Updated March 29, 2023

Definition of spaCy Tokenizer
SpaCy tokenizer generates a token of sentences, or it can be done at the sentence level to generate tokens. We can also perform word tokenization and character extraction. Words, punctuation, spaces, special characters, integers, and digits are all examples of tokens. Tokenization is the first stage in any text processing pipeline, whether it’s for text mining, text classification, or other purposes. SpaCy tokenizer is very useful and important in python.
What is spaCy tokenizer?
- To begin, the model for the English language must be loaded using a command like spaCy.load (‘en’). As a consequence, an instance of the spaCy language class is created.
- Tokenization is the initial stage in tokens that are required for all other NLP operations.
- Along with NLTK, spaCy is a prominent NLP library. The difference is that NLTK has a large number of methods for solving a single problem, whereas spaCy has only one, but the best approach for solving a problem. NLTK was first released in 2001, but spaCy was first developed in 2015.
Creating spaCy tokenizer
- First we need to install the same in our system. The below example shows the installation by using the pip command. In the below example, we have installed on Linux based systems.
pip install spacy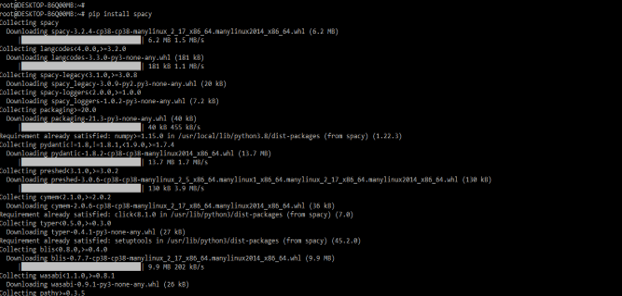
- After installing the spaCy we need to check it is properly installed on our system, we need to login into the python shell first to import the spaCy module. The below example shows login into the python shell are as follows.
python3
- After login into the python shell, we are checking scrapy tokenizer is properly installed on our system. We can check the same by importing the spaCy module into our code. We can import the spaCy tokenizer module by using the import keyword. The below example shows how to import the spaCy module into our program as follows.
import spacy
print (spacy)
- Words and punctuation is broken down into several steps in SpaCy. From left to right, the text is processed.
- To begin, the tokenizer is separated in the same way that the split method does. After that, the tokenizer examines the substring. Isn’t, for example, has no whitespace and should be divided into two tokens, “is” and “n’t,” although “N.A.” should always be one token.
- Commas, periods, hyphens, and quotations are examples of prefixes, suffixes, and infixes that can be found in a substring.
- We’re tokenizing text with spaCy in the example below. To print the tokens of doc objects in the output, we first imported the SpaCy library.
Code:
import spacy
py_nlp = spacy.load ("en_core_web_sm")
py_doc = py_nlp ("Spacy tokenizer in python")
for py_token in py_doc:
print (py_token.text)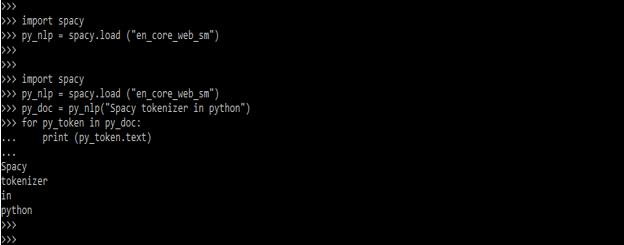
- Below is the point related in python as follows. In the below example, we are creating the spaCy tokenizer.
- We can easily add our custom-generated tokenizer to the spaCy pipeline. For instance, in the code below, we’ve included a blank Tokenizer that only has English vocab.
- We can see in the below example it will show the token which we have added.
Code:
from spacy.tokenizer import Tokenizer
from spacy.lang.en import English
py_nlp = English ()
py_tokenizer = Tokenizer (py_nlp.vocab)
py_tokens = py_tokenizer ("Python spacy tokenizer isn't N.A.")
print ("Blank tokenizer", end=" : ")
for py_tokens in py_tokens:
print (py_tokens, end=', ')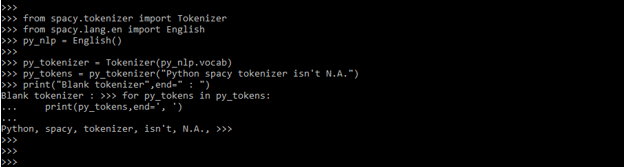
- In the below example, we have segregated each token by using the spaCy tokenizer as follows.
