Updated February 21, 2023

Introduction to PySpark Read CSV
Pyspark read CSV provides a path of CSV to readers of the data frame to read CSV file in the data frame of PySpark for saving or writing in the CSV file. Using PySpark read CSV, we can read single and multiple CSV files from the directory. PySpark will support reading CSV files by using space, tab, comma, and any delimiters which are we are using in CSV files.
Overview
Data frame in apache spark will be defined as a distributed collection, and we can consider as data is organized by using named columns. Data frame is equivalent to the table in a relational database or the data frame of python language. The Data frame is constructed using a wide array of sources and in the structured data files.
Apache PySpark provides the CSV path for reading CSV files in the data frame of spark and the object of a spark data frame for writing and saving the specified CSV file. Multiple options are available in pyspark CSV while reading and writing the data frame in the CSV file. We are using the delimiter option when working with pyspark read CSV. The delimiter is used to specify the delimiter of column of a CSV file; by default, pyspark will specifies it as a comma, but we can also set the same as any other delimiter type.
How to Use PySpark to Read CSV data?
We can use single and multiple CSV files in PySpark for reading. We need to follow the below sreps to use the file data. First, we need to install PySpark in our system.
- In the below example, we are installing the PySpark in our system using the pip command as follows.
Code:
pip install pyspark
- After installing the pyspark module in this step we are login in python shell as follows.
Code:
python
- After login in python shell, we are importing the required packages which was we need to read the CSV files. We are importing the spark session, pipeline, row, and tokenizer package as follows.
Code:
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession
from pyspark.ml.feature import Tokenizer
from pyspark.sql import Row
- After importing the module in this step we are defining the variable to read the CSV file as PY.
Code:
py = SparkSession.builder.appName ('Pyspark read csv').getOrCreate ()
- After defining the variable in this step we are loading the CSV name as pyspark as follows.
Code:
read_csv = py.read.csv('pyspark.csv')
- In this step CSV file are read the data from the CSV file as follows.
Code:
rcsv = read_csv.toPandas()
rcsv.head()
Pyspark Read Multiple CSV Files
By using read CSV, we can read single and multiple CSV files in a single code. To read the multiple CSV files, we need to give the multiple file name while defining the path of the CSV file. In the below example, we are using two files as follows.
Code:
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession
spark_csv = SparkSession.builder.appName('Pyspark read multiple csv').getOrCreate()
path_csv = ['authors.csv', 'authors.csv']
file_csv = spark_csv.read.csv()
df_csv = file_csv.toPandas()
df_csv.head()
df_csv.tail()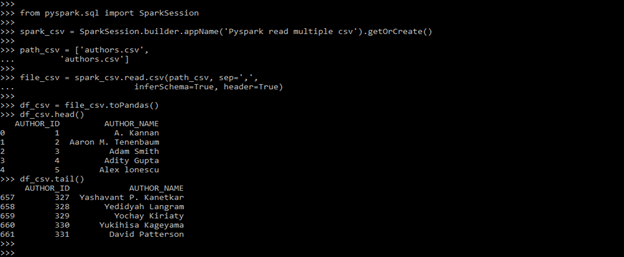
In the below example we are reading three files in single code as follows. We are using three different file as follows.
Code:
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession
spark_csv = SparkSession.builder.appName('Pyspark read multiple csv').getOrCreate()
path_csv = [spark1.csv', spark2.csv', 'spark3.csv']
file_csv = spark_csv.read.csv()
df_csv = file_csv.toPandas()
df_csv.head()
df_csv.tail()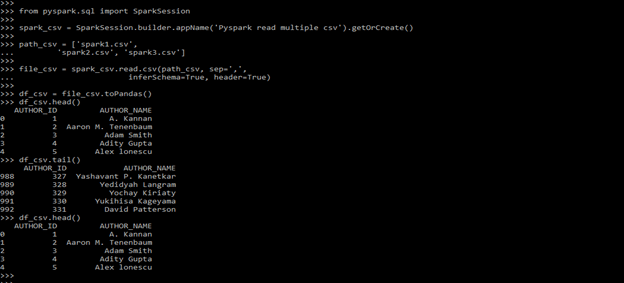
Pyspark Read Multiple Customs
At the time of creating the data frame, by using pyspark, we can specify the custom structure by using struct type and class name as the struct field. Struct type is a collection of a struct field that was used to define the name of a column. The below example shows pyspark read multiple customs as follows.
