Updated March 8, 2023

Introduction to Redshift regex
Redshift regex is used to perform the matching of the pattern with the help of regular expressions which is specified as per our requirement. In amazon redshift the matching of patterns in the strings is performed by searching the substring occurrence by using regular expressions, LIKE operator or by using the SIMILAR TO operator which works the same as that of regex that is regular expressions or using the POSIX regular expressions.
In this article, we will study the regex in redshift used for pattern matching, study the syntaxes of each of them and learn how they work and can be implemented in Redshift with the help of certain examples.
Syntax:
The syntax of the SIMILAR TO operator –
SELECT column and expressions FROM table name WHERE expression SIMILAR TO regex;
The syntax of the LIKE operator –
SELECT column and expressions FROM table name WHERE expression LIKE regex;
The syntax of the REGEX_SUBSTR function –
SELECT column and expressions FROM table name WHERE expression REGEX_SUBSTR (source string, regex or pattern [, index that is position [, occurrence [, arguments or parameters]]);
Working and terminologies explanation
In all the above-mentioned syntaxes, the terminologies used are discussed one by one here –
Regex – This stands for regular expression that helps in specifying the pattern that we are trying to match and find in the source string or column value or the expression which involves performing multiple mathematical or logical operations on the column value or string literals. The regex contains the special symbols which have special meanings such as * stands for zero or more occurrence of any characters. The % stands for only one occurrence of any character.
Table name – This is the name of the table from which you will be retrieving the column names or expression values whose regular expression is to be checked.
Expression – This is the derived value after performing mathematical or logical operations on the column values or string literals of the table. This operation may involve sum, average, max, min, and other aggregate operators or logical operations such as AND, OR, and NOT.
Source string – This is the source string in which we want to scan the presence of the matching pattern with regular expressions specified in the command. The source string can be string literal or any column name whose value should be I string datatype or at least compatible with the string data type.
Pattern or regex – This is the regular expression that is abiding by the standards of SQL and is a string literal value.
The index that is position – This is the index +1 value that is the position that will be considered for scanning the matching regular expression. From here onwards the match is made and searched as per the regular expression inside the source string. This is a positive integer value. This position is character-based which means that even if there are multi-byte characters they are treated as a single character while scanning as a position is not byte-based. When not specified the default value of position is 1 as the scanning begins from the first character of the source string. If we specify the value of position such that it has a value greater than the length of the source string then a blank (“”) empty string is what we get in the output.
Parameters or arguments –These are the values that can help in giving extra information about how we should perform the pattern matching. It is a string literal having values either c, I, or e each one having its own significance. When I am specified it means that the pattern matching with regular expression should be done in case–insensitive format. In the case of c, the pattern matching is case sensitive and this is the default value when any or the argument or parameter is not specified. In the case of e what we mean is to use a subexpression for extracting the substring from the source string.
Occurrence – This helps in specifying the occurrence of the pattern that is to be used while scanning and is a positive integer. By default, the value of occurrence is set to 1 when not specified and the REGEXP_SUBSTR () function ignores the first occurrence of -1 matches. In case we specify this value less than 1 or greater than the number of characters in the string to be scanned then a NULL value is returned as the result as no search is made.
The LIKE operator is used for string comparison and matching the appropriate occurrence of the specified pattern in a regular expression. The wildcard characters discussed above that is % and _ used for multiple or single occurrences of characters at that position are used with LIKE. The whole string is scanned for pattern matching with regular expression. The SIMILAR TO is same as LIKE operator and both perform case-sensitive entire string match. The ILIKE operator performs case insensitive match.
Examples
Let us now study the implementation of all the three operators and functions discussed above with the help of examples. We have two tables named educba_articles and educba_writers having the contents as displayed in the output of the following SQL queries –
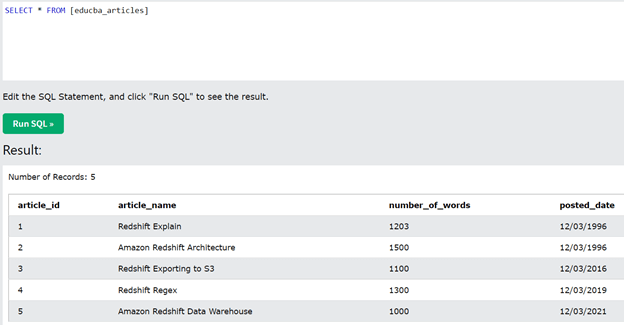
SELECT * from educba_articles;
The output of the above query statement is as shown in the below image –
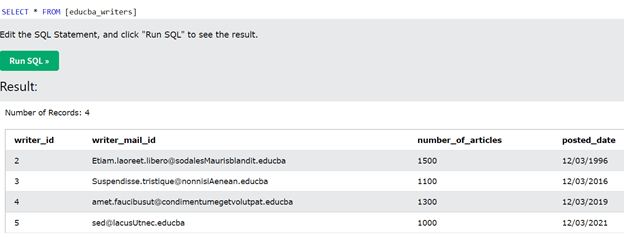
SELECT * from educba_writers;
The output of the above query statement is as shown in the below image –
Example #1
SIMILAR TO operator example –
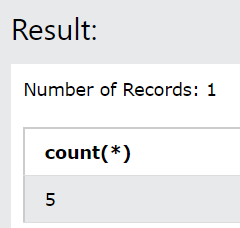
select count (*) from educba_articles where article_name SIMILAR TO '%(Redshift|Amazon) %';
The output of the above query statement is –
Example #2
LIKE operator example –
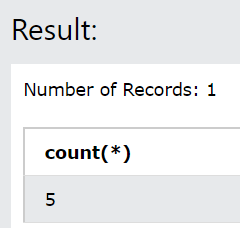
select count (*) from educba_articles where article_name LIKE '%Redshift%' OR article_name LIKE '%Amazon%';
The output of the above query statement is –
Example #3
REGEX_SUBSTR () function example –
SELECT writer_mail_id, regexp_substr(email,'@[^.]*')
FROM educba_writers
ORDER BY writer_id LIMIT 4;
The output of the above query statement is –

Conclusion – Redshift regex
The Redshift regular expression is used for pattern matching of the strings and there are many operators and functions that we can use for doing the same in Redshift. Some of them are LIK operator, SIMILAR TO operator, and REGEX_SUBSTR () function.
Recommended Articles
This is a guide to Redshift regex. Here we discuss the regex in redshift used for pattern matching, study the syntaxes of each of them and learn how they work. You may also have a look at the following articles to learn more –

