Updated April 3, 2023

Introduction to PySpark partitionBy
PYSPARK partitionBy is a function in PySpark that is used to partition the large chunks of data into smaller units based on certain values. This partitionBy function distributes the data into smaller chunks that are further used for data processing in PySpark. For example, DataFrameWriter Class functions in PySpark that partitions data based on one or multiple column functions.
Using partitionBy improves the performance of the data processing and makes the analysis of data easier. The data can be partitioned in memory or disk-based on the requirement we have for data. This article will try to analyze the various method used in PARTITIONBY with the data in PySpark. But, first, let us try to see about PARTITIONBY in some more detail.
Syntax
The syntax for PYSPARK partitionBy function is:-
b.write.option("header",True).partitionBy("Name").mode("overwrite").csv("path")- b: The data frame used.
- write.option: Method to write the data frame with the header being True.
- partitionBy: The partitionBy function to be used based on column value needed.
- mode: The writing option mode.
- csv: The file type and the path where these partition data need to be put in.
Screenshot:
![]()
Working of PySpark partitionBy
Let us see somehow PARTITIONBY operation works in PySpark:-
The partitionBy operation works on the data in PySpark by partitioning the data into smaller chunks and saving it either in memory or in the disk in a PySpark data frame. This partition helps in better classification and increases the performance of data in clusters. The partition is based on the column value that decides the number of chunks that need to be partitioned on.
Part files are created that hold the data with the partitioned column name as the folder name in the PySpark. The partitioning allows the data access faster as it will have the data organized way, i.e. in a separate folder and file by which the traversal will be comparatively easier.
All the data are segregated in a common folder with the same data in the same file location needed for columns; this partition can partition the data on single columns as well as multiple columns of a PySpark data frame. Thus, the performance of queries is improved by using the PySpark partition while dealing with huge chunks of data in PySpark.
A success file and a crc file are created to execute the files in the folder given successfully.
Let’s check the creation and working of the partitionBy function with some coding examples.
Example of PySpark partitionBy
Let us see some examples of how partitionBy operation works:-
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name , ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:

This creates the data frame with the column name as Name, Add, and ID.
Let’s try to partition the data based on Name and store it back in a csv file in a folder.
b.write.option("header",True).partitionBy("Name").mode("overwrite").csv("\tmp")This partitions the data based on Name, and the data is divided into folders. The success and success. crc folder is created with the folder name and the data inside the folder.
The option header true keeps up the header function with it, and the headers are within it. The mode defines the mode under which the data needs to be written. It can be overwritten, append, etc. The column name is written on which the partition needs to be done.
This creates a folder with the name of the folder, and the data is inside that folder.
Screenshot:

Screenshot:
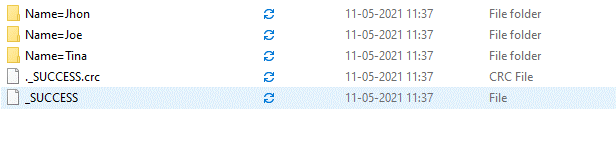
For multiple columns, the partition By can be used that creates the folder inside the folder, and the data is stored in that.
b.write.option("header",True).partitionBy("Name","Add").mode("overwrite").csv("/tmp/")This will create a folder inside the folder with the name followed by the Add folder.
Screenshot:-
![]()


The files are written back in the folder and then can be used for further data analytics purposes.
These are some of the Examples of PARTITIONBY FUNCTION in PySpark.
Note:
- partitionBy is a function used to partition the data based on columns in the PySpark data frame.
- PySpark partitionBy fastens the queries in a data model.
- partitionBy can be used with single as well multiple columns also in PySpark.
- partitionBy stores the value in the disk in the form of the part file inside a folder.
- partitionBy allows the data movement and shuffling of data around the network.
Conclusion
From the above article, we saw the working of PARTITIONBY in PySpark. Then, from various examples and classifications, we tried to understand how this PARTITIONBY operation happens in PySpark and what are is used at the programming level.
We also saw the internal working and the advantages of PARTITIONBY in the PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark partitionBy. Here we discuss the working of PARTITIONBY in PySpark with various examples and classifications. You may also have a look at the following articles to learn more –

