Updated February 21, 2023

Introduction to PySpark to Pandas
Pyspark to pandas is used to convert data frame, we can convert the data frame by using function name as toPandas. At the time of converting we need to understand that the PySpark operation runs faster as compared to pandas. Also, we can say that pandas run operations on a single node and it runs on more machines.
What is PySpark to Pandas?
In python, the module of PySpark in spark is used to provide the same kind of data processing as spark by using a data frame. The PySpark in python is providing the same kind of processing. It also provides several methods for returning top rows from the data frame name as PySpark. Pandas module is used in the analysis of data it will be supporting three series of data structure, panel, and data frame. We can also convert the PySpark data frame into pandas when we contain the PySpark data frame. We need to create a data frame first while converting it into pandas.
How to Convert Data Frame from PySpark to Pandas?
For converting we need to use the function name as toPandas(). For converting we need to install the PySpark and pandas module in our system.
- In the first step, we are installing the pandas and PySpark modules in our system. We are installing the same by using the pip command as follows.
pip install pandaspip install pyspark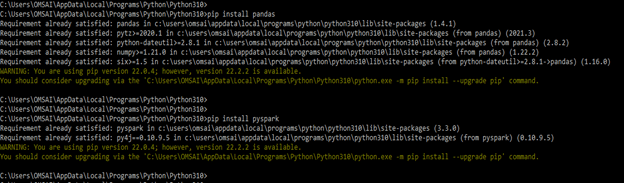
- After installing the module in this step, we are logging into the python server by using the command name python.
python
- After logging in to the python server, now in this step, we are importing the PySpark and SparkSession modules. We are importing both modules by using the import keyword.
import pyspark
from pyspark.sql import SparkSession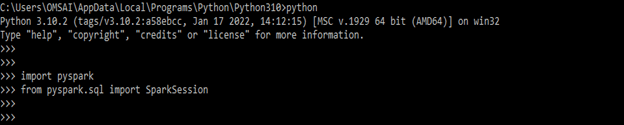
- After importing the module, now in this step, we are creating the application name as PySpark to pandas. We are defining the variable name as py_spark as follows.
py_spark = SparkSession.builder.appName('pyspark to pandas').getOrCreate()
- After creating the application now in this step we are creating the student data name as stud. We are creating the data with three rows and three attributes as follows.
stud = [{'stud_id' : '21', 'stud_name' : 'ABC', 'stud_age' : 12},
{'stud_id' : '23', 'stud_name' : 'PQR', 'stud_age' : 6},
{'stud_id' : '25', 'stud_name' : 'XYZ', 'stud_age' : 7}]
- After defining the data of the data frame now we are creating the data frame name as panda.
panda = py_spark.createDataFrame(stud)
- After creating the data frame now in this step we are converting the data frame by using the function name as toPandas.
print(panda.toPandas())
Method and Parameters
As the name suggests, the toPandas method is used to convert the data frame of spark into the panda’s data frame. We need to be issued the same warning by using collective action. The method of toPandas will collect the action from all records from all workers and it will be returning the same to the driver, it will convert the result from the pyspark data frame into the panda’s data frame.
We are using this method with the print function as well. In the second syntax, we have used the print function with PySpark to pandas method as follows.
Syntax:
dataframe.toPandas()
print(dataframe.toPandas())Pandas stand for the panel data structure which was used to represent data in a two-dimensional format like an SQL table. Below are the parameter description as follows.
- Dataframe – The data frame defines the name of the data frame which was we used at the time of creating the data frame. We can give any name to the data frame as per our data.
- Print – This function is used in the toPandas function to print the data which was created in the data frame. The print function is displaying converted data.
- toPandas – The method of toPandas is used to convert the data frame from PySpark to pandas.
The below example shows how we are using the methods and parameters as follows.
Code:
import pyspark
from pyspark.sql import SparkSession
py_spark = SparkSession.builder.appName ('pyspark to pandas').getOrCreate()
stud =[{'stud_id' : '21', 'stud_name' : 'ABC', 'stud_age' : 12},
{'stud_id' : '23', 'stud_name' : 'PQR', 'stud_age' : 6},
{'stud_id' : '25', 'stud_name' : 'XYZ', 'stud_age' : 7}]
panda = py_spark.createDataFrame( stud)
print (panda.toPandas())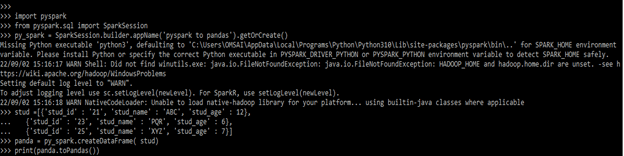
Examples
Below is the example as follows.
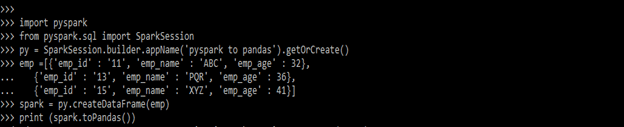
Example #1
In the below example, we are creating the data frame name as spark.
Code:
import pyspark
from pyspark.sql import SparkSession
py = SparkSession.builder.appName('pyspark to pandas').getOrCreate()
emp =[{'emp_id' : '11', 'emp_name' : 'ABC', 'emp_age' : 32},
{'emp_id' : '13', 'emp_name' : 'PQR', 'emp_age' : 36},
{'emp_id' : '15', 'emp_name' : 'XYZ', 'emp_age' : 41}]
spark = py.createDataFrame(emp)
print (spark.toPandas())Output:
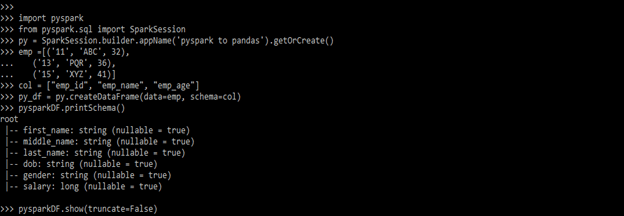
Example #2
In the below example, we are defining the column name of the dataset.
Code:
import pyspark
from pyspark.sql import SparkSession
py = SparkSession.builder.appName('pyspark to pandas').getOrCreate()
emp =[('11', 'ABC', 32),
('13', 'PQR', 36),
('15', 'XYZ', 41)]
col = ["emp_id", "emp_name", "emp_age"]
py_df = py.createDataFrame(data=emp, schema=col)
pysparkDF.printSchema()
pysparkDF.show(truncate=False)Output:
Key Takeaways
- In python, the toPandas method is used to convert data frames. At the time of using the toPandas method, we are using a data frame that was created in pyspark.
- The toPandas method will collect all pyspark data frame records and convert them into pandas DataFrame.
FAQ
Given below is the FAQ mentioned:
Q1. What is the use of PySpark to pandas in python?
Answer: Basically this method is used to convert the data frame from PySpark to pandas by using a specified method.
Q2. What is the use of iterrows in PySpark to pandas method?
Answer: This method is used to iterate the columns into the data frame of PySpark by converting the same into the panda’s data frame.
Q3. What is the use of the toPandas method in PySpark to pandas in python?
Answer: The toPandas method is used to convert the PySpark data frame into the panda’s data frame.
Conclusion
PySpark provides several methods for returning top rows from the data frame name as PySpark. Pandas module is used in the analysis of data. Pyspark to pandas is used to convert data frame, we can convert the data frame from PySpark to pandas by using function name as toPandas.
Recommended Articles
This is a guide to PySpark to Pandas. Here we discuss the introduction and how to convert Data Frame along with examples and code implementation. You may also have a look at the following articles to learn more –

