Updated February 18, 2023

Introduction to Redis Pipeline
Redis pipeline is a technique used to improve performance when issuing multiple types of commands at the same time without waiting for each individual command’s response. Multiple redis is used to support the redis pipeline. Redis is nothing but a TCP server that uses the client-server model and the protocol of request and response that was defined in redis.
Key Takeaways
- The redis pipeline allows the client to send multiple requests to the redis server without waiting for a response; it will then read the response from the server.
- Basically, redis is a TCP server that supports protocol or response and request, and the request is completed in two steps.
What is Redis Pipeline?
Redis pipelining refers to the feature that allows us to send multiple commands to the redis server. We can create batch commands and run them on servers in parallel while sending commands and receiving responses from pipelines. The purpose of pipelining is to improve the performance and protocol of redis. We are organizing all commands first on the client side, which reduces the time required to send the request to the server for processing and returning the response to the client.
Redis is nothing but the remote dictionary server. It is open source and contains the memory data structure that we are storing in the database. Redis responds in milliseconds and supports multiple requests per second for real-time applications.
How does Redis Pipeline Work?
The py cluster pipeline is used in redis to achieve high efficiency. Basically, transaction support is turned off in the redis py cluster. We are using the pipeline to avoid extra network trips and ensure atomicity. In redis, py cluster queues all commands inside the client until they are executed. We must first install the redis pipeline in our system before we can use it. In the following example, we install redis-serve in our system as follows. First, we are downloading the libraries and extract the same in our system. In the below example, we can see that we have first downloaded the redis and then extracted the package of the redis server as follows.
Code:
wget http://download.redis.io/redis-stable.tar.gztar -xvzf redis-stable.tar.gz redis-stable/Output:
After extracting the downloaded package now in this step, we are installing the redis in our server as follows.
Code:
cd redis-stable/make && make installOutput:
After installing the server, we need to start the same by using the below command. In the below example, we can see that the redis server is started in standalone mode the port of the server is 6379 and PID is 6290.
Code:
redis-serverOutput:
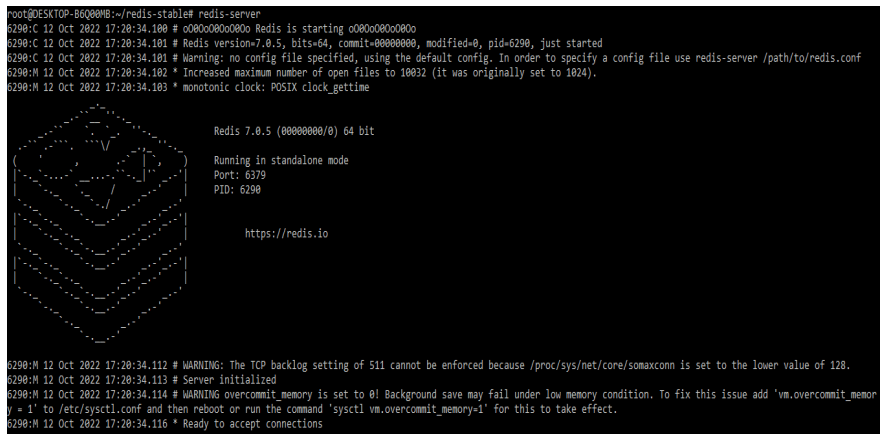
The request and response are implemented for the server so that we can easily implement the process of new requests which was read from the old response. By using this way it’s possible for sending multiple commands to the server without waiting for the server to send the reply. Redis is supported for pipelining. In the below example, we can see that we are sending three requests to the server and the server is sending three responses to us.
Code:
(printf "ping \r\n\t ping \r\n\t ping \r\n"; sleep 5) | nc localhost 6379Output:

Redis pipelining is used not only to reduce latency, which is associated with cost but also improve the number of operations performed on the redis server. This occurs only when pipelining is used, as each command is not costly for socket I/O. We can use syscall’s read and write methods.
Benefits of Redis Pipeline
- Performance: Basically, all of Redis’ data is stored in memory, allowing for low latency and high throughput data access. Unlike traditional databases, memory storage does not require a trip to the disc, resulting in engine latency in microseconds.
- Data storage: The in-memory data store facilitates faster server response. The result is that it will read and write operations faster, and it will support millions of operations per second.
- Flexible data structures: Redis contains multiple data structures as follows:
-
-
- String
- Lists
- Sets
- Sorted sets
- Hashes
- Bitmaps
- HyperLogLogs
- Stremas
- Geospatia
-
- Simplicity and ease of use: Redis enables us to write complex code with easy and simple lines. By using redis we can write lines of code to access and store the data in our applications. Redis supports many languages, including java, python, ruby, and others.
- Replication and persistence: Redis will use a primary replica architecture and support asynchronous replication, allowing us to replicate data across multiple servers. This will provide high read performance and faster data recovery if the primary server fails. Redis provides point-in-time recovery.
- Open source: Redis is an open-source database that is supported by a community that was vibrant.
- Popularity: Redis is very popular in storing data. The speed of redis is high compared to others.
- Caching: The caching of data is high compared to the other databases which we are using.
- Memory structure: Redis stores all the data on memory, so the speed of data extraction is high.
- High availability: Redis is offering the primary replica architecture which contains a single primary node. This allows us to build a highly available solution for providing consistent solutions.
- High scalability: At the time of adjusting the cluster size, there are various options available to scale up and scale down the redis cluster.
- Easy to use: Redis server and redis pipeline are very easy to use. We can easily use the server of redis.
Examples of Redis pipeline
In the below example, we are giving the request to the redis server 4 times as follows.
Code:
(printf "ping \r\n\t ping \r\n\t ping \r\n\t ping \r\n"; sleep 5) | nc localhost 6379Output:

Now we are passing unknown values and arguments, so it gives the unknown command error as follows.
Code:
(echo -en "Redis Pipeline\r\n PING\r\n PING\r\n value\r\nGET key\r\nINCR new"; sleep 1) | nc localhost 6379Output:

Now we are using the echo command to print the output.
Code:
(echo -en "PING\r\n SET sssit pipeline\r\n GET sssit\r\n INCR visitor"; sleep 5) | nc localhost 6379Output:

We are using the echo command to print the output also we are setting the sleep time as 15.
Code:
(echo -en "PING\r\n SET sssit pipeline\r\n GET sssit\r\n INCR visitor"; sleep 15) | nc localhost 6379Output:

Conclusion
Redis pipelining refers to the feature that allows us to send multiple commands to the redis server. Redis pipeline is a technique used to improve performance when issuing multiple types of commands at the same time without waiting for each command’s response.
Recommended Articles
This is a guide to Redis pipeline. Here we discuss the introduction, how does redis pipeline work? benefits and examples. You may also have a look at the following articles to learn more –
