Updated April 4, 2023

Introduction to PyTorch Activation Function
The following article provides an outline for PyTorch Activation Function. The balanced sum of the inputs is subjected to an activation function. An activation function’s job is to bring non-linearity into the Neural Network’s decision bounding box. Activation functions accept any integer as an input and convert it to an outcome. We can employ nonlinear functions to achieve this goal because any function can be used as an activation function.
What is the PyTorch activation function?
The activation functions can be deployed to a network layer in a variety of ways:
- The activation function layer—these are classes that can be utilized as activation functions—can be used.
- Activation functions are defined as functions that can be employed as activation functions.
Using the PyTorch activation function
Any activation function, including f(x)=x, the linear or identity function, can be employed. When constructing and implementing an activation function, the computational efficiency of the function is the most important factor to consider. Without the activation function, the network is a stack linear regression model. Therefore, in each of the layers, we use an activation function.
Types PyTorch activation function
The most widely used activation functions are included in the Pytorch library. Modules (or classes) and definitions have been provided for these activation functions. Some of the most regularly used activation functions and their corresponding class and function names are included here. The most popular function is
- Step Function
- Sigmoid
- Tanh
- RELU
- Leaky RELU
- SoftMax
Rectified Linear Unit, Sigmoid, and Tanh are three activation functions that play a key role in the operation of neural networks. ReLU, on the other hand, has mostly withstood the test of time and generalizes extremely well over a wide range of deep learning applications. For example, we can use one of these in classic PyTorch:
Add the nn.Sigmoid(), nn.Tanh(), or nn.ReLU() activation directly functions to the neural network, for example, in nn. Sequential. The Tanh and Sigmoid activation functions are the earliest based on neural network significance. Tanh translates all inputs into the (-1.0, 1.0) range, with the highest slope around x = 0. The graph beneath shows that Tanh transforms all inputs into the (-1.0, 1.0) spectrum. On the other hand, the Sigmoid converts all inputs to a range of (0.0, 1.0), with the steepest slope around x = 0. ReLU is distinct. If x=0.0, this function sets all inputs to 0.0. The input is assigned to x in all the other circumstances.
Sigmoid: The PyTorch sigmoid function deforms any real integer into a value between 0 and 1 via an element-wise approach. This is a typical activation function in a classification algorithm (including logistic regression), whose outputs are true, i.e., p (y == 1).
tanh: Pytorch tanh is divided based on its output, i.e., between -1 and 1. The hyperbolic tangent feature may be differentiated at every point, and its derivative is 1 – tanh2(x). Because the expression uses the tanh function, that function’s return can be utilized to speed up reverse propagation. Tanh is similar to Sigmoid except that it is centered and ranges from -1 to 1.
RELU: The activation function nn.ReLU is used to make the system non-linear and fits complex information. For example, Relu is an activation function that is given like this:
relu(x) = { 0 if x<0, x if x > 0}.To the forward pass, add the logical representations of these activation functions.
Below is
Code:
import torch.nn.functional as F
def __init__(self):
super().__init__()
self.layers = nn. Sequential(
nn.Linear(27 * 27, 255),
nn.Sigmoid(),
nn.Linear(255, 127),
nn.Tanh(),
nn.Linear(127, 10),
nn.ReLU()
)
def forward (self, a):
a = F.sigmoid(self.lin1(a)
a = F.tanh(self.lin2(a))
a = F.relu(self.lin3(a))
return aImporting PyTorch activation function
Importing the Activation Function Definition:
The torch.nn.functional module contains the activation function levels. F is the most popular import name for this module.
