Updated April 5, 2023

Introduction to PyTorch Early Stopping
Python early stopping is the process of regularizing that has the advantage to avoid the overfitting caused on the data considered for training purpose. In this article, we will have a detail dive into the topic PyTorch early stopping overviews, how to use PyTorch early stopping, implement early PyTorch early stopping, PyTorch early stopping examples, and finally conclude our statement.
PyTorch Early Stopping Overviews
PyTorchtool.py is the library whose EarlyStopping class helps in the creation of an object for keeping a track of all the losses incurred while the validation process. Training is completely stopped when in case if there is a gradual decrease observed in the loss stops of multiple epochs continuously happening in a row. PyTorch early stopping is used for keeping a track of all the losses caused during validation. Whenever a loss of validation is decreased then a new checkpoint is added by the PyTorch model.
Before the training loop was broken when was the last time when there was a slight improvement observed in the validation loss, an argument called patience is set in the class named EarlyStopping just to keep a track of the number of epochs that should be waited after the last improvement in losses of validation.
How to Use PyTorch early stopping?
We can simply early stop a particular epoch by just overriding the function present in the PyTorch library named on_train_batch_start(). This function should return the value -1 only if the specified condition is fulfilled. The complete process of run is stopped if we try to return -1 from on train batch start function on basis of conditions continuously in a repetitive manner if the process is performed for each and every epoch that we originally requested.
An alternative way to do this is by making the use of callback EarlyStopping which is used for monitoring of metrics of validation. At the same time, if none of the improvement is there, we can even go to stop the training.
Implement early PyTorch early stopping
In the process of enabling the EarlyStopping callback we will have to perform the following steps –
- EarlyStopping callback should be imported at the top of the program.
- By using the method log() we can keep the logs and monitoring of the required metrics.
- The next step is the initialization of callback and further, go for setting any of the metrics that is logged according to our choice to the monitor.
- EarlyStopping callback should be passed to the callbacks flag named Trainer.
Some of the other parameters that are required for stopping the process of training at some of the points that are extreme in nature are as follows –
- Divergence threshold – If the quantity that is monitored reaches a value that is even worse than the specified value then the training is immediately stopped. If this kind of condition arises that we are sure there can be none of the recoveries of the model then we should better way opt for stopping the model early by specifying the conditions at the beginning that are different.
- Stopping threshold – When the value of the monitored quantity reaches the value of threshold then we can use this parameter to stop the training immediately. The most important scenario is when we are already aware that if the value reaches beyond the particular value, then there will not be any benefit to us.
- Check infinite – If the value of the metric that is monitored has the value infinite or NAN when we make this parameter on.
PyTorch early stopping examples
Let us consider one sample example where we will try to write the program for the recognition of handwritten digits in the simple mnist format –
Code:
# UTF-8 standard coding pattern
import torch
import torch.nn as neuralNetwork
import torch.optim as optimizer
import torch.utils.data as sampleData
from torchvision import educbaSetOfData, transforms
# Designing the architecture of model
class Net(neuralNetwork.Module):
def __init__(selfParam):
super(Net, selfParam).__init__()
selfParam.main = neuralNetwork.Sequential(
neuralNetwork.Linear(inputFeatures = 784, outputFeatures = 128),
neuralNetwork.ReLU(),
neuralNetwork.Linear(inputFeatures = 128, outputFeatures = 64),
neuralNetwork.ReLU(),
neuralNetwork.Linear(inputFeatures = 64, outputFeatures = 10),
neuralNetwork.LogSoftmax(dim = 1)
)
def forward(selfParam, input):
return selfParam.main(input)
# Training the model
def train(device, model, epochs, optimizerizer, functionForLossCalculation, loaderForTraining):
for epoch in range(1, epochs+1):
for times, sampleData in enumerate(loaderForTraining, 1):
inputs = sampleData[0].to(device)
labels = sampleData[1].to(device)
# Set the value of gradints to zero
optimizerizer.zero_grad()
# Progation is being done in the backward and forward manner
outputs = model(inputs.view(inputs.shape[0], -1))
loss = functionForLossCalculation(outputs, labels)
loss.backward()
optimizerizer.step()
# Displaying the progress of model
if times % 100 = = 0 or times = = len(loaderForTraining):
print('[{}/{}, {}/{}] loss: {:.8}'.format(epoch, epochs, times, len(loaderForTraining), loss.item()))
return model
def test(device, model, loaderUsedForTestingPurpose):
# set the values for settings of model
model.eval()
acquiredTotal = 0
correctnessOfModel = 0
with torch.no_grad():
for sampleData in loaderUsedForTestingPurpose:
inputs = sampleData[0].to(device)
labels = sampleData[1].to(device)
outputs = model(inputs.view(inputs.shape[0], -1))
_, predicted = torch.max(outputs.sampleData, 1)
total + = labels.size(0)
correctnessOfModel + = (predicted = = labels).sum().item()
print('Achieved Accuracy:', correctnessOfModel / total)
def main():
# defining the values related to GPU device
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
print('State Of Device:', device)
# set the values for settings of model
epochs = 100
sizeOfBatch = 64
lr = 0.002
functionForLossCalculation = neuralNetwork.NLLLoss()
model = Net().to(device)
optimizerizer = optimizer.Adam(model.parameters(), lr = lr)
# transform the created model
sampleObjectOftransform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))]
)
# Prepare the dataset for training
setOfValuesForTraining = educbaSetOfData.MNIST(root = 'MNIST', download = True, train = True, transform = sampleObjectOftransform )
setForTesting = educbaSetOfData.MNIST(root = 'MNIST', download = True, train = False, transform = sampleObjectOftransform )
loaderForTraining = sampleData.DataLoader(setOfValuesForTraining, batch_size = sizeOfBatch, shuffle = True)
loaderUsedForTestingPurpose = sampleData.DataLoader(setForTesting, batch_size = sizeOfBatch, shuffle = False)
# Training of the model
sampleEducbaModel = train(device, model, epochs, optimizerizer, functionForLossCalculation, loaderForTraining)
# Testing the working of model
test(device, sampleEducbaModel, loaderUsedForTestingPurpose)
if __name__ = = '__main__':
main()The output of the execution of the above code is as shown in the below image –
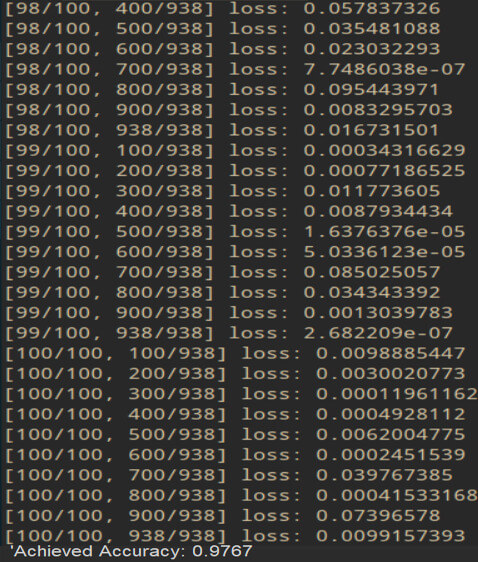
Conclusion
While training the neural network model, we can avoid the overfitting of data it by using early stopping where try to observe the loss of validation and training plots and accordingly decide on the basis of divergence in the value whether to terminate the training or not.
Recommended Articles
We hope that this EDUCBA information on “PyTorch Early Stopping” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
