Updated July 20, 2023
Introduction to Python Regular Expressions
Regular expressions, commonly referred to as regex, are dynamic tools used for the manipulation and pattern matching of textual data.
They provide a concise and flexible way to search, extract, and manipulate strings based on specific patterns.
Table of Content
- Python Regular Expressions
- Regular Expression Syntax
- Pattern Matching
- Metacharacters
- Creating Python RegEx Patterns
- RegEx Functions and Methods in Python
- Python RegEx Modifiers
- Python Regex Metacharacters and Escaping
- Character Classes and Character Sets
- Quantifiers and Grouping in Python Regex
- Anchors and Word Boundaries
- Lookahead and Lookbehind in Python Regex
- Flags and Modifiers
- Examples and Use Cases
Regular Expression Syntax
Regular expressions in Python are represented as strings and combine normal characters and special symbols called metacharacters. These metacharacters have special meanings and are used to define the patterns to be matched.
Regular expressions can be combined through concatenation (AB) to form new expressions. When strings p and q match A and B, respectively, the concatenation pq matches AB. Considerations like precedence, boundaries, and group references impact this behavior. These principles simplify constructing complex expressions from simpler ones.
Pattern Matching
Pattern matching is the core functionality of regular expressions. It involves searching for specific patterns or sequences of characters within a given text. Regular expressions enable you to define complex patterns using a combination of characters and metacharacters to match against a target string.
Metacharacters
Metacharacters are special symbols in regular expressions that have predefined meanings. They allow you to specify rules and constraints for pattern matching. Some commonly used metacharacters include:
- ‘.’ (dot): Matches single characters except for a new line.
- ‘^’ (caret): Matches the start of a string.
- ‘$’ (dollar sign): Matches the string’s end.
- ‘*’ (asterisk): Matches occurrences of the preceding group or character.
- ‘+’ (plus): Matches one or more occurrences of the preceding group or character.
- ‘?’ (question mark): Matches zero or one occurrence of the preceding group or character.
- ‘|’ (pipe): Acts as an OR operator, allowing multiple patterns to be specified.
- ‘[‘ and ‘]’ (square brackets): Defines a character class, matching any single character within the brackets.
- ‘/’ (backslash): Escapes metacharacters to treat them as literal characters.
These are just a few examples of metacharacters commonly used in regular expressions. Understanding their usage and combinations will allow you to build powerful and precise patterns for pattern matching in Python using regular expressions.
By leveraging regular expressions and their metacharacters, you can perform various tasks such as validating input, extracting specific information from a text, replacing patterns, and much more. Regular expressions are widely used in text processing, data validation, web scraping, and other textual data applications.
Creating Python RegEx Patterns
Detailed explanation to create a regex pattern:
Literal Characters
In regular expressions, literal characters refer to specific characters matched exactly as they appear. For example, the pattern “cat” will only match the sequence of letters “cat” in the given text. You can use literal characters to create precise matches in your regular expressions.
Example: To match the word “hello” in a text, you can use the regular expression pattern “hello”.
Character Classes
Character classes in regular expressions allow you to define a set of characters that can match a single character in the given text. They are enclosed within [ ] square brackets. For example, the pattern “[aeiou]” matches any vowel character. Character classes provide flexibility in pattern matching by allowing you to specify a range of characters or exclude specific characters from matching.
Example: The regex pattern “[0-9]” matches any digit character.
Quantifiers
Quantifiers in regular expressions control the number of times a character or a group of characters can occur in the given text. They specify how many repetitions or ranges are allowed. For instance, the quantifier “+” indicates that the preceding character or group must appear once or twice.
Example: The regular expression pattern “a+” matches one or more occurrences of the letter “a” in the text.
Anchors
Anchors in regular expressions are used to match positions rather than characters. They allow you to specify where a pattern should start or end in the text. The caret symbol “^” is used as the start anchor, and the dollar symbol “$” is used as the end anchor.
Example: The regular expression pattern “^Hello” matches the word “Hello” only if it appears at the beginning of a line.
Alternation
Alternation in regular expressions is represented by the vertical bar “|”. It allows you to specify multiple alternatives for matching. When encountered, it tries to match the expression before or after the vertical bar.
