Updated May 12, 2023

Introduction to Redshift ROW_NUMBER() Function
Redshift row_number() function usually assigns a row number to each row by means of the partition set and the order by clause specified in the statement. If the partitioned rows have the same values then the row number will be specified by order by clause.
ROW_NUMBER() OVER ( [PARTITION BY column_partition_expression, ... ]
ORDER BY sort_column_expression [ASC | DESC], ... )
Here in the above syntax, we can say that based on the partition by expression the row sets are divided for the result set of the partition by expression the function will be applied.
Order by is used to logically sort order of the rows in each partition either in ascending or descending order.
Syntax:
ROW_NUMBER() OVER ( [PARTITION BY column_partition_expression, ... ]
ORDER BY sort_column_expression [ASC | DESC], ... )
The return type of the row_number function is ‘BIG INT’
Arguments of the above syntax:
( )
The function takes no arguments, but the empty parentheses are required.
OVER
The window clauses for the ROW_NUMBER function.
PARTITION BY partition_expression
It can be Optional. In ROW_NUMBER function One or more expressions can be defined in partition by.
ORDER BY sort_expression
It can be Optional. Order by uses the entire table if no partition by is specified.
How row_number() function work in Redshift?
Let us create a table and apply the Rank function to see how its working:
create table row_number_function
(
Product_name Varchar(10),
Sale_quantity int
);
Now let us insert few duplicated values as below and apply rank on it.
insert into row_number_function values ('Product 1', 10);
insert into row_number_function values ('Product 1' , 20);
insert into row_number_function values ('Product 1', 30);
insert into row_number_function values ('Product 2', 10)
insert into row_number_function values ('Product 2', 10)
insert into row_number_function values ('Product 2', 20)
insert into row_number_function values ('Product 3', 10)
insert into row_number_function values ('Product 3', 20)
insert into row_number_function values ('Product 3', 40)
Now let us select the above table.
SELECT * FROM row_number_function;
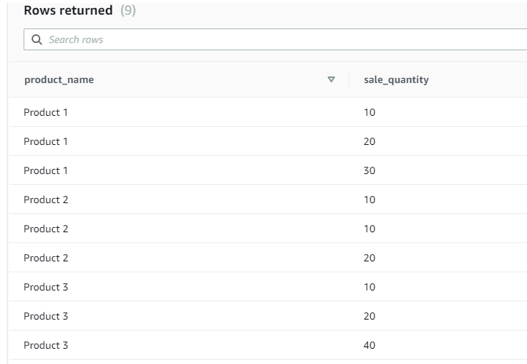
The above statement returns all the values in the table.
In the output of the table row_number_function. Now let us apply the row_number() function on the “row_number_function“ table.
SELECT Product_name, sale_quantity
, ROW_NUMBER() OVER (PARTITION BY product_name ORDER BY sale_quantity) as ROW_NUMBER_VALUE
FROM row_number_function;
Screenshot for the same:
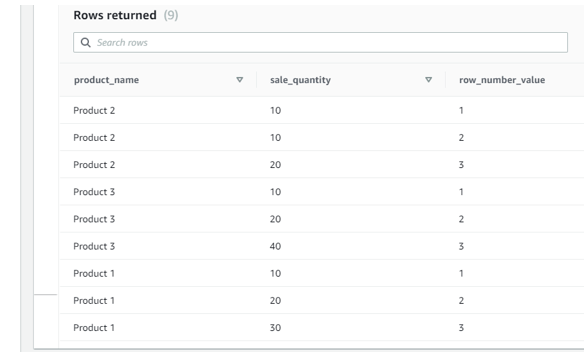
Here in the above output, you could see that the row number as been given based on the partition by column of ‘product_name’ and order by ‘Sale_quantity’.
Now let us only apply only the order by on the “alphabet” column without any partition applied. Let us check the output and difference same.
