Updated February 18, 2023

Introduction to the spaCy matcher
SpaCy matcher allows us to search for words and phrases based on token properties described by rules. Token annotations and lexical attributes such as a token.is_punct can be referenced by rules. When we apply the matcher on a Doc, we get access to the tokens that have been matched in context. This allows us to quickly access and examine the tokens around and add entries to named entities in doc.ents.
What is spaCy matcher?
The matcher is a rule-matching engine in spaCy that works with tokens in the same way as regular expressions. The rules can reference token annotations. We can also use a custom callback with the rule matcher to do actions on matches, such as merging entities and applying custom labels. We may also link patterns to entity IDs for essential entity linking and disambiguation. It helps match extensive terminology collections. Create token patterns and run them over our text to see how well spaCy’s rule-based matcher works. Each token can have numerous properties, such as the text value, part-of-speech tag, and Boolean flags.
It is a rule-based phrase matcher. If we modify the attr to match on, the token attributes match will change. If validate=True is set, when patterns are introduced, additional validation is done at the moment. It will look to see if the doc has any properties that aren’t required for the matches to be produced. The pattern can be added to the matcher. Each dictionary describes a single token as well as its characteristics. Token pattern keys are accessible for a variety of Token properties.
The following properties are supported for rule-based matching:
- ORTH: The type of ORTH attribute in spaCy matcher is str.
- TEXT: The type of TEXT attribute in spaCy matcher is str.
- NORM: The type of NORM attribute in spaCy matcher is str.
- LOWER: The type of LOWER attribute in spaCy matcher is str.
- LENGTH: The type of LENGTH attribute in spaCy matcher is int.
- IS_ALPHA, IS_DIGIT: The type of IS_ALPHA, IS_DIGIT attribute in spaCy matcher is bool.
- IS_LOWER, IS_UPPER: The type of IS_LOWER, IS_UPPER attribute in spaCy matcher is bool.
- IS_SENT_START: The type of IS_SENT_START attribute in spaCy matcher is bool.
- SPACY: The type of SPACY attribute in spaCy matcher is bool.
- OP: The type of OP attribute in spaCy matcher is str.
SpaCy Matcher Phrase Matcher
It works with tokens in the same way as regular expressions do. We can use the matcher to set rules to match, such as IS PUNCT, IS DIGIT, and so on. Compared to utilizing regular expressions on raw text, spaCy’s allow us to access the words and phrases we are looking for and the tokens inside the document and their relationships. We get a doc object when we pass sentence through an NLP pipeline in spaCy. The doc object treats every word and punctuation as a token. A token that matches the lowercase version of “April,” such as “april” or “April.” A token with the IS DIGIT flag set to true, which means it can be any number. Any punctuation token with the IS PUNCT flag set to true. The IS DIGIT flag is set to true on this token. A list of dictionaries should be made, each containing the match pattern for a single token. Below we have created the matcher.
Code:
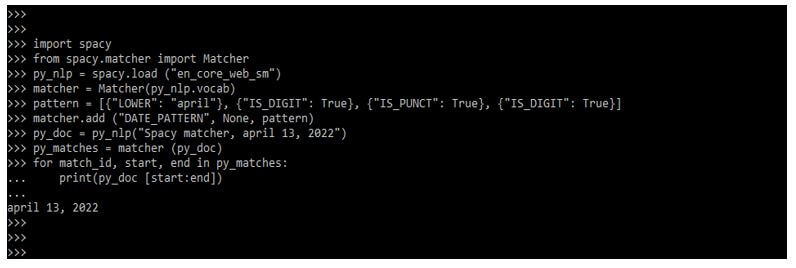
import spacy
from spacy.matcher import Matcher
py_nlp = spacy.load ("en_core_web_sm")
matcher = Matcher(py_nlp.vocab)
pattern = [{"LOWER": "april"}, {"IS_DIGIT": True}, {"IS_PUNCT": True}, {"IS_DIGIT": True}]
matcher.add ("DATE_PATTERN", None, pattern)
py_doc = py_nlp("Spacy matcher, april 13, 2022")
py_matches = matcher (py_doc)
for match_id, start, end in py_matches:
print(py_doc [start:end])Output:
When huge terminologies must be matched, the phrase matcher comes in handy. We can input strings to match instead of rules and patterns.
Below are the init method attributes in phrase matcher as follows:
- Vocab: The type of vocab attribute in phrase matcher is Vocab.
- Attr: The type of attr attribute in phrase matcher is Union [int, str].
- Validate: The validate attribute in phrase matcher is bool.
Below is the attribute of the phrase matcher call method. It will be used to find all the sequences of pattern span and doc.
- doclike: The type of doclike attribute in phrase matcher is Union [doc, span].
- as_spans: The type of as_spans attribute in phrase matcher is bool.