Example: The regular expression pattern “cat|dog” matches either “cat” or “dog” in the given text.
Grouping and Capturing
Grouping in regular expressions are denoted by enclosing a pattern within parentheses “( )”. It allows you to create logical units and apply quantifiers or alternations. Capturing groups extract and remember parts of the matched text for later use.
Example: The regular expression pattern “(ab)+” matches one or more occurrences of the sequence “ab” and captures it as a group.
By understanding and utilizing these various elements of regular expressions, you can construct powerful patterns for matching and manipulating text flexibly and precisely.
RegEx Functions and Methods in Python
Here are the RegEx functions and methods, including examples:
re.match()
This function attempts to match the pattern at the beginning of the string. It returns a match object if the pattern is found or None otherwise. It’s like knocking on the door of a house to see if it matches a specific blueprint.
Example
import re
pattern = r"apple"
text = "I love apples"
match_object = re.match(pattern, text)
if match_object:
print("Match found!")
else:
print("No match found!")Output:
![]()
re.search()
This function searches the entire string for a match to the pattern. It returns a match object if the pattern is found or None otherwise. It’s like searching for a hidden treasure in a room.
Example
import re
pattern = r"apple"
text = "I love apples"
match_object = re.search(pattern, text)
if match_object:
print("Match found!")
else:
print("No match found!")Output:
![]()
re.find all()
The purpose of this function is to provide a list of non-overlapping matches for a given pattern within the string. It’s like gathering a particular item’s instances in a collection.
Example
import re
pattern = r"apple"
text = "I love apples. Apples are delicious."
matches = re.findall(pattern, text)
print(matches)Output:
![]()
re.finditer()
This function provides an iterator that produces match objects for non-overlapping instances of the pattern within the string. It’s like having a spotlight that illuminates each occurrence of a specific item.
Example
import re
pattern = r"apple"
text = "I love apples. Apples are delicious."
match_iterator = re.finditer(pattern, text)
for match_object in match_iterator:
print(match_object)Output:
![]()
re.subn()
This function replaces all occurrences of the pattern in the string with a specified replacement string. It returns a tuple containing the modified string and the number of replacements made. It’s like performing a substitution in a text document and counting the changes.
Example
import re
pattern = r"apple"
replacement = "orange"
text = "I love apples. Apples are delicious."
modified_text, replacements = re.subn(pattern, replacement, text)
print(modified_text)
print(replacements)Output

re.split()
This method splits the string by the pattern occurrences and returns a list of substrings. It’s like cutting a cake along the defined pattern to get separate pieces.
Example
import re
pattern = r"\s+" # Matches one or more whitespace characters
text = "Hello World! How are you?"
substrings = re.split(pattern, text)
print(substrings)Output:
![]()
re.purge()
This function clears the regular expression cache. It removes all cached patterns, making the module forget all compiled regex patterns. It’s like erasing the memory of previously used patterns.
Example
import re
pattern = r"apple"
text = "I love apples"
re.match(pattern, text)
re.search(pattern, text)
re.purge() # Clearing the regex cache
# Attempting to match after purging the cache
match_object = re.match(pattern, text)
if match_object:
print("Match found!")
else:
print("No match found!")Output:
![]()
re.escape(pattern)
This function returns a string where all non-alphanumeric characters in the pattern are escaped with a backslash. It ensures that special characters are treated as literal characters. It’s like putting a protective shield on the pattern to avoid any special interpretation.
Example
import re
pattern = r"(apple)"
text = "I love apples"
escaped_pattern = re.escape(pattern)
match_object = re.search(escaped_pattern, text)
if match_object:
print("Match found!")
else:
print("No match found!")Output:
![]()
re.fullmatch()
This function attempts to match the pattern against the entire string. It returns a match object if the pattern fully matches the string or None otherwise. It’s like ensuring that the pattern perfectly fits the whole puzzle.
Example
import re
pattern = r"apple"
text = "apple"
match_object = re.fullmatch(pattern, text)
if match_object:
print("Full match found!")
else:
print("No full match found!")Output:
![]()
re.compile()
This function compiles a regular expression pattern into a regex object, which can be used for matching and searching operations. It’s like creating a custom tool for performing specific regex operations.
