
Definition of Scrapy proxy pool
A scrapy proxy pool periodically keeps track of functional and non-working proxies. When rotating proxy middleware is enabled, the default Scrapy concurrency parameters for proxied requests become per-proxy. For example, if we set concurrent requests per domain as 2, the spider will connect to each proxy twice, independent of the request url domain. A non-working proxy can only be detected on a site-by-site basis. Scrapy-proxy-pool defaults to a basic heuristic.
Overviews scrapy proxy pool.
- If the response status code in the response body is empty or an exception occurs, the proxy is considered dead.
- We can override the ban detection mechanism by specifying the PROXY POOL BAN POLICY.
- The policy contains a class that has methods like response is ban and exception is ban. The ban method returns an actual value if a ban has been discovered, False if no prohibition has been found, or None if no ban has been identified.
- Subclassing and modifying the default BanDetectionPolicy can be helpful. For example, the spider will demand a refresh if there are no active proxies.
How to set up a scrapy proxy pool?
- Proxies will make requests with the host IP. After this number of retries, the failure is classified as a page failure rather than a proxy failure.
- While Scrapy makes creating scalable online scrapers and crawlers simple, they are ineffective in many cases without using proxies.
- Scrapy is a widely used online scraping framework for building crawlers and scrapers. In addition, Scrapy supports proxies as a web scraping tool, and proxies will almost certainly be used in our project.
- Scrapy, unlike Requests and BeautifulSoup, is a complete web scraping framework; we can use it to parse HTML documents and perform other activities.
- Scrapy works similarly in scraping libraries when used alone. This tool has a lot of features, and we may customize it.
- Scrapy allows us to create a crawler or scraper and quickly deploy it to the cloud.
- Scraping hub, a well-known provider interested in data extraction technologies, created this scraping framework.
- Python spider development was used in the creation of this product. It’s the quickest Python framework.
- Scrapy’s main flaw is its steep learning curve and being confronted with a website that uses JavaScript.
- Scrapy contains a combination of Requests and BeautifulSoup. It is, nevertheless, unquestionably more scalable and well-suited to sophisticated projects. Furthermore, setting up proxies is relatively simple.
- We may set up scrapy using one of two approaches. The below method shows how to set up a scrapy proxy pool.
1) Setup scrapy proxy pool by passing the request parameter
- The simplest way to configure proxies in scrapy is to give the proxy as a parameter. If we need to employ a proxy cheap service, this solution is ideal.
- HttpProxyMiddleware is a middleware in Scrapy that accepts the proxy value from the request and sets it up correctly.
- The following is an example of how to use the Requests parameter in Scrapy to set up proxies.
Code:
def start_requests (py_self):
for py_url in py_self.start_urls:
return Request(py_url = py_url, callback = py_self.parse,
headers={"User-Agent": "User agent"},
meta={"proxy": "http://127.0.0.1:8050"})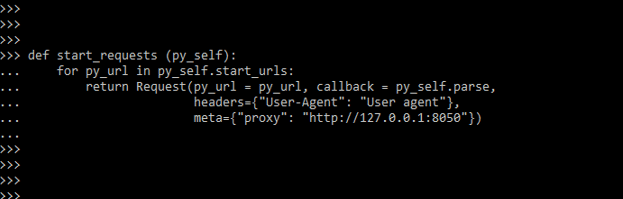
- In Scrapy, we supply the URL after and possibly a callback function when sending a request. Then, we can send it as a meta-argument if we wish to utilize a proxy for that URL. There’s no need to set up the middleware because it’s already activated.
- It works because Scrapy has a middleware called HttpProxyMiddleware that correctly uses it as the utilized proxy.
2) Create custom proxy middleware
- We recommend building bespoke middleware for a more modular approach. A middleware is a piece of code that Scrapy uses to process requests. For example, we can use the custom middleware template below.
