Updated March 16, 2023
Introduction to Scikit Learn XGBoost
Scikit learn xgboost is an ensemble machine learning model performing better than the single model. It will combine multiple xgboost models into single models. Boosting is an alternative to bagging; instead of prediction aggregations, the booster will learn from strong learners by focusing on a single model. The xgboost single models are trained using residuals containing the difference between the result and prediction.

Key Takeaways
- Scikit learn implements the gradient-boosted decision trees designed for the performance and speed used for machine learning.
- To use the xgboost in scikit learn python, first, we need to install the xgboost module in our system using the pip command.
What is Scikit Learn XGBoost?
It is a short form of extreme gradient boosting. The extreme refers to parallel computing and enhancements and the awareness of cache, which made the xgboost ten times faster than others. As per additional things, xgboost includes an algorithm of unique split findings for optimizing the trees with the built-in regularizations, reducing the overfitting. Generally, xgboost is more accurate and faster in gradient boosting.
As we know that boosting performs better than others, gradient boosting is very important in the ensemble. The scikit learn xgboost advanced boosting version will contain results in an unparalleled manner. Scikit learn is an open-source library of python that provides the boosting framework. It will help us to create an efficient, portable, and flexible model. When working with predictions, it performs well compared to the other algorithms. Using the accuracy and performance will combine the multiple models into one model to correct the errors made by existing models.
How to Use Scikit Learn XGBoost?
It is built onto the top of the gradient framework. Xgboost is creating strong learners based on the weak learners; it will add models sequentially; therefore, we can correct the weak model error in the next model.
Below steps shows how we can use the xgboost in scikit learn as follows:
1. To use xgboost, first, we need to install the same in our system. We can install the module of xgboost by using the pip command as follows.
Code:
pip install xgboostOutput:
2. After installing the software of xgboost, in this step, we are importing the required modules as follows.
Code:
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreOutput:
3. After importing the modules in this step, we load the dataset. We are loading the text file.
Code:
boost = loadtxt('plot.csv', delimiter=",")Output:

4. After loading the dataset in this step, we split the data into the x and y axes.
Code:
X = boost[:,0:8]
Y = boost[:,8]Output:
5. After splitting the data into the x and y axis, we are now breaking the data into train and test.
Code:
sci = 7
kit = 0.33
X_train, X_test, y_train, y_test = ()Output:

6. After splitting the data into test and train, we print the scikit learn xgboost model.
Code:
learn = XGBClassifier()
learn.fit(X_train, y_train)
print (learn)Output:
7. After creating the model in this step, we are making the predictions of the test data as follows.
Code:
pred = learn.predict(X_test)
sci_pred = [round(value) for value in pred]Output:

