Updated February 18, 2023
Introduction to spaCy Dependency Parser
SpaCy dependency parser is the process of creating and describing the syntactic functions of distinct words in a phrase known as dependency parsing. For example, there are numerous dependencies between words in an English sentence. SpaCy contains a syntactic dependency parser that returns multiple dependencies and parses tags. SpaCy also features that allow us to visualize it using a dependency tree and several different ways to access it.
The dependency parse also helps iterate phrases by providing input to spaCys sentence boundary recognition. A dependency parser with a transitional approach. Because spaCy employs transition-based dependency parsing, which includes terms like a left arc and a proper arc, the edges between the head word and its dependent words are likewise considered arcs by software. The NLP pipeline in spaCy includes dependency parsing by default. SpaCy will finish parsing the dependencies when the doc object is generated after processing it. As a result, each token in our processed doc object contains all the dependency-related info.
Create a New spaCy Dependency Parser
An imitation learning target was used to train the parser. SpaCy dependency parser determines whether actions are compatible with the best parse that can be obtained from the current state at each stage. The weights are changed to enhance values awarded to other activities. It’s worth noting that multiple actions may be best for a particular state. The parameters Token.dep and Token.head is used to anticipate dependency. The parser determines sentence boundaries, which are recorded in Token.
Below is the attribute which was used in the spaCy dependency parser as follows:
- Token.dep: The type of token.dep attribute in dependency relation is int.
- Token.dep: The type of token.dep_ attribute in dependency relation is str.
- Token.head: The type of token.head attribute in dependency relation is token.
- Doc.sents: The Token.is sent start values determine the iterator over phrases in the Doc. The type of doc.sents attribute in dependency relation is an iterator.
The below example shows spaCy dependency parser is as follows.
We are importing the spaCy module to use the dependency parser in our program.
Code:
import spacy
py_text = "spacy dependency parser in python"
py_nlp = spacy.load ("en_core_web_sm")
py_doc = py_nlp (py_text)
for token in py_doc:
print (token.py_text, token.dep_,"token head is", token.head.py_text,
[child for child in token.children]Output:
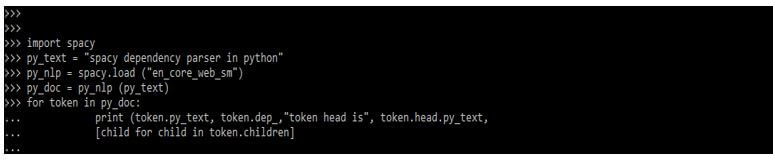
The token object has several attributes that aid in the best possible parsing of the dependency tree.
Below is the attribute of the spaCy dependency parser:
- token.left and token.right: These properties indicate which children of the token appear in the left and right sentences. The token.n lefts and token.n rights attributes can be used to obtain these integers directly.
- token.subtree: This returns the subtree that was generated by treating token.
- token.right_edge and token.left_edge: There are a few more qualities, such as token.ancestors, and token.right edge and token.left edge.
The below example shows visualize the dependency tree as follows.
In the below example, first, we are importing the spaCy modules. Then we provide a text message; after delivering a text message, we load the spaCy modules.
After loading the models, we import the display modules. Then we are calling the render method with display methods.
Code:
import spacy
py_text = "spacy dependency parser in python."
py_nlp = spacy.load("en_core_web_sm")
py_doc = py_nlp( py_text)
from spacy import displacy
displacy.render(py_doc, style='dep')Output:
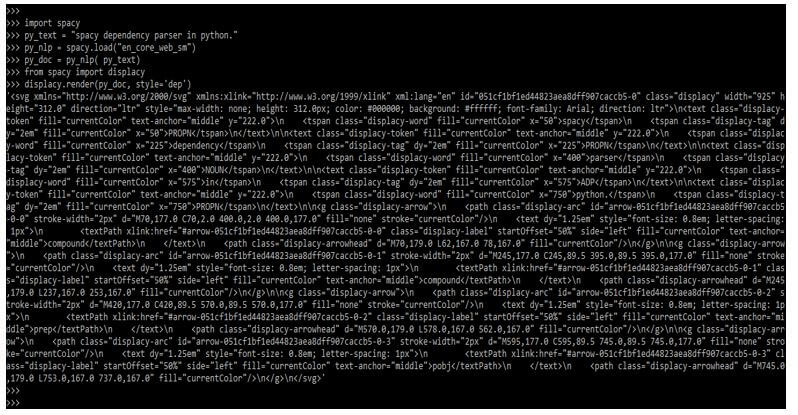
We are speeding up the creation and debugging of our code process. As a result, two of our most popular visualizers, display and display ENT, have been added to the core collection. If we have a Jupyter notebook open, displacy will detect it. Displacy.serve is the most efficient technique to visualize Doc. This will start a primary web server and allow us to examine the results in our browser. The arc shows words, with the child being the word at the arrowhead and the head being the word at the arrow’s end. The arc label indicates the kid to the head and is referred to as dep. The word ‘heading’ is the root word since it has many outgoing arrows but no incoming arrows.
SpaCy Dependency Parser Config
SpaCy dependency parser defines the default config, which specifies how the component should be set up. We can alter its parameters with the config option on NLP.add and config.cfg.
Below are the config parameters which was used in creating of spaCy dependency parser as follows:
1. Moves
The list of names for transitions. If data isn’t provided, it’ll be inferred from it. None is the default. The type of moves attribute in dependency relation is optional.
2. update_with_oracle_cut_size
To reduce large sequences into shorter parts. Because this parameter has a low impact on the model, we won’t have to adjust it very often. 100 is the default value. The type of update_with_oracle_cut_size attribute in dependency relation is int.
3. learn_tokens
Whether or not to learn how to combine subtokens divided about the gold standard Experimental. False is the default value. The type of learn_tokens attribute in dependency relation is bool.
4. min_action_freq
The minimum number of tagged actions that must be retained. The label for rarer labeled activities has been backed off to “dep.” While this mainly impacts label accuracy because labels are employed to express the pseudo-projectivity transformation, it can also affect attachment structure. The default value is 30. The type of min_action_freq attribute in dependency relation is int.
The below example shows spaCy dependency parser configs are as follows.
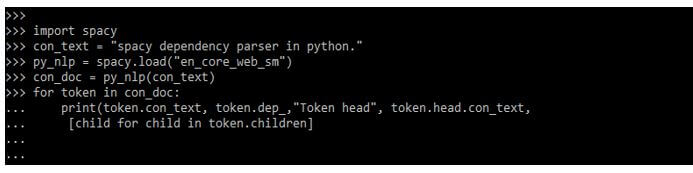
We have imported the spaCy module in the below example.
Code:
import spacy
con_text = "spacy dependency parser in python."
py_nlp = spacy.load ("en_core_web_sm")
con_doc = py_nlp (con_text)
for token in con_doc:
print(token.con_text, token.dep_,"Token head", token.head.con_text,
[child for child in token.children]Output:
Conclusion
The dependency parse also helps iterate phrases by providing input to spaCys sentence boundary recognition. SpaCy dependency parser is the process of creating and describing syntactic functions of distinct words in a term known as dependency parsing. SpaCy uses arc to analyze the dependency from head to the child.
Recommended Articles
This is a guide to spaCy Dependency Parser. Here we discuss the introduction, create a new spaCy dependency parser and parser config. You may also have a look at the following articles to learn more –

