Updated June 9, 2023

Definition of Scrapy CSS selector
It is a style-application language which was used to develop web pages. In Scrapy, “selectors” are used to link specific styles to specific HTML elements. The other method for scanning HTML text in web pages is XPath. XPath has more capabilities in Scrapy than a simple CSS selector. The LXML package, which interprets XML and HTML in Python, provides the foundation for selectors.
What is Scrapy CSS Selector?
- When scraping web pages, we must use selectors to extract a specific section of the HTML code, which we may do with XPath or CSS expressions.
- Extracting the data is the most common activity when scraping web pages. To do so, we can use one of several libraries.
- Lxml is a Pythonic XML parsing package based on ElementTree that also parses HTML.
- Scrapy has a built-in data extraction mechanism. Selectors derive their names from their ability to “select” specific elements of the HTML document using XPath or CSS expressions.
How to Use Scrapy CSS Selector?
- XPath is an XML-based language that can also be used with HTML to select nodes in XML documents. CSS is a style-application language for HTML texts. It establishes selections that link the styles to specific HTML components.
- Scrapy Selectors is a lightweight wrapper for the parsel library, designed to make it easier to work with Scrapy.
- Parsel will implement the easy API and use the lxml library beneath the hood. Scrapy selectors are similar to lxml selectors in speed and processing accuracy.
- The below step shows how to construct the scrapy selectors as follows.
1) In this step, we install the scrapy using the pip command. In the following example, since we have already installed the Scrapy package in our system, it will indicate that the requirement is already satisfied, and no further action is needed.
pip install scrapy
2) In this step, we create the HTML page. We have created the below webpage to use a scrapy css selector.
Code:
<html>
<head>
<base href = 'http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id = 'images'>
<a href = 'image1.html'>Image 1 <br /><img src = 'image1_thumb.jpg' /></a>
<a href = 'image2.html'>Image 2 <br /><img src = 'image2_thumb.jpg' /></a>
<a href = 'image3.html'>Image 3 <br /><img src = 'image3_thumb.jpg' /></a>
<a href = 'image4.html'>Image 4 <br /><img src = 'image4_thumb.jpg' /></a>
<a href = 'image5.html'>Image 5 <br /><img src = 'image5_thumb.jpg' /></a>
</div>
</body>
</html>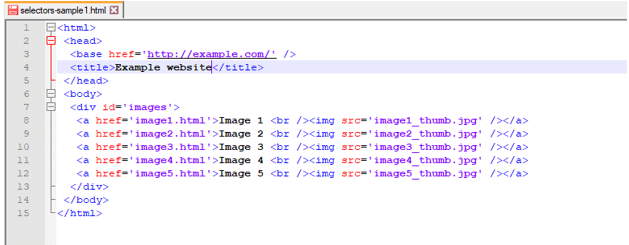
3) After creating the HTML code in this step, we open the scrapy shell using html code as follows. The below example shows open the scrapy shell by using html code.
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
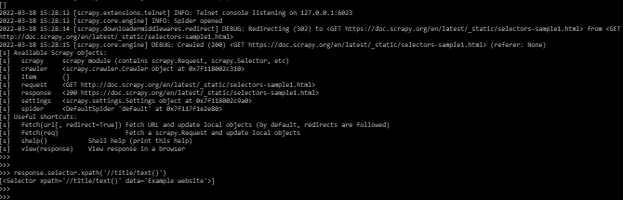
- In the above example, we have used the “selectors-sample1.html” file to open the scrapy shell. We can use CSS selectors in Scrapy to extract specific parts of an HTML file because CSS languages are declared in any HTML file.
- Scrapy is a powerful and scalable web scraping framework. It has a large user base, and each update brings new features.