8. After making the test data predictions, now, in this step, we are evaluating the predictions as follows.
Code:
acc = accuracy_score (y_test, sci_pred)
print("Acc: %.2f%%" % (acc * 100.0))Output:
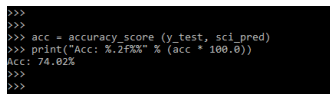
Scikit Learn XGBoost Model
The scikit learn xgboost module tends to fill the missing values. To use this model, we need to import the same by using the import keyword. The below code shows the xgboost model as follows.
Code:
import xgboost as xgb
boost = xgb.XGBClassifier (random_state = 2, learning_rate = 0.02)
boost.fit (X_train, y_train)
boost.score (X_test, y_test)Output:
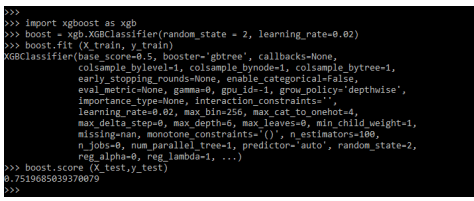
It is an advanced version of boosting; the xgboost contains the below parameters as follows:
- eta
- Thread
- Max_depth
- Min_child_weight
- Max_depth
- gamma
- max_leaf_nodes
- subsample
- colsample_bytree
It falls under the community of distributed machine learning. XGBoost is an advanced version of boosting. The main motive of this algorithm is to increase speed. The scikit learn library provides the alternate implementation of the gradient boosting algorithm, referred to as histogram-based. This is the alternate approach to implement the gradient tree boosting, which the library of light GBM inspired. The histogram-based boosting is to implement the classifier and train the data.
Below example shows the scikit learn model as follows:
In the below example, we are importing the multiple modules as follows:
Code:
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from matplotlib import pyplot
X, y = make_classification ()
scikit = GradientBoostingClassifier()
learn = RepeatedStratifiedKFold ()
boost = cross_val_score()
print ('Accuracy: %.3f )
scikit = GradientBoostingClassifier()
scikit.fit (X, y)
sci = [ ]
kit = scikit.predict (sci)
print('Prediction: %d' % kit[0])Output:
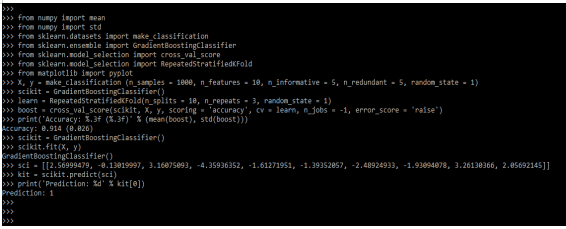
Examples
Different examples are mentioned below:
Example #1
In the below example, we are loading the xgboost dataset as follows.
Code:
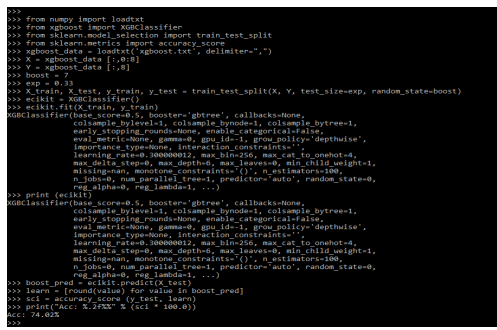
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
xgboost_data = loadtxt ('xgboost.txt', delimiter = ",")
X = xgboost_data [:,0:8]
Y = xgboost_data [:,8]
boost = 7
exp = 0.33
X_train, X_test, y_train, y_test = train_test_split ()
ecikit = XGBClassifier()
ecikit.fit (X_train, y_train)
print (ecikit)
boost_pred = ecikit.predict (X_test)
learn = [round(value) for value in boost_pred]
sci = accuracy_score (y_test, learn)
print ("Acc: %.2f%%" % (sci * 100.0))Output:
Example #2
In the below example, we are loading the xgboost dataset as follows.
Code:
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from matplotlib import pyplot
X, y = make_classification ()
scikit = HistGradientBoostingClassifier()
learn = RepeatedStratifiedKFold()
ns = cross_val_score()
print ('Acc: %.3f)
boost = HistGradientBoostingClassifier()
boost.fit(X, y)
row = []
sci = boost.predict (row)
print ('Prediction: %d' % sci[0])Output:
FAQ
Other FAQs are mentioned below:
Q1. Why are we using scikit learn xgboost in python?
Answer: It is used to speed up the performance of models. We can reduce the error by using scikit learn xgboost in python.
Q2. How to train the xgboost model in scikit learn?
Answer: The model provides the wrapper class, which was treated like a regressor or classifier, into the framework of scikit learn.
Q3. How are we making predictions by using the scikit learn xgboost model?
Answer: We are predicting xgboost by default because it contains the binary classification problems for each prediction.
Conclusion
Boosting is an alternative to bagging; instead of prediction aggregations, boosters will learn from strong learners by focusing on a single model. The extreme refers to parallel computing and enhancements and the awareness of cache, which made the xgboost ten times faster than others.
Recommended Articles
This is a guide to Scikit Learn XGBoost. Here we discuss the introduction, model, and how to use it with examples and FAQ. You may also have a look at the following articles to learn more –
