Updated April 5, 2023

Introduction to PyTorch One Hot Encoding
The following article provides an outline for PyTorch One Hot Encoding. PyTorch provides different types of functionality to implement deep learning, in which one hot() is one of the functions that PyTorch provides. Basically, one hot() function is used to convert the class indices into a one-hot encoded target value. In machine learning, sometimes we need to convert the given tensor into a one-hot encoding; at that time, we can use one hot() as per requirement. We can also use the one-hot encoding() function if we have more than one dimension index in the tensor. Normally we can say that if we need to implement the deep learning algorithm efficiently, then we need to use such a function in our model.
PyTorch One Hot Encoding overviews
A one-hot encoding is a portrayal of unmitigated factors as parallel vectors. This initially necessitates that the unmitigated qualities be planned to whole number qualities. Then, at that point, every number value is addressed as a parallel vector that is each of the zero qualities aside from the list of the number, which is set apart with a 1. In other words, we can say that PyTorch has an one_hot() work for changing class records over to one-hot encoded targets. On the off chance that you have more than one angle in your gathering record tensor, one_hot() will encode names along with the last pivot. If you need to turn around the activity, changing a tensor from one-hot encoding to class lists, utilize the .argmax() strategy in the course of the last index. One hot encoding is a decent stunt to know about in PyTorch, however, realize that you don’t really require this assuming you’re fabricating a classifier with cross-entropy misfortune. All things considered, simply handling the class list focuses on the misfortune capacity, and PyTorch will deal with the rest.
A one-hot encoding permits the portrayal of downright information to be more expressive.
Many AI calculations can’t work with downright information straightforwardly. Instead, the classifications should be changed over into numbers. This is needed for both info and result factors that are absolute.
We could utilize a number encoding straightforwardly, rescaled where required. This might work for issues where there is a characteristic ordinal connection between the classifications, and thus the number of qualities, for example, marks for temperature ‘cold,’ ‘warm,’ and ‘hot.’
It creates a problem when there is no relationship and data representation that might be hurting to sort out some way to deal with the issue. For example, a model may be the names ‘canine’ and ‘feline.’
In these cases, we might want to give the organization a more expressive ability to get familiar with likelihood-like numbers for every conceivable name esteem. By using the above method, we can solve this problem, and on the other hand, we have one hot encoding function to resolve the problem.
Creating PyTorch one-hot encoding
Now let’s see examples to create one hot encoding() function as follows:
Example #1
Code:
import torch
import torch.nn.functional as Fun
A = torch.tensor([3, 4, 5, 0, 1, 2])
output = Fun.one_hot(A, num_classes = 7)
print(output)Explanation: In the above example, we try to implement the one hot() encoding function as shown here first; we import all required packages, such as a torch. After that, we created a tenor with different values, and finally, we applied the one hot() function as shown. The last result of the above execution we showed by utilizing the accompanying screen capture is as follows.
Output:

Now let’s see another example of one hot() function as follows.
Example #2
Code:
import torch
import torch.nn.functional as Fun
A = torch.rand(3, 14, 126)
output = Fun.one_hot(A.argmax(dim = 2), 126)
print(output)Explanation: In the above example, we try to implement the one hot() encoding function as shown here first; we import all required packages such as a torch. After that, we created a tenor by using the rand() function as shown, and finally, we applied the one hot() function with the argmax() function as shown. The last result of the above execution we showed by utilizing the accompanying screen capture is as follows.
Output:

Example #3
Code:
from numpy import argmax
i_string = 'welcome in one hot function'
print(i_string)
char_al = 'abcdefghijklmnopqrstuvwxyz '
character_to_integer = dict((c, i) for i, c in enumerate(char_al))
integer_to_character = dict((i, c) for i, c in enumerate(char_al))
integer_encoded = [character_to_integer[char] for char in i_string]
print(integer_encoded)
onehot_en = list()
for value in integer_encoded:
l = [0 for _ in range(len(char_al))]
l[value] = 1
onehot_en.append(l)
print(onehot_en)
invert = integer_to_character[argmax(onehot_en[0])]
print(invert)Explanation: In the above example, we try to implement the manual one-hot encoding. In this example, we first define the input string and the entire alphabet for possible input values. After that, we use one hot encode () function as shown. Finally, we print the inverse of the input string by using the argmax () function. The last result of the above execution we showed by utilizing the accompanying screen capture is as follows.
Output:

Now let’s see an example of scikit learn with one hot encode as follows.
Example #4
Code:
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
input = ['not', 'yes', 'not', 'not', 'yes', 'yes', 'not', 'not']
value = array(input)
print(value)
l_encoder = LabelEncoder()
i_encoded = l_encoder.fit_transform(value)
print(i_encoded)
o_encoder = OneHotEncoder(sparse=False)
i_encoded = i_ncoded.reshape(len(i_encoded), 1)
o_encoded = o_encoder.fit_transform(i_encoded)
print(o_encoded)
inverted = l_encoder.inverse_transform([argmax(o_encoded[0, :])])
print(inverted)Explanation: In the above example, we try to implement the one hot() function with scikit learns, as shown. This example shows that we use an integer encoder and binary encoder. The last result of the above execution we showed by utilizing the accompanying screen capture is as follows.
Output:
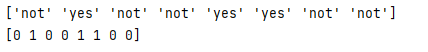
So in this way, we can use one hot() encode function as per our requirement.
Conclusion
We hope from this article you learn more about the PyTorch one-hot encoding. From the above article, we have taken in the essential idea of the PyTorch one-hot encoding, and we also see the representation and example of the PyTorch one-hot encoding. Furthermore, we learned how and when we use the PyTorch one-hot encoding from this article.
Recommended Articles
We hope that this EDUCBA information on “PyTorch One Hot Encoding” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
