Updated February 21, 2023

Definition of PySpark Pipeline
PySpark pipeline acts as an estimator; the pipeline consists of stages sequence either as a transformer or estimator. At the time of calling pipeline.fit method, the stages are executed in order. Suppose stage is estimator, then estimator.fit method is called onto the input dataset for fitting a model. Then the transformer method is used to transform the dataset as an input for the next stage PySpark pipeline.
Introduction to PySpark Pipeline
The pyspark machine learning library builds the modeling capabilities into the distributed environment. The spark package is an API of the high level built onto the data frames. This API will help us to tune the pipeline of machine learning. The PySpark machine learning will refer to the MLlib data frame based on the pipeline API. The pipeline machine is a complete workflow combining multiple machine learning algorithms; multiple steps are required for learning and processing data and require sequence from the algorithms. A pipeline defines the ordering and stages ML process.
How to Use Dataset in PySpark Pipeline?
Pyspark machine learning is picking the space primarily due to increased user data. The new API will introduce the powerful concept of the pipeline where different stages of the ML will work as a single entity, and it will be considered a machine learning workflow. It contains a set of stages; each stage either contains an estimator or a transformer. All stages are running in sequence, and the input of the data frame is transformed at the time of passing the same through every stage.
The below steps show how we can use the dataset as follows. To use this, first, we need to install the pyspark module in our system. We can install the same pip command.
- In the first step, we install the PySpark package using the pip command. We can also use another command to install the same in the package on our system. The below example show install the PySpark package as follows.
Code:
pip install pyspark
- After installing the PySpark package we are login into the python shell to import the package of PySpark .
Code:
python
- After logging into the python shell, we are now importing the required packages by using the import keyword as follows. We import the row, pipeline, and tokenizer packages from the PySpark module.
Code:
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
from pyspark.sql import Row
- After importing the module in this step, we define the LDoc variable, label systeminfo, and buildingid column.
Code:
LDoc = Row ("BuildingID", "SystemInfo", "label")
- After defining the variable in this step, we are creating the function name as parse document as follows.
Code:
def parseDocument (line):
py_val = [str(x) for x in line.split (',')]
if (py_val[3] > py_val[2]):
hot = 1.0
else:
hot = 0.0
- After creating the function now in this step we are loading the dataset file name as pyspark.txt are as follows.
data = loadtxt ('pyspark.txt', delimiter = ",")
- After loading the data set we are creating the context of a data frame are as follows.
Code:
name = [('ABC',1), ('PQR',2), ('XYZ',3)]
id = sc.parallelize (name)
map = id.map()
df = sqlContext.createDataFrame(map)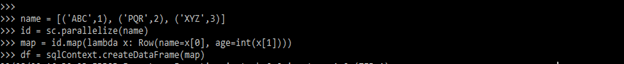
Pyspark Pipeline Data Exploration
PySpark is a tool created by a community of apache spark; it is allowed to work with an RDD. It offers to work with the API of python. PySpark is a name engine that was used to realize cluster computing. To define data exploration, we must follow the steps below.
- Import the module of PySpark.
- Processing of data
- Build the processing pipeline of data.
- Evaluate and train the model.
- Tuning of hyperparameter
We can also use the CSV file to explore the data in the PySpark pipeline. A dataset is insignificant, and we can say the computation will take time. Pyspark processes the data, and the performance of PySpark is good compared to other machine learning libraries. In the below example, we are extracting the data from the CSV file as follows. We are importing the SQLContext by using the pyspark.sql package as follows.
Code:
from pyspark.sql import SQLContext
web = " "
from pyspark import SparkFiles
sc.addFile (web)
sqlContext = SQLContext (sc)Output:
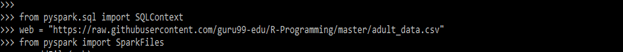

We can also extract the data which was input given by the user. Below examples shown to extract the data as per input given by the user are as follows. In the below example we have importing the PySpark model are as follows.
Code:
import pyspark
from pyspark import SparkContext
sc = SparkContext()
num = sc.parallelize([13, 21, 35, 46])
num.take (13)Output:

Examples
Below are the different examples:
Example #1
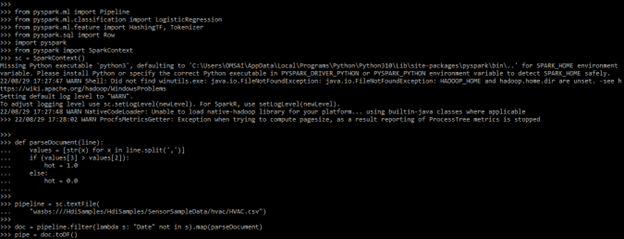
In the below example, we are importing the module name as PySpark and defining ROW as follows.
Code:
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
from pyspark.sql import Row
import pyspark
from pyspark import SparkContext
sc = SparkContext()
def parseDocument(line):
values = [ ]
if () :
hot = 1.0
else:
hot = 0.0
pipeline = sc.textFile()
doc = pipeline.filter()
pipe = doc.toDF()Output:
Example #2
In the below example we are retrieving data from the user input as follows.
Code:
from pyspark.sql import Row
from pyspark.sql import SQLContext
import pyspark
from pyspark import SparkContext
sc =SparkContext()
sqlContext = SQLContext (sc)
pipeline = [('ABC', 19), ('PQR', 25), ('XYZ', 32)]
con = sc.parallelize(pipeline)
ppl = con.map()
contest = sqlContext.createDataFrame(ppl)
contest.printSchema()Output:
Key Takeaways
- In the PySpark pipeline, the transformer is a feature of abstraction which was learned from the models. The PySpark pipeline component will add, delete, or update the existing features from the data set.
- Every transform into the PySpark pipeline contains the transform method which was called while executing the pipeline.
FAQ
Given below is the FAQ mentioned:
Q1. What is the use of a transformer in PySpark pipeline?
The transformer is a component of the PySpark pipeline. The transformer is an abstraction which was including the features of the transformer and modules, it is implementing the method of transform.
Q2. What is the use of an estimator in the PySpark pipeline?
The estimator is a component of the PySpark pipeline. An estimator is abstracting the concept of a learning algorithm. An estimator is implementing the method name as fit.
Q3. Why we are using pipelines in PySpark?
In ML it’s very common to run an algorithm in a sequence and learn it from the data.
Conclusion
PySpark pipeline acts as an estimator, the pipeline consists of stages sequence either as a transformer or estimator. Pyspark API will help us to create and tune the pipeline of machine learning. The pyspark machine learning will be referring to the MLlib data frame which is based on the pipeline API.
Recommended Articles
This is a guide to PySpark Pipeline. Here we discuss the introduction and how to use the dataset in PySpark Pipeline along with data exploration and examples. You may also have a look at the following articles to learn more –

