Updated April 7, 2023

Introduction to PyTorch VAE
In PyTorch, we have different types of functionality for the user, in which that vae is one of the functions that we can implement in deep learning. The vae means variational autoencoder, by using vae we can implement two different neural networks, encoder, and decoder as per our requirement. Just imagine we have a large set of the dataset and inside that each and every image consists of hundreds of pixels that mean it has hundreds of dimensions. So in deep learning sometimes we need to reduce the dimension of an image so at that time we can use vae to increase the high dimensional data.
What is PyTorch vae?
Envision that we have a huge, high-dimensional dataset. For instance, envision we have a dataset comprising thousands of pictures. Each picture consists of many pixels, so every information point has many aspects. The complex speculation expresses that genuine high-dimensional information really comprises low-dimensional information that is installed in the high-dimensional space. This implies that, while the genuine information itself may have many aspects, the hidden design of the information can be adequately depicted utilizing a couple of aspects.
This is the inspiration driving dimensionality decrease methods, which attempt to take high-dimensional information and undertake it onto a lower-dimensional surface. For people who picture most things in 2D (or at times 3D), this typically implies extending the information onto a 2D surface. Instances of dimensionality decrease methods incorporate head part investigation (PCA) and t-SNE.
Neural organizations are regularly utilized in the regulated learning setting, where the information comprises sets (A, B) furthermore the organization learns a capacity f: A→B. This setting applies to both relapses (where B is a ceaseless capacity of A) furthermore characterization (where B is a discrete mark for A). Notwithstanding, neural organizations have shown extensive power in the solo learning setting, where information simply consists of focuses A. There are no “objectives” or “marks” B. All things considered, the objective is to learn and comprehend the construction of the information. On account of dimensionality decrease, the objective is to track down a low-dimensional portrayal of the information.
PyTorch vae
The standard autoencoder can have an issue, by the way, that the dormant space can be sporadic. This implies that nearby focuses in the dormant space can create unique and inane examples over noticeable units.
One answer for this issue is the presentation of the Variational Autoencoder. As the autoencoder, it is made out of two neural organization designs, encoder, and decoder.
Be that as it may, there is an alteration of the encoding-unraveling process. We encode the contribution as a circulation over the dormant space, rather than thinking about it as a solitary point. This encoded conveyance is picked to be ordinary so that the encoder can be prepared to return the mean network and the covariance framework.
In the subsequent advance, we test a point from that encoded circulation.
After, we can decipher the inspected point and work out the remaking blunder
We backpropagate the recreation mistake through the organization. Since the testing system is a discrete cycle, so it’s not persistent, we want to apply a reparameterization stunt to make the backpropagation work.
In vae we also need to consider the loss function as follows.
The loss for the VAE comprises of two terms:
The initial term is the reconstruction term, which is contrasting the information and comparing reproduction.
An extra term is the regularization term, which is likewise called the Kullback-Leibler difference between the dispersion returned by the encoder and the standard typical appropriation. This term goes about as a regularizer in the dormant space. This makes the circulations returned by the encoder near-standard typical dissemination.
Examples
Now let’s see different examples of vae for better understanding as follows.
For implementation purposes, we need to follow the different steps as follows.
Step 1: First we need to import all the required packages and modules. We will utilize the torch.optim and the torch.nn module from the light bundle and datasets and changes from torchvision bundle.
Step 2: After that, we need to import the dataset. we need to load the required dataset into the loader with the help of the DataLoader module. We can use the downloaded dataset for image transformation. Utilizing the DataLoader module, the tensors are stacked and fit to be utilized.
Step 3: Now we need to create the autoencoder class and that includes the different nodes and layers as per the problem statement.
Step 4: Finally, we need to initialize the model and create output.
Code:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
img_tran = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.6], [0.6])
])
datainfo = MNIST('./data', transform=img_tran, download=True)
class autoencoder_l(nn.Module):
def __init__(self):
super().__init__()
self.encoder_fun = nn.Sequential(
nn.Linear(24 * 24, 124),
nn.ReLU(True),
nn.Linear(64, 32),
nn.ReLU(True),
nn.Linear(32, 10),
nn.ReLU(True),
nn.Linear(10, 2))
self.decoder_fun = nn.Sequential(
nn.Linear(10, 2),
nn.ReLU(True),
nn.Linear(32, 10),
nn.ReLU(True),
nn.Linear(64, 32),
nn.ReLU(True),
nn.Linear(124, 24 * 24),
nn.Tanh())
def forward(self, A):
lat = self.encoder_fun(A)
A = self.decoder_fun(lat)
return A, lat
n_ep = 8
b_s = 124
l_r = 2e-2
dataloader = DataLoader(datainfo, b_s=b_s, shuffle=True)
model = autoencoder_l()
model.cuda()
crit = nn.MSELoss()
opti = torch.optim.AdamW(
model.parameters(), lr=l_r)
for ep in range(n_ep):
for info in dataloader:
image, label_info = info
image = imahe.view(image.size(0), -1).cuda()
result, lat = model(image)
loss = crit(result, image)
loss.backward()
opti.step()
opti.zero_grad()
print(Result, 'epoch_n [{epoch + 1},{n_ep}], loss of info:{loss.info.item()}')Explanation
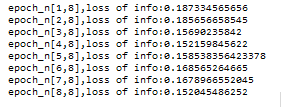
In an example first, we import all required packages after that we download the dataset and we extract them. Here we use MINSET dataset for image extraction. After that, we write the code for the training dataset as shown. The final result of the above program we illustrated by using the following screenshot as follows.
Conclusion
We hope from this article you learn more about the PyTorch vae. From the above article, we have learned the basic concept as well as the syntax of the PyTorch vae and we also see the different examples of the PyTorch vae. From this article, we learned how and when we use the PyTorch vae.
Recommended Articles
We hope that this EDUCBA information on “PyTorch VAE” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
