Updated March 24, 2023
Introduction to RabbitMq Architecture
RabbitMQ is one of the most widely used open-source message brokers. It was originally based on the Advanced Message Queuing Protocol (AMQP). Later on, it has been modified to support Message Queuing Telemetry Transport (MQTT), Streaming Text Oriented Messaging Protocol (STOMP), and several other common protocols. In this topic, we are going to learn about RabbitMQ Architecture.
The main components of RabbitMQ are Producer, Exchange, Queue and Consumer. These are discussed in detail in the next section.
RabbitMq Architecture
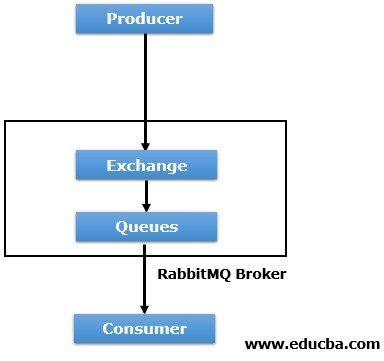
RabbitMQ comprises of the following parts:
1. Producer
A producer pushes messages to exchanges. Messages should not be pushed at a higher than that can be processed by the Consumers. It is also responsible for generating the routing keys.
2. Exchange
It is basically a routing rule for the messages. Now, for a message to travel to a queue or different exchange from the producers, it requires binding. Now different kinds of exchanges require different bindings. Some of the exchanges are:
Fanout Exchange
It routes messages to all the available queues without discrimination. A routing key, if provided, will simply be ignored. This exchange is useful for implementing the pub-sub mechanism. While using this exchange, different queues are allowed to handle messages in their own way, independently of others.
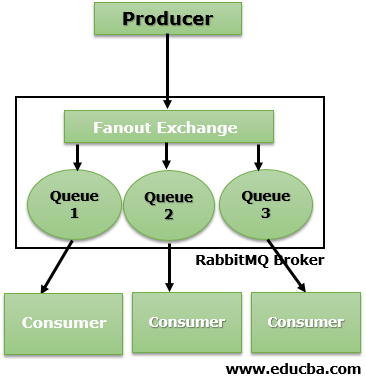
As shown in the diagram above, the messages are routed to all the queues.
Direct Exchange
It routes messages on the basis of the routing key that the message carries. Routing Key is a short string generated by the Producer of the messages. The messages are routed to the exchanges/queues having the Binding Key that exactly matches the routing key.
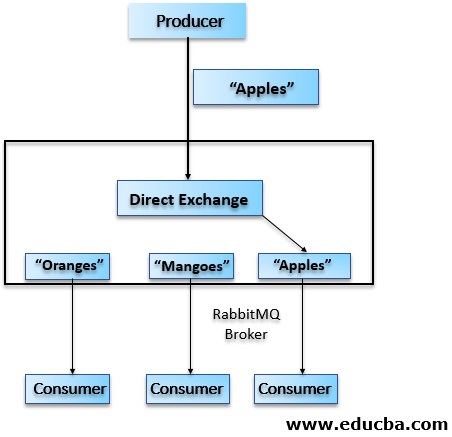
As shown in the above diagram, the routing key is “Apples” and the messages are delivered to only one queue whose binding key is “Apples”
Topic Exchange
It routes messages on the basis of the complete or partial match with the routing key. In this case, the messages are published in such a way that the routing key consists of dot-separated series of words (like word1.word2.word3 ). Patterns can have an asterisk(*) that can match word at a certain location of the routing key or a hash that can match zero or more words.