In phrase matcher, if a pattern for the provided ID already exists. Then, a callback for the on-match event will be overwritten. For example, below is the attribute of the phrase matcher adds method as follows.
- Key: The type of crucial attribute in phrase matcher is str.
- docs: The variety of docs attribute in phrase matcher is bool.
- on_match: The type of on_match attribute in phrase matcher is optional.
Below is the example of a phrase matcher as follows. In the below example, we have imported the spaCy modules; also, we are loading the models of spaCy.
Code:
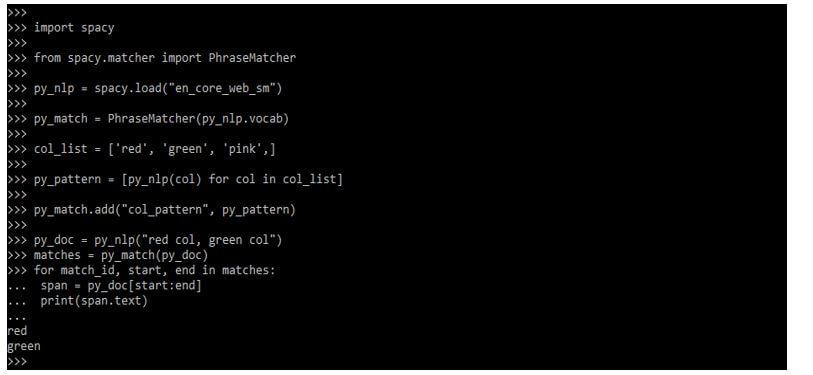
import spaCy
from spaCy.matcher import PhraseMatcher
py_nlp = spaCy.load("en_core_web_sm")
py_match = PhraseMatcher (py_nlp.vocab)
col_list = ['red', 'green', 'pink',]
py_pattern = [py_nlp(col) for col in col_list]
py_match.add ("col_pattern", py_pattern)
py_doc = py_nlp("red col, green col")
matches = py_match(py_doc)
for match_id, start, end in matches:
span = py_doc[start:end]
print(span.text)Output:
Examples of spaCy Matcher
Different examples are mentioned below:
Example #1
In the below example, we are using the matcher module.
Code:
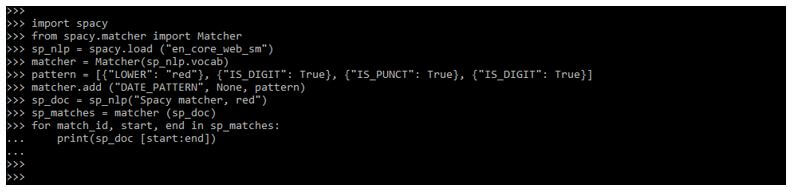
import spacy
from spacy.matcher import Matcher
sp_nlp = spacy.load ("en_core_web_sm")
matcher = Matcher(sp_nlp.vocab)
pattern = [{"LOWER": "red"}, {"IS_DIGIT": True}, {"IS_PUNCT": True}, {"IS_DIGIT": True}]
matcher.add ("DATE_PATTERN", None, pattern)
sp_doc = sp_nlp("Spacy matcher, red")
sp_matches = matcher (sp_doc)
for match_id, start, end in sp_matches:
print(sp_doc [start:end])Output:
Example#2
The below example shows the spacy matcher with the date as follows.
Code:
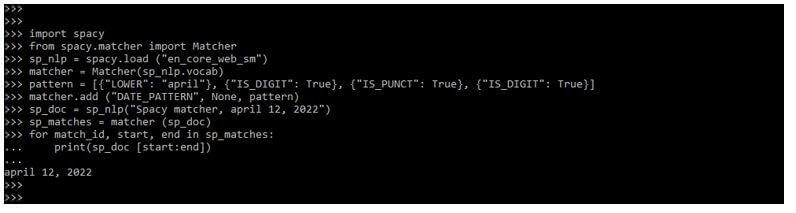
import spacy
from spacy.matcher import Matcher
sp_nlp = spacy.load ("en_core_web_sm")
matcher = Matcher(sp_nlp.vocab)
pattern = [{"LOWER": "april"}, {"IS_DIGIT": True}, {"IS_PUNCT": True}, {"IS_DIGIT": True}]
matcher.add ("DATE_PATTERN", None, pattern)
sp_doc = sp_nlp("Spacy matcher, april 12, 2022")
sp_matches = matcher (sp_doc)
for match_id, start, end in sp_matches:
print(sp_doc [start:end])Output:
Conclusion
Compared to utilizing regular expressions on raw text, spaCy’s allow us to access the words and phrases we are looking for and the tokens inside the document and their relationships. In addition, it will enable us to search for words and phrases based on token properties.
Recommended Articles
This is a guide to spaCy matcher. Here we discuss the introduction, SpaCy matcher phrase matcher, and examples, respectively. You may also have a look at the following articles to learn more –

