Updated April 1, 2023

Introduction to PySpark toDF
PYSPARK toDF is a method in PySpark that is used to create a Data frame in PySpark. The model provides a way .toDF that can be used to create a data frame from an RDD. Post conversion of RDD in a data frame, the data then becomes more organized and easy for analysis purposes.
It uses the default name as the column name that can be used for the creation of the data frame, post then we can also pass the name of the column that needed to be done. This can be called the manual way of creating of Data Frame in PySpark.
In this article, we will try to analyze the various method used for toDF.
Let us try to see about toDF in some more detail.
The syntax for PySpark toDF
The syntax for the toDF function is:-
a = sc.parallelize(data1)
b = a.toDF()
b.show()- a: The RDD to be Made from the Data.
- .toDF(): The to DF method to create the dataFrame.
- B: The created dataframe.
Screenshot:
Working of PySpark toDF
Let us see somehow toDF operation works in PySpark:-
This is a method to create a Data Frame in PySpark. The create data frame takes up the RDD and then converts it into the RDD to the data frame.
It can also take up the argument that can be used to name the Data frame column. It can be called on a sequence of objects to create a data frame.
The type of the column and nullable is not customized in the toDF method of PySpark.
We cannot have control over the schema while creation of Data frame using the .toDF method.
Let’s check the creation and working of the ToDF method with some coding examples.
Example of PYSPARK toDF
Let us see some Examples of how the PYSPARK toDF operation works:-
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Output:

This creates the data frame with the column name as Name, Add, and ID. The above data frame is made by using the method createDataFrame in PySpark.
Now use the .toDF method to create the same in PySpark.
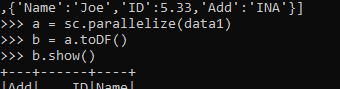
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]
a = sc.parallelize(data1)
b = a.toDF()
b.show()Output:

The method creates the Data Frame with the column name that resolves up the column name.
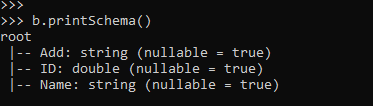
This schema can be seen, and the column name can be seen from there.
b.printSchema()Output:
Lets us check one more example and check where the column name is assigned by default, and check for the creation of a Data frame.
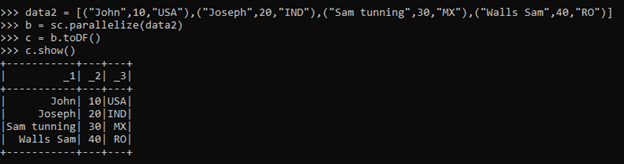
data2 = [("John",10,"USA"),("Joseph",20,"IND"),("Sam tunning",30,"MX"),("Walls Sam",40,"RO")]
b = sc.parallelize(data2)
c = b.toDF()
c.show()This creates the data frame with the default column name as _1, _2,_3.
Output:
Let’s check this with details.
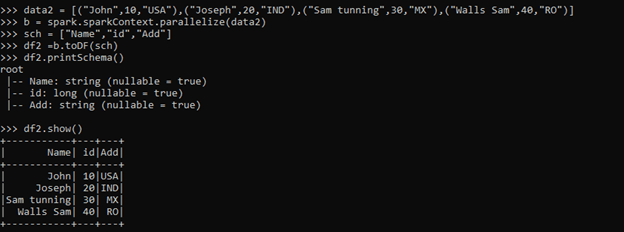
data2 = [("John",10,"USA"),("Joseph",20,"IND"),("Sam tunning",30,"MX"),("Walls Sam",40,"RO")]
b = spark.sparkContext.parallelize(data2)
sch = ["Name","id","Add"]
df2 =b.toDF(sch)
df2.printSchema()This adds up the column name bypassing the argument into to .toDF method.
df2.show()Output:
These created data frames are optimized and can be used further for SQL queries and data analysis. The cost model post-conversion is easier in a data frame, and we have a logical plan for querying the data in a data frame.
These are some of the Examples of toDF in PySpark.
Note:
- PySpark ToDF is used for the creation of a Data frame in PySpark.
- It is an inbuilt operation.
- ToDF can be used to define a schema and create a data frame out of it.
- ToDF the method is cost-efficient and widely used for operation.
- ToDF, by default, crates the column name as _1 and _2.
Conclusion
From the above article, we saw the functioning of the ToDF function. Then, from various examples and classifications, we tried to understand how this ToDF function works and what are is used at the programming level.
We also saw the internal working and the advantages of toDF in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark toDF. Here we discuss the introduction, syntax, and working of PySpark toDF along with examples and code. You may also have a look at the following articles to learn more –

