Updated April 4, 2023

Introduction to Scrapy Cloud
Scrapy cloud eliminates the need for servers to be set up and monitored and instead provides a user-friendly interface for managing spiders and reviewing scraped items, logs, and statistics. During the early stages of development, running the spider of scrapy on our local system is very easy. However, we would have to deploy and run our spiders on the cloud on a regular basis at some point.
What is Scrapy Cloud?
- Scrapy Cloud is hosted on zyte, it is providing cloud-based services, it is also known as the creators of Scrapy.
- The stub command-line utility is used to deploy Zyte Scrapy Cloud. Scrapyd and Zyte Scrapy Cloud are compatible, and we can switch between them as needed. It will reading the configuration from scrapy.cfg file, just like with scrapyd-deploy.
- Web Scraper Cloud and the extension Web Scraper can be our ideal data extraction tool.
- Scraper collects webpage data in minutes using a simple point-and-click interface. With Web Scraper Cloud’s scheduler and other features, we can entirely automate scraping jobs.
- We can select scrapy cloud pages and whether or not to schedule the scrape task when saving the recipe. For scrapy cloud pages, simply click ‘run recipe’ after saving the recipe. After a few moments, the results will show.
- With the adoption of new technologies, the number of internet users and data is rapidly increasing.
- We examined the scraping process when exposed to a large amount of data extraction because scraping is one of the most common methods for extracting data from Internet.
- While scraping a huge amount of data, we encountered various problems, including capcha, storage issues for a big number of data, the necessity for heavy compute capacity, and data extraction dependability.
- We can use Amazon Web Services to examine architecture that can handle storage and computational resources with elasticity on demand.
- When the scraped website’s design changes, the scraping code must be updated. Honeypots are web crawler traps that cause them to loop indefinitely.
- If crawling place and the source are attempted many times, IP Blockers disable it. Crawlers are detected and blocked by CAPTCHA blockers if they do not behave like human traffic.
How scrapy cloud work?
- Web scraping is a term that is often used to describe cloud scraping. It’s partly true because we can scrape the web for free using free or open-source tools like browser extensions.
- These resources will scrape the web page we are on and save the scraped data to our local computer, which will almost always require some cleaning before being processed for our purposes. There are also a slew of web resources that can let someone with no coding experience retrieve thousands of Reddit searches or the top 10 URLs for any Google search phrase.
- Our solution strives to solve both scraping and feasibility for large data applications. We mention selenium as one of our online scraping tools because it enables web drivers that simulate a genuine user using a browser.
- We also check the suggested cloud-based scrapper’s scalability and performance, as well as the advantages it has over other cloud-based scrappers.
- If we only need web scraping once and on a small scale. On the other hand, if our firm relies heavily on web scraping, it may be worthwhile to invest in the necessary technical infrastructure to conduct it in-house.
- It may be worthwhile to invest in technical advancement. If we are a marketing agency that uses web scraping as a supplement to our analysis rather than as the main service, investing in technological resources might not be worth it in the long term.
Below steps show pre-requisite while working with scrapy cloud are as follows.
1) In the first step we are creating a directory and running venv is as follows. In the below step, we are creating the secret_cl directory.
mkdir secret_cl
cd secret_cl
python -m venv .venv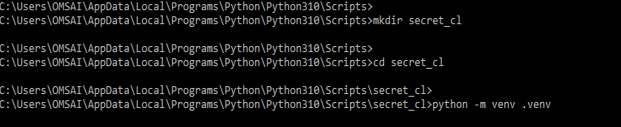
2) In the below example we are installing scrapy, scrapy-frontera, and hcf-backend modules by using the pip command.
pip install scrapy scrapy-frontera hcf-backend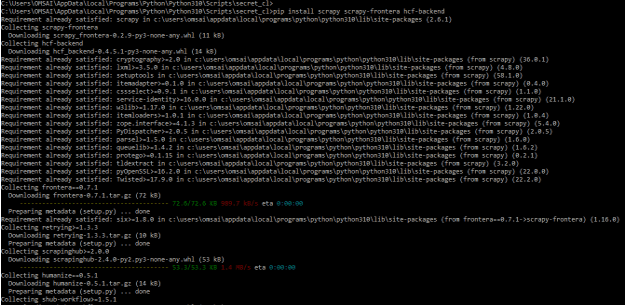
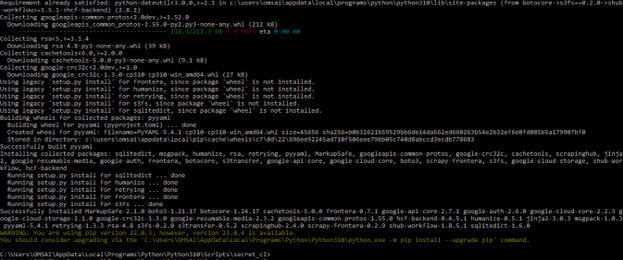
3) After installing the required module in this step we are creating the scrapy project are as follows.
scrapy startproject cloud_scarpy .
cd.
scrapy genspider scarpy.cloud.com scarpy.cloud.com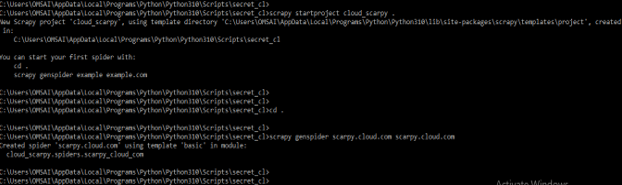
Scrapy Cloud Secrets
- Using agile methodology, in-house web scraping will allow us the flexibility to change the data we collect. It can take a long time to communicate requests within an external source, and if there is a misunderstanding, the process must be repeated.