SELECT product_name, sale_quantity
, ROW_NUMBER() OVER ( ORDER BY sale_quantity) as ROW_NUMBER_VALUE
FROM row_number_function;
Screenshot for the same:
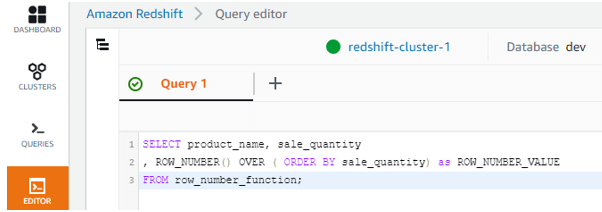
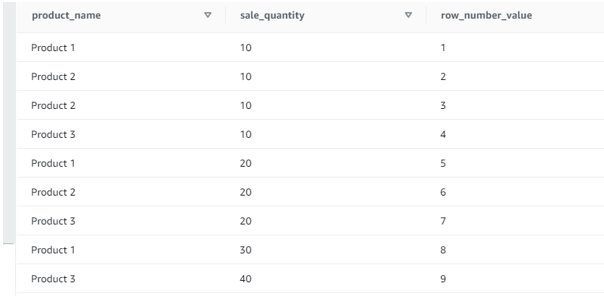
In the above output as there is no partition by expression given. The row number will be given based on the order by expression.
SELECT product_name, sale_quantity
, ROW_NUMBER() OVER ( PARTITION BY sale_quantity) as ROW_NUMBER_VALUE
FROM row_number_function;
Screenshot for the above statement output:
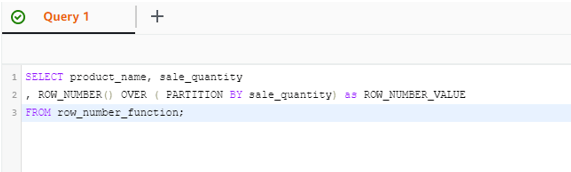
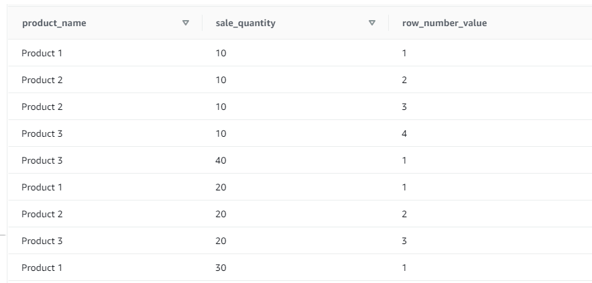
Now in the above output only the partition by has been applied on the basis of the column ‘sale_quantity’ the row number will be ascending order by default and consider the partition by expression.
Example
Now let us consider a real-time example and apply the ROW_NUMBER function and check for the output:
Let us create the table “CUST_DATA” with columns cust_id, cust_name, cust_address, cust_phone, cust_salary as below:
create table CUST_DATA
(
Cust_id int,
cust_N varchar(20),
cust_A varchar(20),
cust_P varchar(10),
cust_S int );
Let us insert few rows in the above table as below and apply the rank function:
insert into CUST_DATA values (1, 'Sam S', 'USA', '9987956479', 45110 );
insert into CUST_DATA values (2, 'Fred F', 'UK', '9872367534', 95220 );
insert into CUST_DATA values (3, 'Will W', 'Germany', '9679854678', 85330 );
insert into CUST_DATA values (4, 'Ben B', 'London', '8879812345', 45098 );
insert into CUST_DATA values (5, 'William W', 'rome', '7879809876', 95980 );
insert into CUST_DATA values (6, 'Bentley B', 'Italy', '7877845678', 95090 );
insert into CUST_DATA values (7, 'Sony S', 'USA', '8979800998', 75123 );
insert into CUST_DATA values (8, 'Sian S', 'USA', '6579899887', 65345 );
insert into CUST_DATA values (9, 'Shames S', 'London', '0979809890', 43768 );
insert into CUST_DATA values (10, 'Harry H', 'USA', '9877890876', 56789 );
select * from CUST_DATA;
Screenshot of the output:
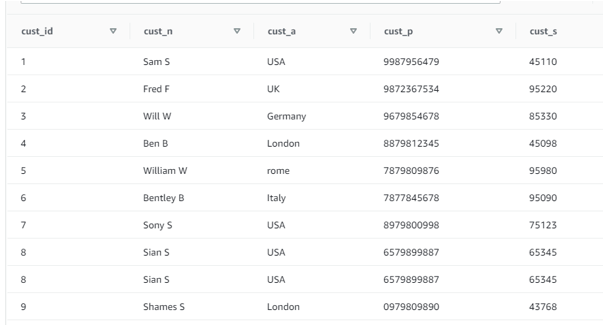
Now let us apply row number function in the table “CUST_DATA”.
