Updated February 22, 2023

Introduction to PySpark RDD
The following article provides an outline for PySpark RDD. We know that pyspark is a high-level application that includes driver programming; with the help of this program, we can execute the user’s main function and the different parallel operations on the cluster. So here, the main programming class is a resilient distributed dataset. RDD is nothing but the collection of different cluster nodes that can be executed in parallel.
Key Takeaways
- Parallel execution makes efficient and fast processing of elements.
- It allows us to tolerate the fault during the execution of RDD.
- It does not quickly compute the computational result of the RDD element.
- We cannot transform individual elements on a dataset in RDD.
What is PySpark RDD?
RDD represents Resilient Distributed Dataset; these components run and work on different hubs to resemble handling on a group. RDDs are unchanging components, and that implies once you make an RDD, you can’t transform it. RDDs are issue lenient, too; subsequently, if there should be an occurrence of any disappointment, they recuperate consequently. You can apply various procedures on these RDDs to accomplish a specific errand. RDDs are made by beginning with a record in the Hadoop document framework (or some other Hadoop-upheld document framework) or a current Scala assortment in the driver program and changing it. Clients may request that Spark continue an RDD in memory, permitting it to be reused effectively across similar activities. At last, RDDs consequently recuperate from hub disappointments.
PySpark RDD Operations
Let’s see the operation of RDD as follows:
Basically, there are two types of operation in RDD:
1. Transformation
These activities accept an RDD as information and produce one more RDD as a result. When a change is applied to an RDD, it returns another RDD; the first RDD continues as before and, in this way, is permanent. After applying the change, it makes a Directed Acyclic Graph or DAG for calculations and finishes in the wake of applying any activities on it. This is the explanation they are called apathetic assessment processes.
2. Actions
These are sorts of activities that are applied on an RDD to deliver a solitary worth. These techniques are applied to a resultant RDD and produce non-RDD esteem, eliminating the lethargy of the change of RDD.
Now let’s see an example of an RDD operation as follows:
Before that, we must ensure the setup of RDD, which means installation, so first, we need to install the pyspark on our local machine with the help of the below command.
pip install pysparkAfter installation, we need to initialize the sparkcontext like the below code as follows:
Code:
from pyspark import SparkContext
sc_obj = SparkContext.getOrCreate()Let’s see a different operation as follows:
1. .collect() Action
It is used to return the list of all the elements, and it is a very simple and easy method to display the element of RDD.
Code:
element_rdd = sc.parallelize([4,5,6,7])
print(element_rdd.collect())In the above example, first, we initialize the RDD element, and in the second line, we print that element. The end result of the above implementation is shown in the below screenshot.
Output:
![]()
2. .count() Action
It is used to return how many elements are present in RDD; by using this operation, we can verify the RDD element.
Code:
element_rdd_count = sc.parallelize([4,5,6,7])
print(element_rdd_count.count())Output:
![]()
3. .first() Action
With the help of this operation, we can return the first element of RDD. This is helping us to verify the exact element of RDD.
Code:
element_rdd_first = sc.parallelize([4,5,6,7])
print(element_rdd_count.first())Output:
![]()
4. .take() Action
If we want to return the specified element, that means n number of elements from RDD, then we can use this operation.
Code:
element_rdd_take = sc.parallelize([4,5,6,7])
print(element_rdd_count.take(2))Output:
![]()
Similarly, we can implement other operations as per our requirements.
Creating PySpark RDD
Let’s see how we can create pyspark RDD as follows:
Two methods RDDs load an external dataset or a distributed data set. Here we will see the example of RDD creation with the help of parallelizing () function.
Code:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PySpark creation") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
rdd_df = spark.sparkContext.parallelize([(10, 20, 30, 'XYZ'),
(40, 50, 60, 'ABC'),
(70, 80, 90, 'EFG')]).toDF(['No1', 'No2', 'No3','No4'])
Rdd_df.show()Explanation:
- In the above code, we can see the parallelized implementation of RDD; here, we try to create different columns with different values, as shown in the above code.
- The result of the above implementation is shown in the below screenshot.
Output:
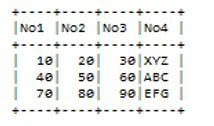
In the same way, we can create RDD using createDataFrame(), read and load function, etc.
PySpark RDD – Features
Let’s see the features of RDD as follows.
- Memory Computation: PySpark RDD provides distributed memory features instead of stable storage, so compared to the disk, it provides fast computation.
- Lazy Evolution: Lazy Evolution means it does not compute results quickly, or we can say that it does not start the execution as well as waiting for an action to be triggered.
- Fault Tolerant: If any failure occurs in RDD, it re-computes the input dataset from the original dataset.
- Immutability: Whenever required, we can easily retrieve created data.
- Partitioning: We know that RDD collects large-size data; because of this, we cannot store all data in one node. We need to store them in different partitions.
- Persistence: In RDD, we need to optimize, or we can save the evaluation, so this is one of the very good features to reduce computation complexity.
FAQ
Given below are the FAQ mentioned:
Q1. Why do we use RDD Spark?
Answer:
It allows us to store the object across the node, which means shareable between different jobs.
Q2. What is RDD?
Answer:
RDD is nothing but the Resilient Distributed Dataset as well as it is nothing but the user-facing API.
Q3. How many types of RDD?
Answer:
Actions and Transformation are the two types of RDD.
Conclusion
In this article, we are trying to explore PySpark RDD. In this article, we saw the different types of Pyspark RDD and the uses and features of these Pyspark RDD. Another point from the article is how we can perform and set up the Pyspark RDD.
Recommended Articles
This is a guide to PySpark RDD. Here we discuss the introduction, operations, PIP install PySpark, features, and FAQ. You may also have a look at the following articles to learn more –

