Updated April 3, 2023

Introduction to Python Pandas DataFrame
The following article provides an outline for Python Pandas DataFrame. ‘Pandas’ stands for a panel of two dimensional data, which is collected and organized in a table formatted data structure from the python library. This structure is termed as ‘DataFrame’ or DF, as it is similar to a two dimensional table structure used for placing the data with reference to the rows and columns. A significant advantage of the pandas dataframe is that the structure makes it flexible enough for performing transactional and analytical operations with the data present in the dataframe. The main components of this technique are the Data, the Rows and the Columns of the DataFrame.
What Exactly is a Python Pandas DataFrame?
Pydata page can be referred for something of an official definition.
If understood correctly, it mentions DataFrame as a columnar structure, capable of storing any python object (including a DataFrame itself) as one cell value. (A cell is indexed using a unique row & column combination).
DataFrames consists of three essentials components: data, rows, and columns.
- Data: It refers to the actual objects/entities stored in a cell in the DataFrame and the values represented by these entities. An object is of any valid python data-type, whether in-built or user-defined.
- Rows: References used to identify (or index) a particular set of observations from the complete data stored in a DataFrame is called as the Rows. Just to make it clear, it represents the indices used and not just the data in a particular observation.
- Columns: References used to identify (or index) a set of attributes for all the observations in a DataFrame. As in the case of rows, these refer to the column index (or the column headers) instead of just the data in the column.
Some ways to create these awesomely powerful structures.
Steps to Create Python Pandas DataFrames
A Python Pandas DataFrame can be created using the following code implementation:
1. Import Pandas
To create DataFrames, the pandas library needs to be imported (no surprise here). We will import it with an alias pd to reference objects under the module conveniently.
Code:
import pandas as pd2. Creating the First DataFrame Object
Once the library is imported, all the methods, functions, and constructors are available in your workspace. So, let’s attempt creating a vanilla DataFrame.
Code:
import pandas as pd
df = pd.DataFrame()
print(df)Output:
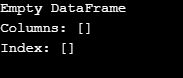
As shown in the output, the constructor returns an empty DataFrame.
Let’s now focus on creating DataFrames from data stored in some of the likely representations.
- DataFrame from A Dictionary: Let’s say we have a dictionary storing a list of companies in Software Domain and the number of years they have been active.
Code:
import pandas as pd
df = pd.DataFrame(
{'Company':['Google','Amazon','Infosys','Directi'],
'Age':['21','23','38','22']
})
print (df)Let’s see the representation of the returned DataFrame object by printing it on the console.
Output:

As can be seen, each key of the dictionary is treated as a column in the DataFrame, and the row indices are generated automatically starting from 0.
Now let’s say you wanted to give it a custom index instead of 0,1,..4. You just need to pass the desired list as a parameter to the constructor and pandas will do the needful.
Code:
df = pd.DataFrame(
{'Company':['Google','Amazon','Yahoo','Infosys','Directi'],
'Age':['21','23','24','38','22']
},
index=['Alpha','Beta','Gamma','Delta'])
print(df)Output:
Company Age
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Now you can set row indices to any desired value.
- DataFrame from A CSV File: Let’s create a CSV file containing the same data as in the case of our dictionary. Let’s call the file CompanyAge.csv
Google,21
Amazon,23
Infosys,38
Directi,22
The file can be loaded into a dataframe (assuming it’s present in the current working directory) as follows.
Code:
import pandas as pd
csv_df = pd.read_csv(
'CompanyAge.csv',names=['Company','Age'],header=None)
print(csv_df)Output:
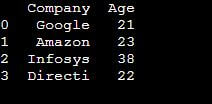
Setting the parameter names, bypassing a list of values, assigns them as column headers in the same order they are present in the list. Similarly, row indices can be set by passing a list to the index parameter, as shown in the previous section. The header=None indicates missing column headers in the data file.
let’s say the column names were part of the data file. Then setting header=False will do the required job.
3. CompanyAgeWithHeader.csv
Company, Age
Google,21
Amazon,23
Infosys,38
Directi,22
The code will change to:
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv',header=False)
print(csv_df)Output:
Company Age
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame from An Excel File: Often data is shared in excel files as it remains the most popular tool used by common folks for Adhoc tracking. Thus, it shouldn’t be ignored by our discussion.
Let’s assume the data, same as in CompanyAgeWithHeader.csv is now stored in CompanyAgeWithHeader.xlsx, in a sheet with the name Company Age. The same DataFrame as above will be created by the following code.
Code:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx',sheet_name='CompanyAge')
print(excel_df)Output:
Company Age
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
As you can see, the same DataFrame can be created by passing the filename and sheet name.
Further Reading and Next Steps
The methods shown constitute a very small subset in comparison to all the different ways DataFrames can be created. These were created with the intention of getting one started. You should definitely explore the references listed and attempt exploring other ways, including connecting to a database to read data directly into a DataFrame.
Conclusion
Pandas DataFrame has proven to be a game-changer in the world of Data Science and Data Analytics, as well as is convenient for ad-hoc short-term projects. It comes with an army of tools capable of slicing and dicing the data set with extreme ease.
Recommended Articles
We hope that this EDUCBA information on “Python Pandas DataFrame” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

