Updated July 10, 2023

Introduction to PySpark Orderby
PySpark Orderby is a spark sorting function that sorts the data frame / RDD in a PySpark Framework. It is used to sort one more column in a PySpark Data Frame… By default, the sorting technique used is in Ascending order. The orderBy clause returns the row in a sorted Manner guaranteeing the total order of the output. You can use the OrderBy function with a single column and multiple columns in OrderBy. It takes two parameters, Asc for ascending and Desc for Descending order.
This article will analyze the various ways of using the Map Partitions operation PySpark. But first, let us see about PySpark Map Partitions in more detail.
Syntax of PySpark Orderby:
The syntax for the PySpark Orderby function is:
b.orderBy(("col_Name")).show()- orderBy: The Order By Function in PySpark accepts the column name as the input.
- b: The Data Frame where the operation needs to be done.
ScreenShot:
![]()
Working of Orderby in PySpark
Let us see somehow the Orderby function works in PySpark:
PySpark OrderBy is a sorting technique used in the PySpark data model to order columns. The sorting of a data frame ensures an efficient and time-saving way of working on the data model. This is because it saves so much iteration time, and the data is more optimized functionally.
The order by doesn’t change the physical table of the data frame, or any further changes don’t happen; it just puts works on the data where data is sorted based on column and criteria needed.
It creates a global flag with a sorting key that compares the data with the data element inside the columns. The order by column takes up single and multiple columns where the sorting can be done. The default sorting function that can be used is ASCENDING order by importing the function desc, and sorting can be done in DESCENDING order.
It takes the parameter as the column name that decides the column name under which the ordering needs to be done.
This is how the use of ORDERBY in PySpark.
Examples of PySpark Orderby
Let us see some examples of how the PySpark Orderby function works:
Let’s start by creating a PySpark Data Frame.
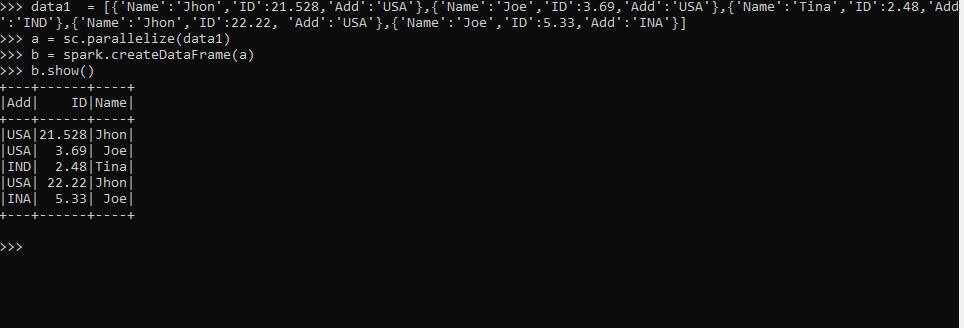
We consider a data frame that contains Name, the corresponding ID, and Add, and create a data frame based on it.
Code:
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]The sc.parallelize method creates an RDD from the data.
a = sc.parallelize(data1)The spark.createDataFrame method is then used for the creation of DataFrame.
b = spark.createDataFrame(a)
b.show()Output:
Let’s try doing the Order By operation.
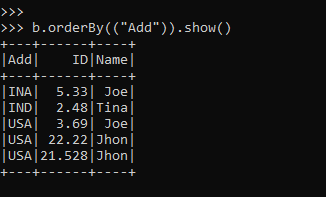
The output in the data frame is first the Add now; we will try to sort the element using the order by operation.
b.orderBy(("Add")).show()Sorting the column in ascending order enables further analysis.
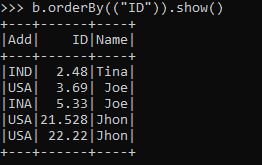
The same can be done over other columns, such as ID and Name.
b.orderBy(("ID")).show()Output:
b.orderBy(("Add")).show()Output:
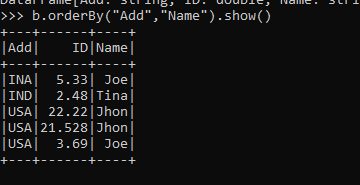
By passing them as parameters, you can perform the orderBy operation over multiple columns.
Code:
b.orderBy("Add","Name").show()Output:
You can use the orderBy function with the Spark SQL function by creating a temporary Table of the DataFrame. You can use the Temp Table with Spark. SQL function, where we can use the Order By Function.
We can use the various aggregate method from the order by function with the ordered data used. The order by default orders the element in Ascending order that can be further ordered up in descending order by using the DESC keyword. In the case of multiple-column order, the sorting is performed based on the value of the first column, and within each value of the first column, further sorting is done based on the second column. We can also order the data based on all the columns in the data frame. From the above example, we saw the use of the orderBy function with PySpark.
Conclusion
From the above article, we saw the working of Orderby in PySpark. We attempted to understand how the Orderby function works in PySpark and its usage at the programming level by analyzing various examples and classifications. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same. We also saw the internal working and the advantages of Orderby in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us understand the function more precisely.
Recommended Articles
We hope that this EDUCBA information on “PySpark Orderby” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