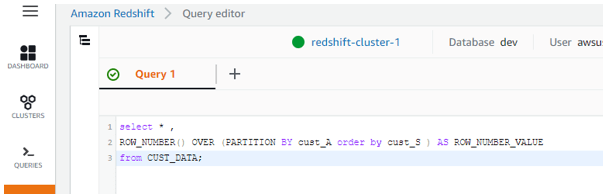
select *,
ROW_NUMBER() OVER (PARTITION BY cust_a order by cust_s) AS ROW_NUMBER_VALUE
from CUST_DATA;
Output:
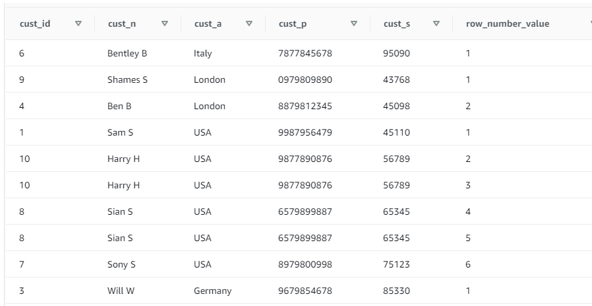
| cust_id | cust_n | cust_a | cust_p | cust_s | row_number_value |
| 6 | Bentley B | Italy | 7877845678 | 95090 | 1 |
| 9 | Shames S | London | 0979809890 | 43768 | 1 |
| 4 | Ben B | London | 8879812345 | 45098 | 2 |
| 1 | Sam S | USA | 9987956479 | 45110 | 1 |
| 10 | Harry H | USA | 9877890876 | 56789 | 2 |
| 10 | Harry H | USA | 9877890876 | 56789 | 3 |
| 8 | Sian S | USA | 6579899887 | 65345 | 4 |
| 8 | Sian S | USA | 6579899887 | 65345 | 5 |
| 7 | Sony S | USA | 8979800998 | 75123 | 6 |
| 3 | Will W | Germany | 9679854678 | 85330 | 1 |
Screenshot is below:
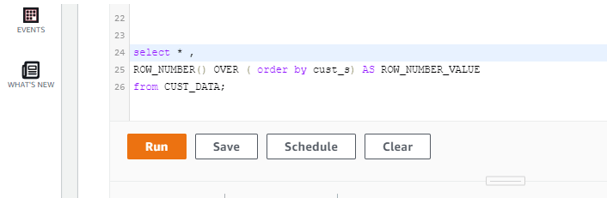
Now let us apply row number function in the table “CUST_DATA” without any partition by.
select * ,
ROW_NUMBER() OVER ( order by cust_s) AS ROW_NUMBER_VALUE
from CUST_DATA;
Screenshot for the above output:
select *,
ROW_NUMBER() OVER (PARTITION BY cust_address ) AS ROW_NUMBER_VALUE
from CUST_DATA;
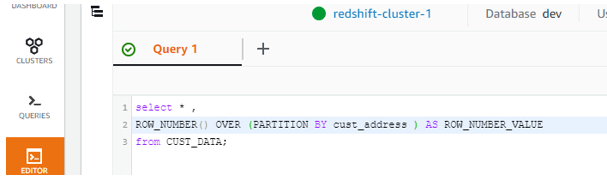
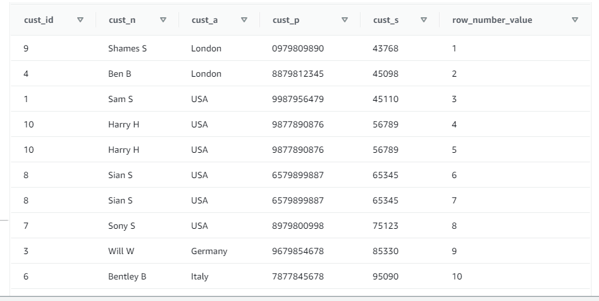
Here we have given only the partition by and not the order by. So the ordering will be done by default of the ascending of cust_address column.
Recommended Articles
This is a guide to Redshift Row_NUMBER(). Here we discuss the Introduction, How row_number() function work in Redshift? and examples with code implementation. You may also have a look at the following articles to learn more –

