Updated April 10, 2023
Definition of spaCy text classification
SpaCy text classification is commonly utilized in the circumstances such as separating the text’s core theme and classifying customer service emails by complaint type. Also, training a custom text categorization has been proven in many real-world scenarios. SpaCy is a powerful library for conducting NLP tasks like categorization. One of the main reasons why spaCy is so popular is that it makes it simple to create and extend a text categorization model.

What is spaCy text classification?
- SpaCy is a Python-based package. It is intended for usage in production environments, and it can assist us in developing applications that efficiently process large amounts of text. SpaCy is performing analytical activity by using text classification in python.
- Text classification is a typical task in NLP. It is the traditional meaning of machine learning and is used to classify text.
- There are a few alternative approaches we can use. The first method is word tokenization, which divides the text into individual words.
Using spaCy text classification
- To do text classification, we will use the spaCy library. If the text has labels, it is a supervised learning problem; else, it is unsupervised. It is very useful in python.
- If the text has labels, we may start with data cleaning immediately, but we must use clustering to find the clusters for better classification if the labels are unknown.
- Then, a text classification label can be created depending on the common topic in each cluster.
- We extract features after cleaning the data. The data is then fed into our machine learning algorithms, which do the categorization.
- To use spaCy text classification, we need to install spaCy in our system. Below are the steps to install spaCy and load the module in our system.
- In this step, we install the spaCy package using the pip command. In the below example, we have already installed the spaCy package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
pip install spaCy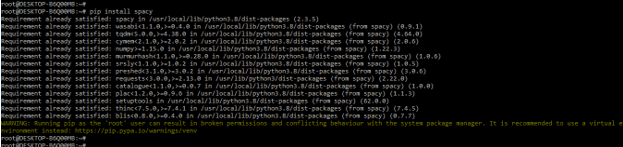
- After installing all the modules, we open the python shell using the python3 command.
python3
- After logging into the python shell in this step, we check spaCy package is installed in our system.
import spaCy
print (spaCy )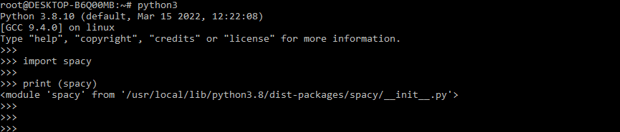
- After installing the spaCy, we also need the sklearn package to use spaCy text classification in our program. In this step, we are installing sklearn by using the pip command.
pip install 'sklearn'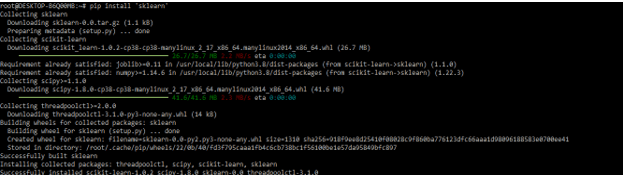
- After installing the spaCy module in this step, we import the below libraries into our program. In the below example, we have imported the spaCy, pandas, TransformerMixin, and Pipeline libraries.
Code –
import spaCy
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
- After importing all the modules in this step, we load the data. We are loading the data by using CSV files. We are using the csv file name text.csv.
Code –
py_text = pd.read_csv ("text.csv", sep="\t")
print (f'Data: {py_text.shape}')
py_text.head()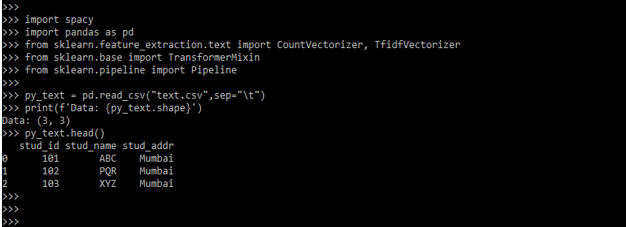
- In the above example, we loaded the data using a csv file; in this step, we understand the data. The data contains three columns, i.e., stud_id, stud_name, and stud_addr. Stud_id contains the student’s id, and another column is the name and address of the student.
- After understanding data from the csv files in this step, we give the data information from a csv file.
py_text.info()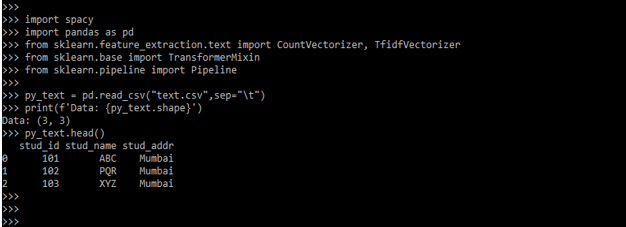
- After giving the data information, we see the specific number of data as per the column in this step. In the below example, all the data from the stud_id column are as follows.
py_text.stud_id.value_counts()
- We can also do the data cleaning by using spaCy text classification. To sanitize the tokenized data, we will develop a custom transformer. We will make our own predictions class that derives from TransformerMixin. The transform, fit and get params functions are overridden in this class. A mixin class in object-oriented programming languages contains methods for usage by other classes without needing any other parent class. The below example shows data cleaning by using spaCy text classification as follows.
Code –
class classification (TransformerMixin):
def py_tran (self, X, **transform_params):
"""py_tran method"""
return [py_clean (py_text) for py_text in X]
def fit(self, X, y= None, **fit_params):
return self
def get_params (self, deep= True):
return {}
def py_clean(py_text):
"""py_text in spaCy text classification."""
return py_text.strip ().lower()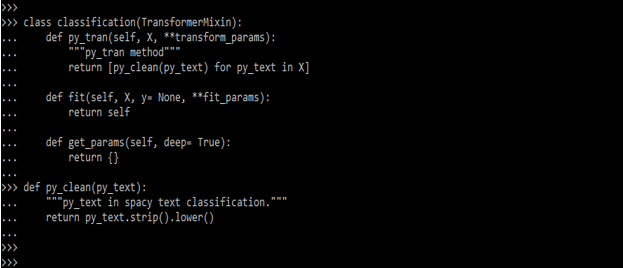
- We can also clean data by removing stopwords in spaCy text classification. Most of the text material we work on contains many words we will never utilize. Stopwords are removed from our text data to reduce noise and distraction and speed up time analysis activities. The below example shows cleaning the text data by using spaCy text classification.
Code –
import spaCy
py_word = spaCy .lang.en.stop_words.STOP_WORDS
print('SpaCy text classification spaCy _stopwords: %d' % len(py_word))
print ('First spaCy _stopwords: %s' % list(py_word)[:20])
- SpaCy’s default stopwords list has three hundred and twelve total entries, each of which is a single word. We can also understand why many of these words aren’t appropriate for data analysis. For example, transitions aren’t required to grasp a sentence’s essential meaning. On the other hand, other terms, like somebody are too ambiguous to be helpful in NLP tasks.
- In the end, normalization reduces high-dimensional features to low-dimensional features that may be used in ML.
- In spoken language, the discrepancies in spelling have grammatical functions, but they might be difficult for a machine to process.
Conclusion
Text classification is a typical task in NLP. SpaCy text classification is the traditional meaning of machine learning and is used to classify text. It is commonly utilized in the circumstances such as separating the text’s core theme and organizing customer service emails by complaint type.
Recommended Article
We hope that this EDUCBA information on “spaCy Text Classification” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