Example
import re
pattern = r"apple"
text = "I love apples"
regex = re.compile(pattern)
match_object = regex.search(text)
if match_object:
print("Match found!")
else:
print("No match found!")Output:
![]()
These examples glimpse various RegEx functions and methods’ functionalities and unique word usage. Experimenting with different patterns and texts will further enhance your understanding of regular expressions.
Python RegEx Modifiers
Here are some commonly used modifiers in regex:
- Case Insensitivity: In regular expressions, the “case insensitivity” modifier allows you to match patterns without distinguishing between uppercase and lowercase letters. It’s denoted by the letter ‘i’ and can be added to the end of the regular expression pattern using the syntax “/pattern/i”. For example, the pattern “/hello/i” would match “hello,” “Hello,” “HELLO,” and any other combination of case variations.
- Multiline Mode: The “multiline mode” modifier, represented by the letter ‘m’, alters the behavior of the caret (^) and dollar sign ($) anchors within a regular expression. When enabled using the “/pattern/m” syntax, the caret and dollar sign will match the start and end of each line rather than just the start and end of the entire input string. This is particularly useful when working with multiline text, allowing you to perform matches on individual lines instead of the entire block.
- Dot All Mode: The “dot all mode” modifier, denoted by the letter ‘s’, affects the behavior of the dot (.) metacharacter in regular expressions. By default, the dot matches any character except a new line. However, when the dot all mode is enabled using the “/pattern/s” syntax, the dot will match any character, including newline characters. This is useful when you want to match across multiple lines, such as when parsing a text block.
- Verbose Mode: In regular expressions, the “verbose mode” provides a way to write more readable and organized patterns by including comments and extra whitespace. It’s enabled using the ‘x’ modifier, and the pattern is defined as “/pattern/x”. With verbose mode, you can add comments using the ‘#’ symbol, which the regex engine will ignore. Additionally, you can use whitespace to break up your pattern into logical sections, improving the readability and maintainability of complex regular expressions.
These modifiers enhance the flexibility and functionality of regular expressions, allowing you to create more powerful and precise pattern matches for text processing and manipulation.
Python Regex Metacharacters and Escaping
Let’s explore the world of special metacharacters and the art of escaping, allowing you to wield these powerful tools with confidence and finesse.
Special Metacharacters
Here, we’ll cover some of the most commonly encountered special metacharacters and their functionalities, including.
The Dot (.)
- Usage: The dot metacharacter matches any character except a new line.
- Example: The regular expression “c.t” matches “cat,” “cut,” and “cot” but not “c\n\nt.”
The Caret (^)
- Usage: The caret metacharacter denotes the start of a line or the negation of a character class.
- Example: The regular expression “^hello” matches “hello” when it appears at the start of a line.
The Dollar Sign ($)
- Usage: The dollar sign metacharacter represents the end of a line or string.
- Example: The regular expression “world$” matches “world” when it appears at the end of a line.
The Pipe (|)
- Usage: The pipe metacharacter signifies alternation or logical OR.
- Example: The regular expression “cat|dog” matches either “cat” or “dog.”
Escaping Metacharacters
Escaping metacharacters is the art of rendering their literal interpretation instead of their special meaning. This section explores how to escape metacharacters to treat them as ordinary characters. Some commonly used metacharacters that require escaping include
The Backslash ()
- Usage: The backslash metacharacter is used to escape itself or other metacharacters, turning them into literal characters.
- Example: To match a literal dot, use the regular expression “example.com.”
The Square Brackets ([])
- Usage: Square brackets enclose character classes in regular expressions. To match a literal square bracket, escape it with a backslash.
- Example: To match the string “[hello]”, use the regular expression “hello”.
The Asterisk (*)
- Usage: The asterisk metacharacter denotes zero or more occurrences of the preceding character or group.
- Example: To match the string “2*2=4”, escape the asterisk: “2*2=4”.
Character Classes and Character Sets
By the end of this module, you will have a deeper understanding of character classes and sets and how they can be utilized in various programming languages and regular expressions.
Predefined Character Classes
This section will delve into predefined character classes, which are pre-built sets of characters that represent common patterns. These classes allow us to match specific types of characters concisely and efficiently. Let’s explore some of the unique word usages associated with predefined character classes:
#1 Digits and Numerics
The ‘\d’ shorthand represents the predefined character class for digits, which matches any numeric digit from 0 to 9.
