Updated April 18, 2023
Introduction to PySpark Sort
PySpark Sort is a PySpark function that is used to sort one or more columns in the PySpark Data model. It is a sorting function that takes up the column value and sorts the value accordingly, the result of the sorting function is defined within each partition, The sorting order can be both that is Descending and Ascending Order. By default, the sorting is in ascending Order. The Sort function is used for data analysis as the data returned is in an order that is defined as per requirement.
This function can be used for data analysis purposes as it sorts the data in the order needed. In this article, we will try to analyze the various ways of using the PYSPARK Sort operation PySpark.
Let us try to see about it in some more detail.
Syntax:
The syntax for this function is:
b = spark.createDataFrame(a)
b.sort("Name","Sal").show()The sort function is used with the columns name in Data Frame, The column name can be single or multiple based on the sorting requirement.
B: The Data frame to be used.
Screenshot:
Working of Sort in PySpark
This function takes up the sorting algorithm to sort the data based on input columns provided. It takes up the column value and sorts the data based on the conditions provided. The sort condition can be ascending or descending depends on the condition value provided.
The columns values are checked accordingly with the corresponding values and the data is sorted up. It can take up a single column value as well as the multiple column values sorting the data accordingly over. It is a multiphase process so shuffling of data is done while sorting the data. It doesn’t repartition the data and keeps the current partitions only.
PySpark has the concept of Eliminate Sort function that is basically an optimization technique that is used, it Eliminates the Sort function that has no effect over the final operation that makes the operation less expensive while sorting the data in the PySpark model. Let’s check the creation and work with some coding examples.
Examples
Let us see some examples of how the operation works. Let’s start by creating a sample data frame in PySpark.
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains the Name, Salary, and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc. parallelize will be used for the creation of RDD with the given Data.
b = spark.createDataFrame(a)Post-creation we will use the createDataFrame method for the creation of Data Frame.
This is how the Data Frame looks.
b.show()Screenshot:

Let us try using the sort operation and analyze the further report.
b.sort("Name").show()Screenshot:
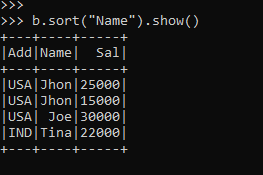
The column names provided sort the data in the data frame accordingly and the data is then returned further.
We can also have multiple columns to sort the data and here from the result, we will try to analyze now how this mapping generally works.
So here there are two names as Jhon with the salary ass 25000, 15000 in the Sal Column. So if we will use the sort function with Sal column also it will sort the data accordingly.
Code:
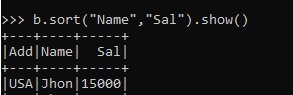
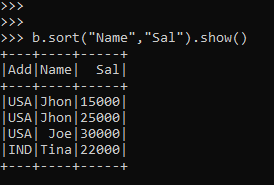
b.sort("Name","Sal").show()Here we can see that the Sal is now Sorted in Ascending order by Sorting it with the Name column also.
Screenshot:
The default sorting pattern is ASC and we can define the pattern as ASC and DESC.
Let’s check how we can manually pass this up over the pattern.
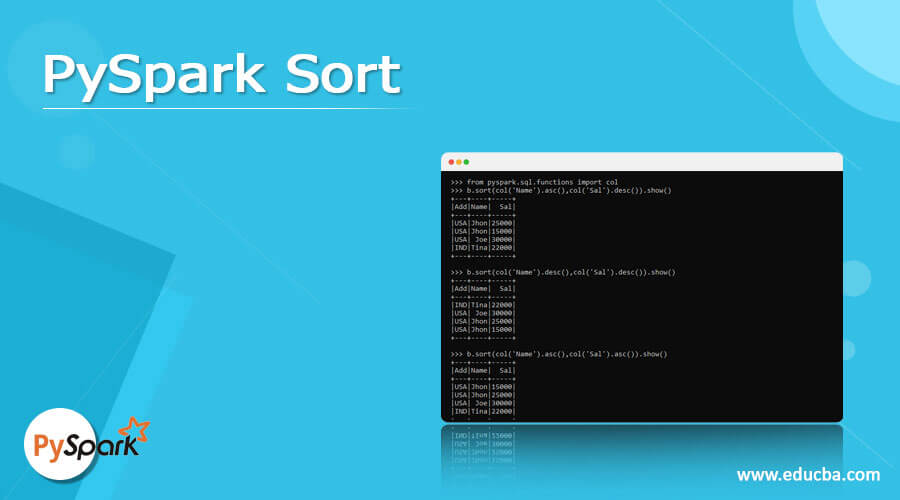
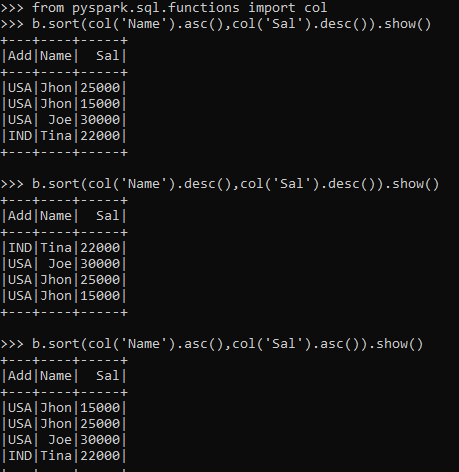
b.sort(col('Name').asc(),col('Sal').desc()).show()Here we have defined explicitly the sorting pattern as desc() and asc(). The Desc() sorts it in Descending Order and Asc as Ascending Order.
b.sort(col('Name').desc(),col('Sal').desc()).show()
b.sort(col('Name').asc(),col('Sal').asc()).show()In this way, the sorting pattern can be controlled over the user and the pattern of data needed.
Screenshot:
These are some of the Examples of PySpark Sort in PySpark.
Note:
- PySpark Sort is a Sorting function of the PySpark data model.
- PySpark Sort sorts the data in Ascending as well as Descending order, the default being the ascending one.
- PySpark Sort allows the shuffling of data over partitions.
- PySpark Sort can take up a single column as well as multiple columns.
- PySpark Sort doesn’t guarantee the total order of the output
Conclusion
From the above article, we saw the working of Sort in PySpark. From various examples and classifications, we tried to understand how this Sort function is used in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same.
We also saw the internal working and the advantages of having Sort in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark Sort. Here we discuss the introduction, syntax, and working of the sort function in PySpark along with different examples and code implementation. You may also have a look at the following articles to learn more –

