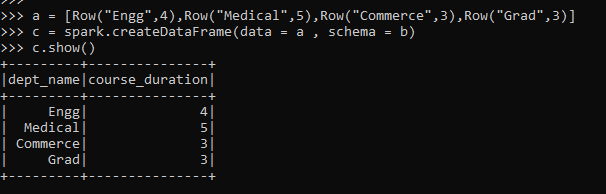
a = [Row("Engg",4),Row("Medical",5),Row("Commerce",3),Row("Grad",3)]
c = spark.createDataFrame(data = a , schema = b)
c.show()Screenshot:-
There is a method by which a list can be created to Data Frame in PySpark.
These are some of the Examples of LIST TO DATAFRAME in PySpark.
Note:
- LIST TO DATAFRAME is used for conversion of the list to dataframe in PySpark.
- It makes the data analysis easier while converting to a dataframe.
- It can handle huge data loads also while conversion in Data frame.
- It can be converted by multiple methods in the PySpark environment.
Conclusion
From the above article, we saw the working of LIST TO DATAFRAME FUNCTION in PySpark. From various examples and classification, we tried to understand how this LIST TO DATAFRAME function works in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of LIST TO DATAFRAME in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark list to dataframe. Here we discuss the internal working and the advantages of list of dataframe in PySpark and its usage in various programming. You may also have a look at the following articles to learn more –