Conversely, the ‘\D’ shorthand negates the predefined character class and matches any character that is not a digit.
#2 Word Boundaries
The ‘\b’ metacharacter represents a predefined character class that matches word boundaries, indicating the start or end of a word.
Conversely, the ‘\B’ metacharacter negates the predefined character class and matches any position that is not a word boundary.
Custom Character Sets
Let’s discover some unique word usages related to custom character sets:
#1 Ranges
By specifying a range within square brackets, such as ‘[a-z]’, we can create a custom character set that matches any lowercase letter from ‘a’ to ‘z’.
Negation can also be applied to custom character sets. For instance, ‘[^a-z]’ matches any character without a lowercase letter.
#2 Character Escapes
We can use backslashes to escape special characters within custom character sets. For example, ‘[]’ matches a left or right square bracket.
Negation can be combined with character escapes. ‘[^]’ matches any character, not a square bracket.
Negation
Negation is a powerful tool that allows us to match characters without a specific pattern. Let’s explore some unique word usages associated with negation:
#1 Negating Predefined Character Classes
We can negate a predefined character class by using a caret (^) as the first character inside square brackets. For instance, ‘[^0-9]’ matches any character without a digit.
#2 Negating Custom Character Sets
Similarly, negation can be applied to custom character sets. ‘[^aeiou]’ matches any character that is not a vowel.
The caret (^) is placed immediately after the opening square bracket to negate a custom character set with character escapes. For example, ‘^[^]’ matches any string that does not contain square brackets.
Quantifiers and Grouping in Python Regex
Quantifiers and grouping are essential concepts in regular expressions. They allow you to manipulate patterns and specify the number of occurrences or repetitions of certain elements. Understanding these concepts allows you to create more precise and flexible patterns for matching and capturing information.
#1 Greedy vs Non-Greedy Matching
Greedy matching is the default behavior of quantifiers in regular expressions. A quantifier will match as much as possible while allowing the overall pattern to match. On the other hand, non-greedy matching, also known as lazy or minimal matching, matches as little as possible. It ensures that the overall pattern still matches with the smallest possible substring.
For example, consider the pattern: /a.+b/ and the string: “aababcab”. In greedy matching, the pattern would match the entire string “aababcab” because the quantifier “+” matches as much as possible. However, in non-greedy matching, the pattern would match only “aab” because the quantifier “+” matches as little as possible while still allowing the overall pattern to match.
#2 Quantifiers: *, +, ?, {}, etc
Quantifiers are symbols in regular expressions that specify the number of occurrences or repetitions of the preceding element. Here are some commonly used quantifiers:
* (asterisk): Matches 0 or more occurrences of the preceding element; for example, /ab*c/ would match “ac”, “abc”, “abbc”, etc.
+(plus): Matches 1 or more occurrences of the preceding element. For example, /ab+c/ would match “abc”, “abbc”, “abbbc”, etc., but not “ac”.
? (question mark): Matches 0 or 1 occurrence of the preceding element. For example, /ab?c/ would match “ac” or “abc”, but not “abbc”.
{n} (curly braces): Matches exactly n occurrences of the preceding element. For example, /ab{3}c/ would match “abbbc”.
{n,m} (curly braces with two values): Matches between n and m occurrences of the preceding element. For example, /ab{2,4}c/ would match “abbc”, “abbbc”, or “abbbbc”, but not “ac” or “abc”.
#3 Grouping and Capturing
Grouping in regular expressions is denoted by parentheses (). It allows you to treat multiple elements as a single unit, enabling you to apply quantifiers or modifiers to the group as a whole. Additionally, grouping facilitates capturing specific parts of a match.
For example, consider the pattern: /(ab)+c/. The parentheses create a group, and the “+” quantifier applies to the group as a whole. This pattern would match “abc”, “ababc”, “abababc”, etc.
Grouping also enables capturing. Using parentheses, you can capture and refer to the matched substring later. For example, consider the pattern: /(ab)+c/. In this pattern, the group (ab) is captured. If the string “ababc” matches this pattern, you can access the captured group and retrieve “ab” from the match.
