
Introduction to Scrapy Web Scraping
Scrapy web scraping is a framework for crawling and extracting structured data from web pages. It can be used for various tasks, including data mining, monitoring, and automated testing. For data science enthusiasts, the internet’s growth has been a benefit. Nowadays, the diversity and volume of data available on the internet are like a treasure mine of secrets and riddles waiting to be solved.
What is Scrapy Web Scraping?
- In these circumstances, web scraping becomes vital in a data scientist’s toolset. Nowadays, data is everything, and one approach to collect data from websites is to use an API or employ Web Scraping techniques.
- We can leverage the Beautiful Soup module’s Multithreading and Multiprocessing feature and develop a spider to crawl across a webpage and gather data. Scrapy is a tool that can be used to save time.
- Scrapy introduces many new capabilities, including building a spider, running it, and then scraping data.
- Web scraping is a technique for extracting information from websites without requiring access to the database. We need access to the site’s data to scrape it.
- Data scraping increases the server load on the site we are scraping, resulting in increased costs for the firms that site users.
- The impact we have on the server is moderated by the quality of the server that hosts we are attempting to access and the rate at which we submit requests to the server. In light of this, we must follow a few guidelines.
- In the leading directory of most websites, there is also a file called robots.txt. This file specifies which directories are off-limits to scrapers. In addition, the data scraping policy of a website is usually stated on the page of Terms & Conditions from the website.
- To ensure that we receive lawful data, we should always verify the website’s terms and robots.txt file before attempting to obtain data from it. We must also provide an overload of a server with queries it cannot handle when developing our scrapers.
- Many websites, thankfully, recognize the necessity for users to acquire data and provide APIs.
- If these are accessible, using an API rather than scraping to get data is a far more pleasant process.
- Python is a simple, straightforward language with few non-alphabetic characters, unlike several other coding languages. Developers can learn and understand it more quickly than in other languages because of its simplicity.
- Python comes with a slew of libraries (NumPy, Matlpotlib, Pandas, and so on) that allow programmers to scrape and modify a wide range of data sets effortlessly.
How to Create Scrapy Web Scraping?
- Web scraping is a powerful tool in today’s data science toolkit. The enormous amount of organized and unstructured data freely available on the internet can be used in various decision-making processes.
- To create a web scraping project in scrapy, we are using anaconda and visual studio code to develop the web scraping project. Below steps that show creating a scrapy web scraping project are as follows.
- In the first step, we create the new project name as web_scrapy using anaconda.
scrapy startproject web_scrapy
- Under the web_scrapy directory, we have created a new project named web_scrapy. According to the instructions, by changing our directory to web_scrapy, we’ll be ready to start our first spider. All necessary files, including a subfolder named spiders, where all of our spiders will live, will be generated automatically in the folder.
- After creating the project in this step, we are creating spiders.
scrapy genspider py_spider https://www.example.com/
- We used the scrapy genspider command to construct the spider, followed by the spider name, which in this case was an example, and the website we wanted to scrape.
- After creating a spider in this step, we are opening the project in the visual studio; after opening the scheme, we can see that py_country files will have created with the below code are as follows.
Code:
import scrapy
class web_scrapy (scrapy.spider) :
name = 'example'
domains = ['https://www.example.com']
surl = ['https://www.example.com']
def parse(self, response) :
pass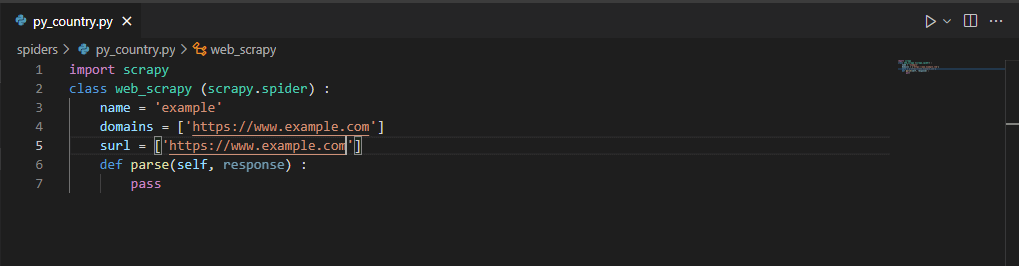
- After creating the file in this step, we open the URL and inspect the element.