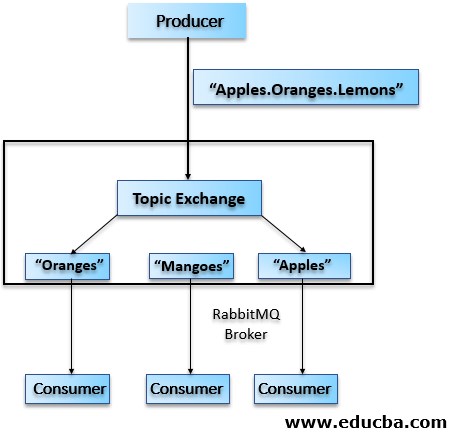
In the above case, the routing key is “Apples.Oranges.Lemons” and the messages are routed to two queues: one having pattern as “*.Oranges.*” and others with the pattern “Apples.*”.
Headers exchange
Messages are routed based on the message headers. The message headers are matched against headers specified by binding queue and if matched then messages are sent to that queue. A special argument called “x-match” is added in the binding between an exchange and a queue. Now, this takes can have two values “any” or “all”, where “all” is the default value. “all” signifies that all header pairs must match, whereas “any” signifies that match must occur with at least one of the header pairs.
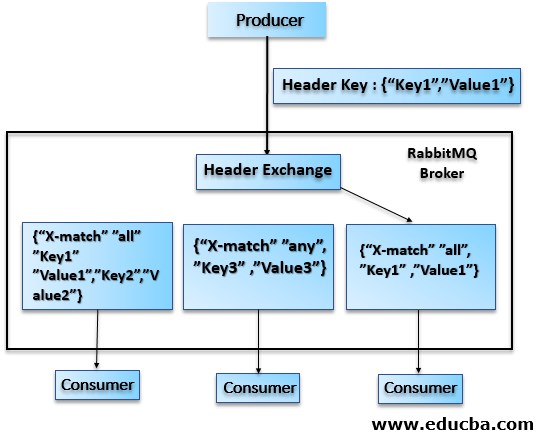
In the above case, messages are routed to one queue for which the “x-match” is set as “all” and all of its key-value pairs (only 1 in this case) match with that in the message header.
Consistent Hashing
This type of exchange hash either the routing key or the message header in order to route the messages to one queue only. This finds useful in cases where we have to guarantee that messages are Consumed in the same order as published.
3. Queue
It’s a buffer to store messages. Queues are named so that reference by applications is easier. Applications can decide the queue names or may ask the broker to generate them. Queue names can be up to 255 bytes of UTF-8 characters and cannot start with ‘amq.’ because such names are reserved by the broker for internal use. A queue is defined by the following properties:
- Name
- Durable (This queue can survive a broker restart and is achieved by persisting the queue to a disk. This doesn’t imply that messages are also durable)
- Exclusive (Used by only one connection and gets deleted once that connection closes. If any other connection tries to access an Exclusive queue, it would throw a channel-level exception called RESOURCE_LOCKED)
- Auto-Delete (The queue gets deleted automatically when the last consumer that subscribed to it unsubscribes)
- Arguments (This is optional; Most of these arguments can be dynamically altered even after the queue has been declared. These can be set in two ways: a) To a group of queues using policies and b) On a per queue basis and the arguments are set when the client declares the queue)
Prior to using a queue, it needs to be declared. Declaring will cause a queue to be created if doesn’t already exist. Now, in case the queue already exists, then declaring will cause no effect if the attributes specified are the same as existing otherwise it will throw a channel-level exception called PRECONDITION-FAILED.
4. Consumer
It reads messages from the queues. Each consumer can set something called a pre-fetch limit (Otherwise known as QoS limit). This number indicates the number of unacknowledged messages the Consumer can handle at an instance.
Conclusion
RabbitMQ is widely used in the industry as it supports complex-routing. It has been adopted by many big companies/organizations like JP Morgan, NASA (for Nebula Cloud Computing) and Google. In fact, it also finds usage in India’s Aadhar Project, which is the largest biometric database in the world.
Recommended Articles
This is a guide to RabbitMQ Architecture. Here we discuss the basic meaning and main components of RabbitMQ such as Producer, Exchange, Queue and Consumer. You may also have a look at the following articles to learn more –

