Introduction to the Pronouncing Module in Python
The Pronouncing module, a library, is a simple interface to the CMU Pronouncing Dictionary within Python. It facilitates tasks such as finding rhyming words and other operations commonly performed using the CMU Pronouncing Dictionary. While Python already offers several packages for discovering rhyming words, the standout feature of this module is its independence from external dependencies, making it incredibly user-friendly.
The Python Pronouncing module, developed to provide a seamless interface to the CMU Pronouncing Dictionary directly from Python programs, eliminating the need to install additional libraries like NLTK. Utilizing the functions within this module is straightforward, enabling users to effortlessly integrate it into their Python code to uncover rhyming words associated with a given input.
Utilizing the Pronouncing module saves users valuable time they would otherwise spend manually brainstorming or searching for rhyming words. Simply incorporating the module’s functions into a Python program yields all relevant rhyming words about the specified input word, streamlining the process and enhancing efficiency.
Table of Contents
Key takeaways:
- Perform analysis and manipulation of English word pronunciation.
- Essential for linguistic analysis for determining stress patterns, phonetic representation, and syllable counting.
- Provide rhyme words and rhythmic patterns for creative writing.
- Support text-to-speech synthesis and speech recognition.
- Helps in accurate pronunciation and correction for misspelled words.
Rhymes with Python Pronouncing Module
Finding rhyming words can be challenging, especially when writing poetry or crafting rhymes. Fortunately, the CMU Pronouncing Dictionary offers a solution. Developed by the Speech Group at Carnegie Mellon University, this open-source dictionary provides a comprehensive list of rhyming words for any given word in the English language. Utilizing this resource, poets and writers can effortlessly discover rhyming words to enhance their creative works.
Python enthusiasts can leverage the power of the CMU Pronouncing Dictionary through the pronouncing package. This package serves as a convenient interface to access the dictionary’s extensive database of rhymes. Users can dynamically generate rhyming words for any input word by integrating this module into Python programs, streamlining the creative process.
In this article, we’ll delve into the installation and usage of Python’s pronouncing module, empowering aspiring poets and writers to effortlessly explore the world of rhyming words within their Python projects.
Pronunciation Features:
Accessing CMU dictionary:
The Python Pronouncing module provides an interface for accessing the CMU dictionary created at Carnegie Mellon University by the Speech Group for use in speech recognition research. The CMU has a vast collection of English words and their phonetic representation. The dictionary is freely available and easily accessible for users to retrieve phonetic representation and perform linguistic analysis and natural language processing tasks.
Rhyme Detection:
Rhyme detection allows users to find the rhyming word for the given word, and the function returns the word with phonetic similarity. Rhyme detection is a valuable tool for songwriters, poets, and other creative writers who use rhyming words to achieve cohesion and flow. Python Pronouncing module’s “pronouncing.rhymes()” function returns the list of the words that rhyme with the provided word as input.
Stress Pattern:
We use stress patterns to identify the stressed syllables in a word for accurate pronunciation. It refers to the stressed and unstressed syllables, which is crucial for understanding the rhythm and emphasis of natural speech. The Python Pronouncing module’s pronouncing.stresses() function helps you identify the stress pattern of a given word. It returns 0 for unstressed syllables, 1 for primary stressed syllables, and 2 for Secondary stress syllables.
Syllable Counting:
Python’s pronouncing module can count the syllables in a word. A syllable typically refers to a speech unit containing a vowel or consonant sound. Counting syllables is essential for measuring word complexity, analyzing meter in spoken speech, and determining pronunciation. The “pronouncing.syllables_count” function of the Python Pronouncing module calculates the number of syllables in a given word and returns the integer value representing syllables count.
Phonetic Representation:
The Python pronouncing module represents pronunciation by utilizing ARPAbet (American English Phonetic Alphabet) phonetic transcription system. It assigns a unique code for each sound unit (phoneme); this code is represented by one or more characters, ensuring precise representation of pronunciation. The Python pronouncing module “pronouncing.phones_for_word” analyzes and returns a list of ARPAbet codes representing the possible pronunciation of the provided word.
Finding words with similar Pronunciation:
The Pronouncing module allows us to find the words that have phonetic similarities in their pronunciations. The search() function determines and returns a list of words with similar phonetic representation. This function is valuable in language generation, text-to-speech conversion, speech recognition, and natural language processing tasks.
Installation and Setup:
Installation:
- Install the Python pronouncing module externally using a Python package manager Using the following command in our operating system’s command prompt shell, we can install the Python pronouncing module:
pip install pronouncing- Before installation, make sure that your system has Python installed in it by using the following command:
python –version- Enter the installation command for the Python Pronouncing module. Press “Enter,” and the installation process will start:
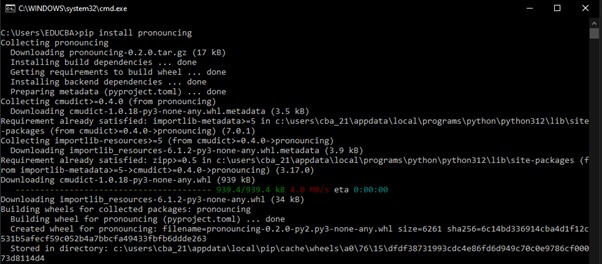
- The Python Pronouncing module has been successfully installed in our operating system once the command has been run. The installation process will then begin.
