Updated April 15, 2023

Introduction to PySpark rename column
PYSPARK RENAME COLUMN is an operation that is used to rename columns of a PySpark data frame. Renaming a column allows us to change the name of the columns in PySpark. We can rename one or more columns in a PySpark that can be used further as per the business need. There are several methods in PySpark that we can use for renaming a column in PySpark. It is an action that is applied with the data frame in PySpark.
Data frames in PySpark are immutable collections, so the renamed data frame is a new data frame; every time a column is renamed, a new data frame is created. In this article, we will try to analyze the various method used for renaming columns in PySpark. Let us try to see about PYSPARK RENAME COLUMN in some more detail.
Syntax
The syntax for the PYSPARK RENAME COLUMN function is:-
c = b.withColumnRenamed("Add","Address")
c.show()- b: The data frame used for conversion of the columns.
- c: The new PySpark Data Frame.
- withcolumnRenamed: The function used to Rename the PySpark DataFrame columns taking two parameters, the one with the existing column and the one with a new one.
Screenshot:
![]()
Working of PySpark rename column
Let us see somehow RENAME COLUMN operation works in PySpark:-
PySpark comes out with various functions that can be used for renaming a column or multiple columns in the PySpark Data frame. Renaming the columns allows the data frame to create a new data frame, and this data frame consists of a column with a new name. There are various methods by which we can rename the column taking the parameters from the older column one to one with a new column.
The renamed columns from the data frame have a new memory allocation in Spark memory as the data frame is immutable so that the older data frame will have the name of the column as the older one only. The functions lookup for the column name in the data frame and rename it once there is a column match.
After matching the columns, a new data frame is created with the new name of the desired columns with the data and other schemas as defined.
Let’s check the creation and renaming of the column method with some coding examples.
Example of PySpark rename column
Let us see some Example of how the PYSPARK RENAME COLUMN operation works:-
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:

Let us try to rename some of the columns of this PySpark Data frame.
1. Using the withcolumnRenamed() function .
This is a PySpark operation that takes on parameters for renaming the columns in a PySpark Data frame. The first parameter gives the column name, and the second gives the new renamed name to be given on. Let’s check this with an example:-
c = b.withColumnRenamed("Add","Address")
c.show()This renames the column ADD to Address, and the result is stored in the new data frame.:-
Screenshot:
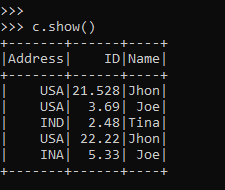
The same can be used to rename multiple columns in a PySpark Data frame.
c = b.withColumnRenamed("Add","Address").withColumnRenamed("ID","Card No")
c.show()Screenshot:
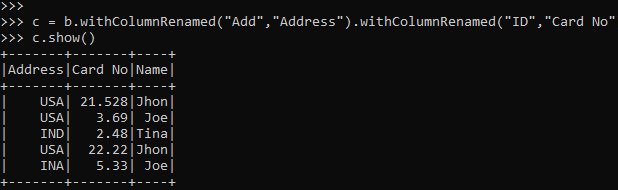
2. The select operation with .alias() function can be used to rename to columns in PySpark data frame. Let’s check this with an example:-
c = b.select(col("Add").alias("Address"))
c.printSchema()Screenshot:
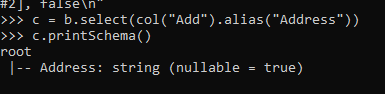
3. We can also write a custom PySpark logic and loop it with the columns in a data frame that can be used to rename all the columns at once.
Let’s check that with one example and understand it’s working.
rename_col = [f"{e.upper()}_updated" for e in b.columns]The method defined.
This method can be passed on the data frame, and it returns a new data frame as the output.
c = b.toDF(*rename_col)
c.show()This converts the column to the upper case and then adds up a new name renaming the columns.
Screenshot:
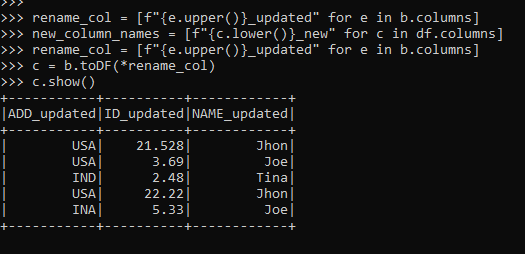
These are some of the Examples of PYSPARK RENAME COLUMN conversion in PySpark.
Note:
- RENAME COLUMN is an operation that is used to rename columns in the PySpark data frame.
- RENAME COLUMN creates a new data frame with the new column name as per need.
- RENAME COLUMN can rename one as well as multiple PySpark columns.
- RENAME COLUMN can be used for data analysis where we have pre-defined column rules so that the names can be altered as per need.
- PySpark RENAME COLUMN is an action in the PySpark framework.
Conclusion
From the above article, we saw the conversion of RENAME COLUMN in PySpark. From various examples and classification, we tried to understand how this RENAMING OF COLUMNS of PySpark data frame happens in PySpark and what are uses at the programming level.
We also saw the internal working and the advantages of RENAMING OF COLUMNS in PySpark Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to the PySpark rename column. Here we discuss the working and the advantages of RENAMING OF COLUMNS in PySpark Data Frame. You may also have a look at the following articles to learn more –

