Updated April 4, 2023

Introduction to PySpark Write Parquet
PySpark Write Parquet is a write function that is used to write the PySpark data frame into folder format as a parquet file. Parquet files are the columnar file structure that stores the data into part files as the parquet file format. Parquet files are faster and easier to read and write operation is also faster over there.
Write Parquet is in I/O operation that writes back the file into a disk in the PySpark data model. It uses the method from the function of the data frame writer class, The column name while writing the data into Parquet file preserves the column name and the data type that is to be used. The files are created with the extension as .parquet in PySpark.
In this article, we will try to analyze the various ways of using the PYSPARK Write Parquet operation PySpark.
Let us try to see about PYSPARK Write Parquet in some more detail.
Syntax:
The syntax for the PySpark Write Parquet function is:
b.write.parquet("path_folder\\parquet")Parameters:
- b: The data frame to be used will be written in the Parquet folder.
- write: The write function that needs to be used to write the parquet file.
- .parquet(): The Format to be used, parquet file format writes the file into Parquet format.
- path Folder: The Path that needs to be passed on for writing the file to the location.
Screenshot:
![]()
Working of Write Parquet in PySpark
Let us see how PYSPARK Write Parquet works in PySpark:
Parquet file formats are the columnar file format that used for data analysis. It supports the file format that supports the fast processing of the data models. The write method takes up the data frame and writes the data into a file location as a parquet file.
The write.Parquet function of the Data Frame writer Class writes the data into a Parquet file. The column name is preserved and the data types are also preserved while writing data into Parquet. The columns are automatically converted nullable.
There can be different modes for writing the data, the append mode is used to append the data into a file and then overwrite mode can be used to overwrite the file into a location as the Parquet file.
A success file is created while successful execution and writing of Parquet file. The data backup is maintained while writing down and the data is written back as a parquet file in the folder. It maintains the data along with the schema of the data too. Structured files are easily processed with this function.
We can create tables and can perform SQL operations out of it.
Let’s check the creation and working of PySpark Write Parquet with some coding examples.
Examples
Let us see some Examples of how PySpark Write Parquet operation works:-
Let’s start by creating a sample data frame in PySpark.
data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]The data contains the Name, Salary, and Address that will be used as sample data for Data frame creation.
a = sc.parallelize(data1)The sc.parallelize will be used for the creation of RDD with the given Data.
b = spark.createDataFrame(a)Post creation we will use the createDataFrame method for the creation of Data Frame.
This is how the Data Frame looks.
b.show()Screenshot:

Let’s try to write this data frame into a parquet file at a file location and try analyzing the file format made at the location.
b.write.parquet("path_folder\\parquet")The file format that it creates up is of the type .parquet.
Screenshot:

The file format to be used creates crc as well as parquet file. Part files are created that are in the parquet type.
Screenshot of File format
These files once read in the spark function can be used to read the part file of the parquet. The mode appends and overwrite will be used to write the parquet file in the mode as needed by the user.
b.write.mode('append').parquet("path")The mode to append the data as parquet file.
b.write.mode('overwrite').parquet("path")The mode to over write the data as parquet file.
Screenshot of the File Format:
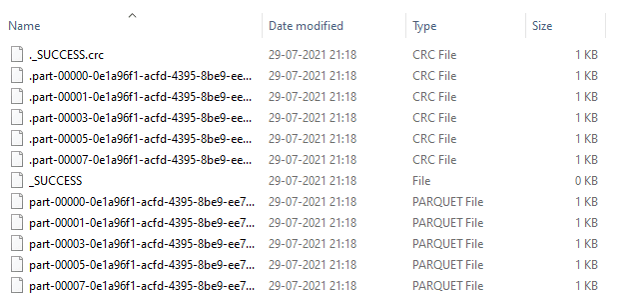
These are some of the Examples of PySpark Write Parquet Operation in PySpark.
Note:
1. PySpark Write Parquet is an action that is used to write the PySpark data frame model into parquet file.
2. PySpark Write Parquet is a columnar data storage that is used for storing the data frame model.
3. PySpark Write Parquet preserves the column name while writing back the data into folder.
4. PySpark Write Parquet creates a CRC file and success file after successfully writing the data in the folder at a location.
Conclusion
From the above article, we saw the working of Write Parquet in PySpark. From various examples and classifications, we tried to understand how this Write Parquet function is used in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same. We also saw the internal working and the advantages of Write Parquet in PySpark Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark Write Parquet. Here we discuss the introduction, syntax, and working of Write Parquet in PySpark along with an example and code implementation. You may also have a look at the following articles to learn more –