Capturing is useful when extracting specific information from a match, such as dates, phone numbers, or email addresses from a larger text.
Anchors and Word Boundaries
Start and End Anchors
Start anchors and end anchors are special characters or constructs that denote the beginning and end of a line or string of text. They are typically used in regular expressions or search patterns to match specific patterns at the start or end of a line.
Advantages
- Infallible: The start anchor ensures that the pattern matches only if it appears at the beginning of the line, making it an infallible tool for precise matching.
- Pioneering: The end anchor acts as a pioneering force, signaling the endpoint of a line and marking the boundary for further analysis or processing.
Word Boundaries
Word boundaries are markers that define the edges of words in a text. They identify the separation between words and non-word characters, such as spaces, punctuation marks, or line breaks.
Advantages
- Delimitation: Word boundaries serve as effective delimiters, allowing us to segment text into individual words for linguistic analysis or natural language processing tasks.
- Demarcate: By demarcating the boundaries between words, these markers enable accurate tokenization, enhancing the efficiency of language processing algorithms.
Lookahead and Lookbehind in Python Regex
These constructs allow you to check for patterns that occur ahead or behind a particular position in the text without including them in the match itself. Let’s dive deeper into lookahead and look behind, along with their positive and negative variations.
#1 Positive Lookahead
Positive lookahead is denoted by the syntax (?=…). It asserts that a given pattern must occur immediately ahead of the current position without consuming any characters in the match. Consider the example:
Regex: a(?=b)
Text: “abc”
The lookahead asserts that the letter ‘a’ must be followed by ‘b’. In this case, the regex matches the ‘a in “abc” because it’s followed by ‘b’.
#2 Negative Lookahead
Negative lookahead is denoted by the syntax (?!…). It asserts that a given pattern must not occur immediately ahead of the current position. Let’s understand this with an example:
Regex: a(?!b)
Text: “acd”
The negative lookahead asserts that the letter ‘a’ must not be followed by ‘b’. The regex matches the ‘a’ in “acd” because no ‘b’ follows it.
#3 Positive Lookbehind
Positive lookbehind is denoted by the syntax (?<=…). It asserts that a given pattern must occur immediately before the current position. Let’s see an example:
Regex: (?<=a)b
Text: “xab”
The positive lookbehind asserts that the letter ‘b’ must be preceded by ‘a’. In this case, the regex matches the ‘b’ in “xab” because it is preceded by ‘a’.
#4 Negative Lookbehind
Negative lookbehind is denoted by the syntax (?<!…). It asserts that a pattern must not occur immediately before the current position. Consider the example:
Regex: (?<!a)b
Text: “xcb”
The negative lookbehind asserts that the letter ‘b’ must not be preceded by ‘a’. In this case, the regex matches the ‘b’ in “xcb” because there is no ‘a’ preceding it.
Flags and Modifiers
Let’s explore various flags and modifiers available in the re-module of Python and understand their unique functionalities.
| FLAG/MODIFIER | USAGE |
| re.IGNORECASE | The re.IGNORECASE flag allows case-insensitive matching. The pattern will interchangeably match uppercase and lowercase letters when this flag is used. For example, when searching for the pattern “apple” with re.IGNORECASE, it will match “apple,” “Apple,” “APPLE,” and so on. |
| re.MULTILINE | The re.MULTILINE flag enables multiline matching. By default, regular expressions consider the input text as a single line. However, when using re.MULTILINE, the ^ and $ anchors will match the beginning and end of each line within the input text rather than the entire string. |
| re.DOTALL | The re.DOTALL flag allows the dot (.) character to match any character, including newline characters (\n). Generally, the dot matches every character except newline. With re.DOTALL, the dot will also match newline characters, providing a convenient way to match across multiple lines. |
| re.VERBOSE | The re.VERBOSE flag enhances the readability and maintainability of complex regular expressions. When using this flag, whitespace and comments can be added within the pattern string. This allows breaking down the pattern into multiple lines and adding explanatory comments, making it easier to understand and modify the expression. |
| re.ASCII | The re.ASCII flag restricts the interpretation of certain character classes to ASCII-only characters. It ensures that non-ASCII characters are not treated as special characters within character classes, such as \w, \W, \b, and \B. This flag can be useful when working with text that contains only ASCII characters. |
| re.DEBUG | The re.DEBUG flag enables debug output during the compilation and matching of regular expressions. It provides detailed information about how the regular expression engine interprets and executes the pattern. This flag is particularly helpful for troubleshooting complex regular expressions. |
| re.LOCALE | The re.LOCALE flag enables localized matching based on the current locale settings. It affects the behavior of character classes, such as \w and \b, to match locale-specific word characters and word boundaries. This flag ensures that the regular expression adapts to the language-specific rules defined by the locale. |
| re.NOFLAG | The re.NOFLAG signifies the absence of any flag. When no flag is specified, the regular expression pattern matches in the default mode, which is case-sensitive, single-line matching, and without any special interpretation for character classes. |
Examples and Use Cases
In this learning content, we will explore several practical examples and use cases where Python regex expressions can be applied effectively.