- The solution will be more modular and separated in this manner. First, however, we need to do the same thing we did when sending the proxy as a meta-argument.
- The below example shows create custom proxy middleware as follows.
Code:
from w3lib.http import basic_auth_header
class CustomProxyMiddleware (object):
def process_request (self, request, spider):
request.meta ["proxy"] = "http://127.0.0.1:8050"
request.headers ["Proxy-Authorization"] =
basic_auth_header ("py_user", "pass123")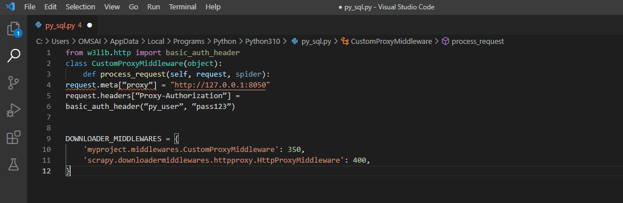
- We can utilize Scrapy using Scrapinghub’s proxy service. The cost of a crawler is determined by the number of requests it receives. Therefore, we can select one of the proxy providers if we want to use a scrapy proxy pool.
Rotate scrapy proxy pool
- When we cycle IP addresses, we randomly pick one to send our scraper’s request.
- We can extract data and be delighted if it succeeds, i.e., it delivers the correct HTML page. Unfortunately, we won’t be able to retrieve the data if it fails. We advocate adopting an automated solution because manually managing this can be painful.
- If we wish to add IP rotation in our Scrapy spider, we can use the scrapy-rotating-proxies middleware, which was built specifically for this purpose.
- We are modifying the crawling pace and ensuring that we are using live proxies. After installing and configuring the middleware, we have to add our proxies to a list in the settings.
- Zyte Proxy Manager was explicitly built for this purpose. In addition, we don’t have to manage hundreds of proxies since Zyte Proxy Manager allows us to crawl at scale confidently.
- We won’t have to rotate or replace proxies ever again. Zyte Proxy Manager can be used with Scrapy in the following way.
- The below example shows rotating the scrapy proxy pool as follows.
Code:
PY_ROTATE_PROXY = [
'ex1.com:8000',
'ex2.com:8031'
]
Scrapy proxy pool Examples
- To use the proxy pool in the scrapy example, first, we need to install the scrapy-proxy-pool modules in our system.
- The example below shows that installing the scrapy proxy pool in our system is as follows.
pip install scrapy-proxy-pool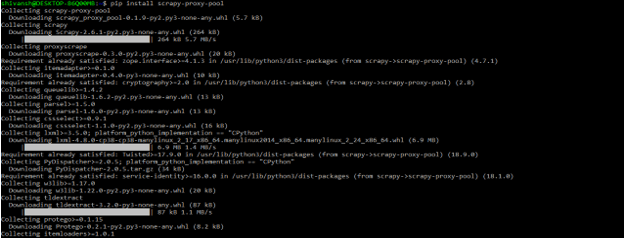
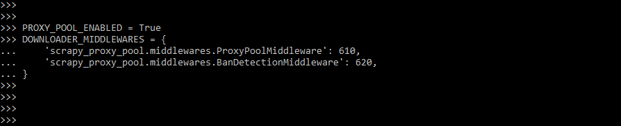
- The below example shows the scrapy proxy pool as follows. To use the scrapy proxy pool, first, we must enable it in our program.
Code:
PROXY_POOL_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapy_proxy_pool.middlewares.ProxyPoolMiddleware': 610,
'scrapy_proxy_pool.middlewares.BanDetectionMiddleware': 620,
}
Conclusion
It periodically keeps track of functional and non-working proxies. When rotating proxy middleware is enabled, the default Scrapy concurrency parameters for proxied requests become per-proxy. The proxy is considered dead if the response status code isn’t in the response body, is empty, or an exception occurs.
Recommended Articles
We hope that this EDUCBA information on “Scrapy proxy pool” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