Code:
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
custom_spark = SparkSession.builder.master ("local[1]") \
.appName ('SparkByExamples.com') \ .getOrCreate()
student = [("AB", "", "CD", 25), ("PQ", "QR", "", 15), ("XY", "", "YZ", 35) ]
stud_schema = StructType ([ \
StructField ("stud_fname", StringType (), True), \
StructField ("stud_mname", StringType (), True), \
StructField ("stud_lname", StringType (), True), \
StructField ("stud_id", IntegerType (), True) \ ])
stud = custom_spark.createDataFrame (data = student, schema = stud_schema)
stud.printSchema()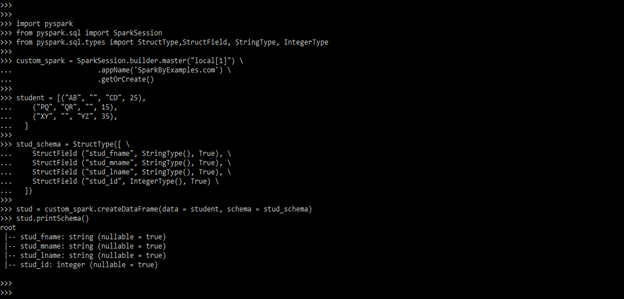
Pyspark Read Directory
We can also read all the CSV files from the specified directory. For reading all CSV files from the specified directory, we are using the “*” symbol. In the below example, we are keeping two files in the directory as follows.
Code:
from pyspark.sql import SparkSession
spark_csv = SparkSession.builder.appName ('Read all').getOrCreate()
all_csv = spark_csv.read.csv()
read_all = all_csv.toPandas()
read_all.head()
read_all.tail()
The below example shows PySpark read directory. We are using putting three files in a specified directory as follows.
Code:
from pyspark.sql import SparkSession
spark_csv = SparkSession.builder.appName ('Read all').getOrCreate()
all_csv = spark_csv.read.csv()
read_all = all_csv.toPandas()
read_all.head()
read_all.tail()
read_all.head()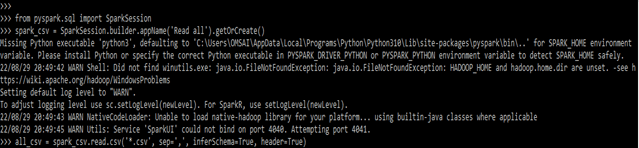
Examples
Below are the different examples as follows:
Example #1
In this example we are using a single CSV file.
Code:
from pyspark.sql import SparkSession
single = SparkSession.builder.appName('Pyspark read csv').getOrCreate()
single_csv = single.read.csv()
rcsv = single_csv.toPandas()
rcsv.head()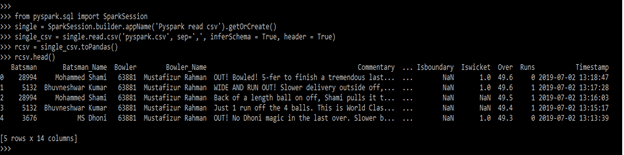
Example #2
Below example shows PySpark spark read CSV as follows. We are using two CSV files.
Code:
from pyspark.sql import SparkSession
two_csv = SparkSession.builder.appName ()
path_two = ['spark1.csv', 'spark2.csv']
file_two = two_csv.read.csv (path_two, sep=',')
df_two = file_two.toPandas()
df_two.head()
df_two.tail()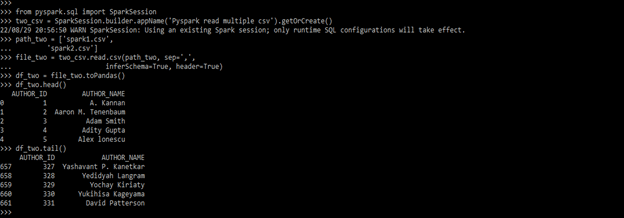
Key Takeaways
- We are using multiple options at the time of using PySpark read CSV file. Infer schema options is telling the reader to infer data types from source files.
- We can use it on single as well as multiple files, also we can read all CSV files.
FAQ
Given below is the FAQ mentioned:
Q1. Why are we using PySpark read CSV?
Answer: Basically the use of it is to read specified CSV file. By using spark we can read single as well as multiple CSV files also we can read all CSV files.
Q2. What is the use of delimiter in PySpark read CSV?
Answer: This option is used to specify the delimiter of a column from the CSV file by default it is comma.
Q3. What is the use of header parameters in PySpark ?
Answer: The header parameter is used to read first line of file which was we have defined in our code.
Conclusion
Multiple options are available in PySpark CSV while reading and writing the data frame in the CSV file. Pyspark reads CSV, providing a path of CSV to the reader of the data frame to read CSV files in the data frame of PySpark for saving or writing in the CSV file.
Recommended Articles
This is a guide to PySpark Read CSV. Here we discuss the introduction and how to use PySpark to read CSV data along with different examples. You may also have a look at the following articles to learn more –