![]()
Setup:
- After completion of the installation process, open a Python script or interactive environment and import the pronouncing module as follows:
import pronouncing
- Now, using your Python code, you can use the Python Pronouncing module and the functions introduced by the module to work with word pronunciation.
- Let us use a simple example of using the Pronouncing function “rhymes()” to display the words that rhyme with the given word.
Code:
import pronouncing
rhymeWords= pronouncing.rhymes("Fine")
print("The rhyming words of the word Fine are: ")
print(rhymeWords)Output:

Explanation:
- Import the pronouncing module
- Use the rhymes() function to find the words that rhyme
- Use print statements to display rhyme words
Basic Usage
1. Rhyming words:
Rhyme detection is used to find the words that rhyme with the given word
Code:
# Step 1 – Importing the pronouncing module
import pronouncing
# Step 2 - User input text to find the rhyme
inputText = input("Enter a word to find rhyming words: ")
# Step 3 – Utilize rhymes() function for finding rhyming words
rhymingWords= pronouncing.rhymes(inputText)
# Step 4 - Print result
print("Rhyming words for the given word are: ")
print(rhymingWords)Output:

Explanation:
- Import pronouncing module
- Take input as the user defines value for determining rhyme
- Use rhymes() function to find rhyming words for the given word
- Print rhyming words
2. Phonetic Representation:
Phonetic representation represents the pronunciation by assigning a unique code for each sound unit in a given word
Code:
# Improt pronouncing module
import pronouncing
# Use phones_for_word() function for finding the phonetic repesentation for the given word
Result= pronouncing.phones_for_word("beautiful")
# Print result
print("Phonetic Representation: ")
print(Result)Output:
![]()
Explanation:
- Import pronouncing module
- Use the phones_for_words() function to find the phonetic representation of a word
- Print the result
3. Syllable count:
Syllable count represents the number of syllables in a word which has a vowel and consonant in it
Code:
def syllables_count(english_word):
english_word = english_word.lower()
count = sum(
1 for i in range(1, len(english_word))
if english_word[i] in "aeiouy" and english_word[i - 1] not in "aeiouy")
return count + (english_word[0] in "aeiouy") - (english_word.endswith("e") and count > 0)
print("Number of syllable in word:")
print(syllables_count("BANANA"))Output:
![]()
Explanation:
- Define function name with parameter as a word to count syllable
- Convert the input word to lowercase for consistency
- Count the number of times in a given word vowel is preceded by a non-vowel
- Return final syllables after handling edge cases
- Print the syllable count in the given word.
Pitfalls to Avoid
While using Python’s pronouncing module, some pitfalls should be considered and avoided.
1) Presumptions about pronunciation:
The CMU Pronouncing Dictionary might not encompass all dialects or variations of pronunciation. Ensure a word’s pronunciation is grounded exclusively on the dictionary’s response.
2) Homographs and homophones:
Words spelled similarly but with different pronunciations (homographs) or words that sound the same but have different significance and spellings (homophones) might guide to surprising and unexpected outcomes. Be aware of the context.
3) Incomplete coverage:
Even though the CMU Pronouncing Dictionary is comprehensive, it may incorporate only some of the words in English. This flaw can lead to high inaccuracy in the application.
4) Accuracy of rhymes:
Although the module provides rhyming words, the characteristics and precision of these rhymes may differ. Always confirm the appropriateness of rhyming words for your exclusive scenario.
5) Performance considerations:
Performance flaws may emerge considering the length of the incoming text or the intricacy of the operations executed utilizing the module. Enhancing your code and considering caching response is essential to optimize performance.
6) Handling exceptions:
Execute robust error handling for cases where words are not a part of the dictionary or unexpected inputs are faced. It helps sustain the resilience of your application.
7) Language limitations:
The CMU Pronouncing Dictionary focuses on English word pronunciations. If your application requires support for other languages, you may need to opt for alternative dictionaries or libraries.
Conclusion
The pronouncing module of Python provides a versatile toolset for word analysis within a Python programming environment. The Python module is valuable for maintaining accuracy, finding rhymes, and correcting misspelled words in creative writing. The Python environment ensures efficient processing for text-based analysis, phonetic representation, syllable counting, and stress pattern detection.
Frequently Asked Questions (FAQs)
Q1) Is Python’s pronouncing module suitable for speech recognition?
Answer: Although Python’s pronouncing module incorporates phonetic data for the English language, it may not be optimized for real-time performance. For use cases like speech recognition, specialized libraries and APIs like Google Cloud speech-to-text, Microsoft Azure speech services, IBM Watson speech-to-text, Mozilla Deepspeech, etc., should be opted for.
Q2) Are there any legal considerations while utilizing Python’s pronouncing module in real-world applications?
Answer: Python’s pronouncing module is under MIT License. It is open source and freely available. So, while using a commercial platform, users should consider its legal terms like license compliance, providing attribution to authors while incorporating third-party libraries, data privacy, end-user agreement, intellectual property rights, foreign distribution laws, etc.
Q3) Is adding new words to the CMU pronouncing dictionary possible?
Answer: Yes, it is possible to add new words to the CMU pronouncing dictionary since the dictionary is open-source, and in such cases, suggestions and modifications are accepted by authors. If the user wants to add a word to the dictionary that can enhance its use, the user should submit the word and its phonetic transcription via GitHub or email. Users can also correct any mistakes found in the library by submitting the correct version of the word via GitHub or email. The respective teams consider the words; if the words fulfill the criteria, then the words become a part of the dictionary.