Example 1: Validating Email Addresses
Code:
import re
def validate_email(email):
pattern = r'^[\w\.-]+@[\w\.-]+\.\w+$'
if re.match(pattern, email):
return True
else:
return False
email1 = 'example@example.com'
email2 = 'invalid.email'
email3 = 'another_example@gmail.com'
print(validate_email(email1))
print(validate_email(email2))
print(validate_email(email3))Output:
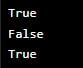
Explanation:
In this example, we define a function validate_email that takes an email address as input and uses a regex pattern to determine if the email is valid or not. The pattern r’^[\w\.-]+@[\w\.-]+\.\w+$’ matches email addresses that consist of one or more word characters (\w), dots (.), or hyphens (-), followed by the at symbol @, and then one or more word characters, dots, or hyphens again. Finally, it requires a dot (.) followed by one or more word characters at the end. If the email matches the pattern, the function returns True; otherwise, it returns False.
Example 2: Extracting URLs from Text
Code:
import re
def extract_urls(text):
pattern = r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'
return re.findall(pattern, text)
text = 'Visit my website at https://www.example.com and check out our online store at http://store.example.com'
urls = extract_urls(text)
print(urls)Output:
![]()
Explanation:
In this example, we define a function extract_urls that takes a block of text as input and uses a regex pattern to extract URLs from the text. The pattern r’http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+’ matches URLs starting with either http:// or https://. It allows for a wide range of characters and symbols that are commonly found in URLs. The re.findall function is used to find all occurrences of the pattern in the text and returns a list of URLs.
Example 3: Parsing Log Files
Code:
import re
def parse_log_file(log_file):
pattern = r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) \[(\w+)\] (.+)'
with open(log_file, 'r') as file:
for line in file:
match = re.search(pattern, line)
if match:
timestamp = match.group(1)
log_level = match.group(2)
message = match.group(3)
print(f'Timestamp: {timestamp}, Level: {log_level}, Message: {message}')
log_file = 'app.log'
parse_log_file(log_file)Output:
![]()
Explanation:
In this example, we demonstrate how to use Python regex expressions to parse log files. The function parse_log_file takes the path to a log file as input. It reads the file line by line and uses the regex pattern r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) \[(\w+)\] (.+)’ to extract the timestamp, log level, and log message from each line. The re.search function finds the first occurrence of the pattern in the line. If the function finds a match, it extracts the relevant groups using match.group() and prints the parsed information.
Example 4: Data Extraction and Cleaning
Code:
import re
def clean_data(data):
pattern = r'[\W_]+'
return re.sub(pattern, ' ', data)
text = 'This is some text! It contains punctuation, numbers (123), and _underscores_.'
cleaned_text = clean_data(text)
print(cleaned_text)Output:
![]()
Explanation:
In this example, we define a function clean_data that takes a string of data as input and removes any non-alphanumeric characters using a regex pattern. The pattern r'[\W_]+’ matches one or more non-alphanumeric characters or underscores. The re.sub function substitutes matches of the pattern with a space character, effectively removing them from the string.
These examples demonstrate just a few of the many practical use cases for Python regex expressions. You can apply regex to various scenarios, allowing you to search, validate, extract, and manipulate text data with precision and efficiency.
Recommended Articles
We hope that this EDUCBA information on “Python Regex” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