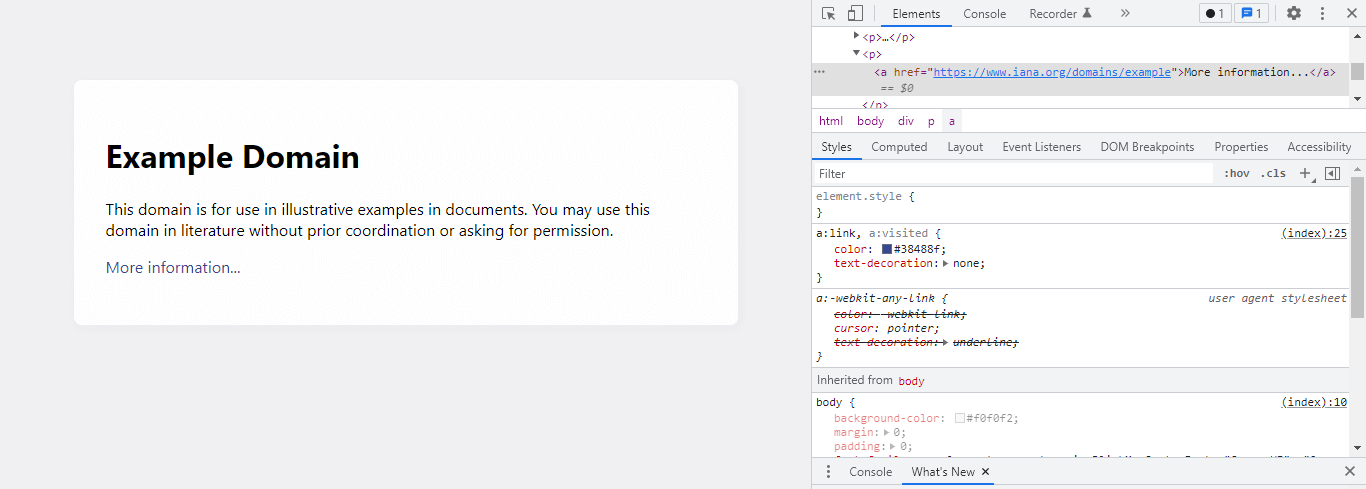
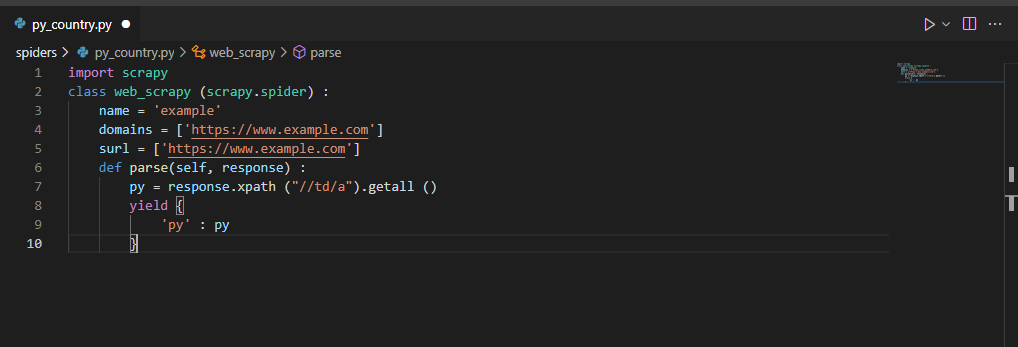
- After inspecting the element in this step, we use the XPath selector to define the values from the URL.
Code:
import scrapy
class web_scrapy (scrapy.spider) :
name = 'example'
domains = ['https://www.example.com']
surl = ['https://www.example.com']
def parse(self, response) :
py = response.xpath ("//td/a").getall ()
yield {
'py' : py
}
Scrapy Web Scraping Test
- Python can be used for many purposes, each corresponding to a specific Python library. For example, the pandas, selenium, and soup libraries will be used for web scraping purposes.
- To test the scrapy web scraping, first, we define the class of spider, then we need to specify the domain name which was spider is allowing to scrape it. The below example shows the creation of a spider class as follows.
Code:
class spider (scrapy.Spider):
name = "spider"
domain = ["example.com"]
surls = ["http://www.example.com"]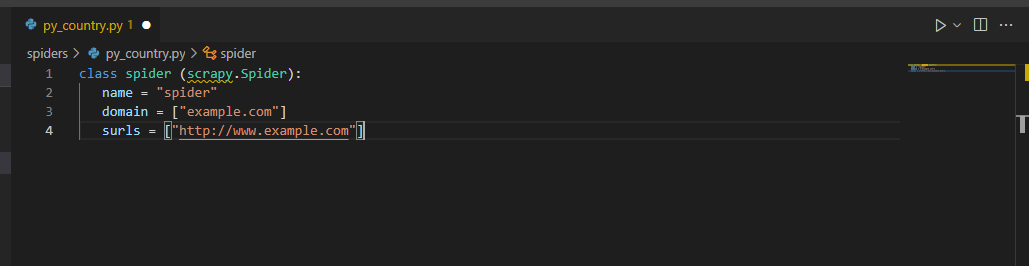
- The above example shows that we have used the spider name, domain, and start URL to create the spider class.
- Then we created the function which was used to capture the information which was we needed.
Code:
class spider (scrapy.Spider):
name = "spider"
domain = ["example.com"]
surls = ["http://www.example.com"]
def parse(self, response):
py = {}
py ['py_title'] = response.css('py_title::text').extract()
yield py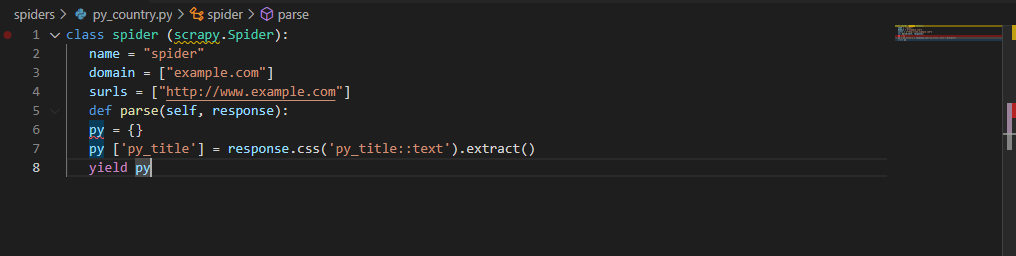
- We can print the URL response of URL by typing the below command as follows. We are using the response method to print the URL’s response.
print (response.text)
Conclusion
Scrapy introduces many new capabilities, including building a spider, running it, and then scraping data. Scrapy web scraping is a framework for crawling and extracting structured data from web pages. It can be used for various tasks, including data mining, monitoring, and automated testing.
Recommended Articles
We hope that this EDUCBA information on “Scrapy Web Scraping” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