4) Below example shows how to use a scrapy CSS selector. In the example below, we used the response method using a CSS selector.
response.css ('img').xpath ('@src').extract()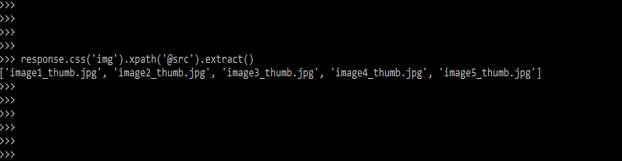
Scrapy CSS Selector URLs
- You can utilize CSS selectors in various ways depending on the situation. The very Basic start begins with the basic tags in an HTML file, such as the HTML> tag, the HEAD> tag, the BODY> tag, etc.
- So, using Scrapy, the basic format for selecting any tag in an HTML file is as follows. So, if we want to select the inside text of the Tags or just the attribute of any particular tag, we’ll need to change our selection method.
- The URL is the exact URL that we used when logging into the Scrapy shell. The below example shows an example of scrapy css selector url.
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html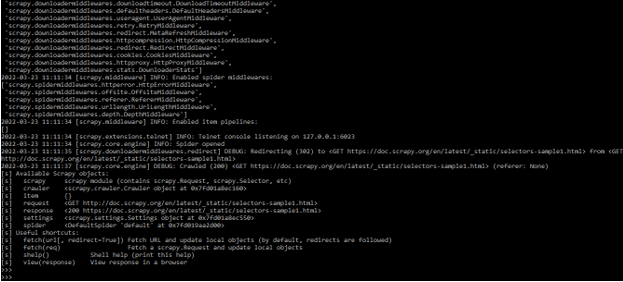
- If the HTML file has several tags of the same type, we can use the getall function to select all of them instead of the get method. It gives us a list of the tags we have chosen and their data.
- If we do not reference the tag we are looking for in the file, CSS selectors do not return anything. In such cases, we can also provide default data.
- When we scrape a URL with Scrapy, we refer to the link text and the portion of the URL as href. Below example will return the text of all the URLs from the HTML document.
Code:
def parse(self, response):
for quote in response.css('a::text'):
yield {
"py_test" : quote.get()
}
- The below code retrieves urls from the document’s a> HTML elements’ href properties. You can return the style values in the same way.
Code:
def parse(self, response):
for quote in response.css('a::attr(href)'):
yield {
"py_test" : quote.get()
}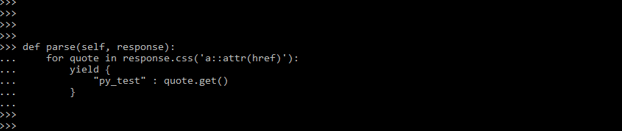
Scrapy CSS Selector Examples
- In the below example, we are using the response method.
response.css('title::text')
- In the example below, we are returning the selector list using a scrapy CSS selector as follows.
response.css ('img').xpath ('@src').extract()
- The below example shows a select text attribute.
response.css ('title::text').extract()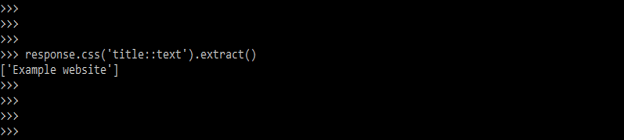
- The below example shows to get the url and images.
response.css('a[href*=image]::attr(href)').extract()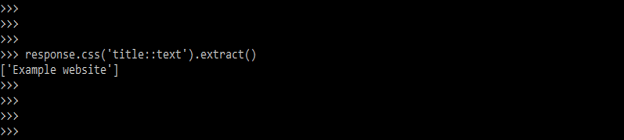
- The below example shows the use getall method.
response.css('a[href*=image]::attr(href)').getall()
Conclusion
The lxml package, which interprets XML and HTML in Python, provides the foundation for selectors. Developers utilize the Scrapy CSS selector as a style-application language for web page development. In Scrapy, “selectors” link specific styles to particular HTML elements.
Recommended Articles
We hope that this EDUCBA information on the “Scrapy CSS selector” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