- Data collection is done on the cloud through cloud web scraping. It is more scalable and powerful. For example, if our online scraping needs grow from a few hundred to tens of thousands of pages, cloud web scraping will handle them more efficiently than in-house scraping and save our time. Instead of saving data locally, it saves it to the cloud.
- Below example shows create the scrapy cloud secrets are as follows.
Code:
import scrapy
class BooksToscrapeComSpider (scrapy.Spider):
py_name = 'books.toscrape.com'
py_domain = ['scarpy.cloud.com']
py_url = ['http://scarpy.cloud.com']
def parse(self, response):
for href in response.css('href').getall():
yield response.follow (href, self.parse_book)
py_href = response.css('.pager .next a::attr(href)').get()
if py_href:
yield response.follow(py_href, self.parse)
def parse_book(self, response):
return {
'name': response.css('.name h1::text').get().strip(),
'pr': response.css('.pr_main .pr::text').get().strip()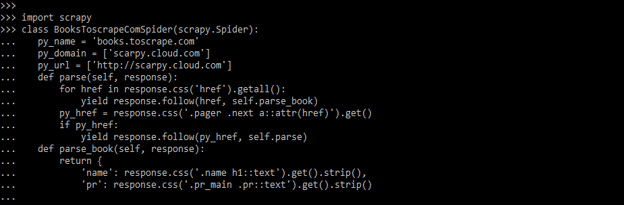
- In the below example we are creating the scrapy cloud secret are as follows.
Code:
py_middle = {
'scrapy_frontera.middlewares.SchedulerDownloaderMiddleware': 0,
}
sp_middle = {
'scrapy_frontera.middlewares.SchedulerSpiderMiddleware': 0,
}
Scrapy cloud API
- The below step shows how to interact with scrapy cloud API are as follows.
1) In this step we are checking the API key of the website and we authenticate the website by using an API key.
$ curl -u APIKEY: https://www.google.com/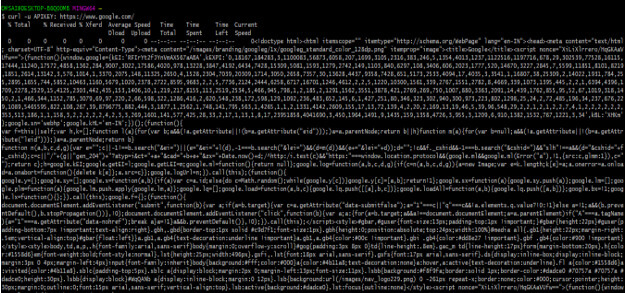
2) In the below step we are authenticating the website by using the URL parameter.
curl https://www.google.com?apikey=APIKEY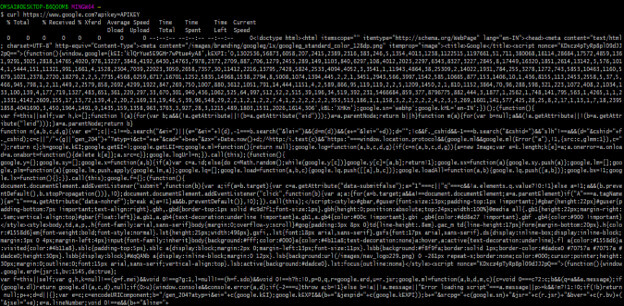
3) Below example shows running simple spider are as follows.
curl -u APIKEY: https://www.google.com/api/run.json -d project = PROJECT -d spider = SPIDER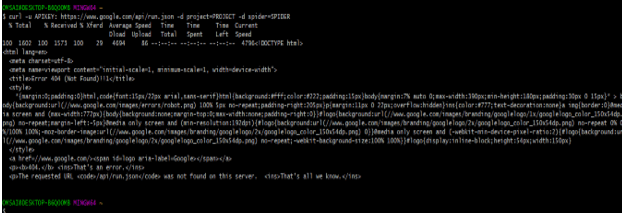
Conclusion
Scrapy Cloud is hosted on zyte, it is providing cloud-based services. Scrapy cloud eliminates the need for servers to be set up and monitored, and instead provides a user-friendly interface for managing spiders and reviewing scraped items, logs, and statistics.
Recommended Articles
We hope that this EDUCBA information on “Scrapy cloud” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