import torch.nn as nn
import torch.nn.functional as FExample of PyTorch Activation Function
Let’s see different types of Activation layers with examples
Example #1 – Using Sigmoid
Code:
import torch
torch.manual_seed(1)
a = torch.randn((2, 2, 2))
b = torch.sigmoid(a)
b.min(), b.max()Explanation:
The output of this snippet shows how the sigmoid function is used, and the torch-generated value is given as:
Output:
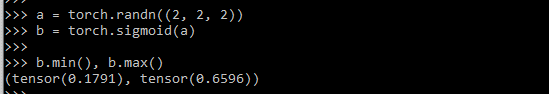
Example #2
Code:
import torch
import torch.nn as nn
import torch.nn.functional as F
a = torch.tensor([-1.1, 1.1, 3.0, 4.0])
out = torch.softmax(x, dim=0)
print(out)
s1 = nn.Softmax(dim=0)
out = s1(a)
print(out)
out = torch.sigmoid(a)
print(output)
s2 = nn.Sigmoid()
output = s(a)
print(out)
out = torch.tanh(a)
print(out)
t = nn.Tanh()
out = t(a)
print(out)
out = torch.relu(a)
print(out)
relu = nn.ReLU()
out = relu(a)
print(out)
out = F.leaky_relu(a)
print(out)
lrelu = nn.LeakyReLU()
out = lrelu(a)
print(out)
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size):
super(NeuralNet, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(hidden_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, a):
out1 = self.linear1(a)
out1 = self.relu(out1)
out1 = self.linear2(out1)
out1 = self.sigmoid(out1)
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size):
super(NeuralNet, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, 1)
def forward(self, a):
out1 = torch.relu(self.linear1(a))
out1 = torch.sigmoid(self.linear2(out1))
return out1
Output
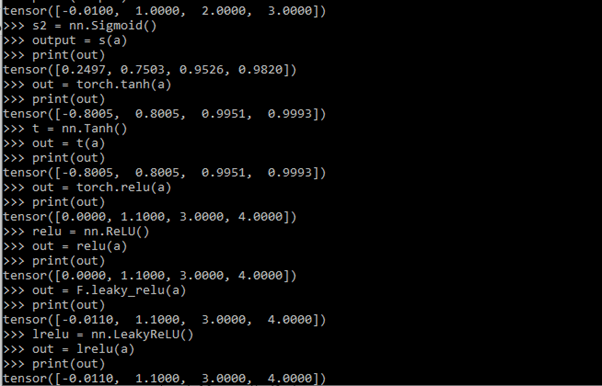
Example #3 – Using tanh Activation Function
Code:
import torch
import numpy as np
import matplotlib.pyplot as plt
m = np.linspace ( - 4 , 4 , 13 )
n= torch.tanh (torch.FloatTensor (m))
print (n)
plt. plot (m, n.numpy (), color = 'green' , marker = "o" )
plt.title ( "torch.tanh" )
plt.xlabel ( "X" )
plt.ylabel ( "Y" )
plt.show ()
print (n)
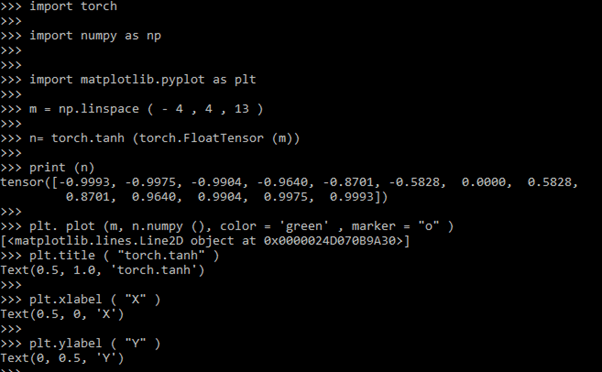
tensor ([-0.9993, -0.9975, -0.9904, -0.9640, -0.8701, -0.5828, 0.0000, 0.5828, 0.8701, 0.9640, 0.9904, 0.9975, 0.9993])Explanation
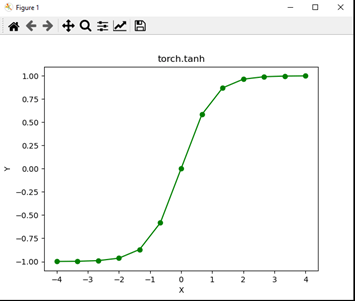
The above code is a visualization concept that imports NumPy and Pytorch Library, and matplotlib is used to plot tanh values. Here the vector size is 13 and ranges from -4 to 4. Finally, a plot is built, shown in the graph below.
Output
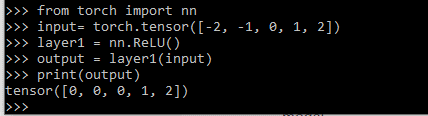
Example #4 – Using RELU
Code:
input= torch.tensor([-2.1, -1, 0, 1, 2.1])
layer1 = nn.ReLU()
output = layer1(input)
print(output)Output
Conclusion
That’s how we calculate the Activation function in PyTorch. When we have numerous layers in our neural network, i.e., hidden layers, it becomes even more powerful. Therefore, choosing the proper activation function for each layer is critical and can significantly affect learning speed.
Recommended Articles
We hope that this EDUCBA information on “PyTorch Activation Function” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