Code:
from spacy.lang.en import English
nlp = English()
py_tokenizer = nlp.tokenizer
py_token = py_tokenizer ("Python spaCy tokenizer isn't N.A.")
print ("\nDefault tokenizer",end=' : ')
for token in py_token:
print (token, end=', ')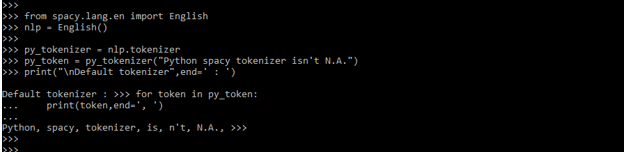
- tokenizer.explain (text) is a debugging tool supplied by the spaCy library that produces a list of tuples containing the token. The below example shows debugging which is as follows.
Code:
from spacy.lang.en import English
py_nlp = English()
py_text = "Python spacy tokenizer isn't N.A."
py_doc = py_nlp(py_text)
py_tok = py_nlp.tokenizer.explain(py_text)
for t in py_tok:
print (t[1], "\t", t[0])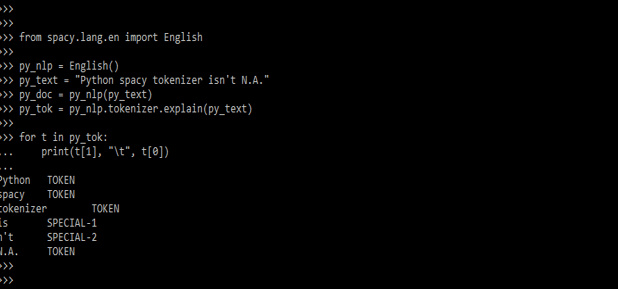
- By supplying tokenizer.merge, we may combine many tokens into a single token. We can set attributes that will be allocated to the merged token using an optional dictionary of attrs. The merged token inherits the same properties as the merged span’s root by default. The below example shows merging tokens.
Code:
import spacy
py_nlp = spacy.load("en_core_web_sm")
py_doc = py_nlp ("Python spaCy tokenizer isn't N.A.")
print("Before:", [token.text for token in py_doc])
with py_doc.retokenize() as retokenizer:
retokenizer.merge (py_doc[3:5], attrs={"Python": "spacy tokenizer"})
print ("After:", [token.text for token in py_doc])
- The entire dependency parse is used by the spaCy library to establish sentence boundaries. SpaCy tokenizer is a very accurate method but necessitates a well-trained pipeline that can make correct predictions. The below example shows parse dependency.
Code:
import spacy
py_nlp = spacy.load ("en_core_web_sm")
py_doc = py_nlp ("python spaCy tokenizer. This python spaCy tokenizer.")
for sent in py_doc.sents:
print(sent.text)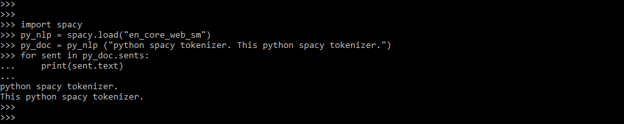
- The data is statistical. The parser that just provides sentence boundaries is replaced by Sentence Recognizer. The below example shows spaCy tokenizer by using a statistical sentence segmenter.
Code:
import spacy
py_nlp = spacy.load ("en_core_web_sm", exclude=["parser"])
py_doc = py_nlp("python spacy tokenizer. This python spacy tokenizer.")
for sent in py_doc.sents:
print (sent.text)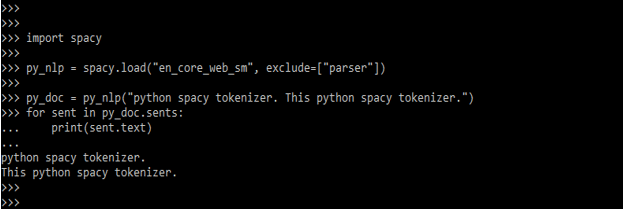
- The below example shows removing the character from the search by using spaCy tokenizer as follows.
Code:
from spacy.lang.en import English
import spaCy
py_nlp = English()
py_text = "python (spacy) tokenizer."
py_doc = py_nlp (py_text)
print("Default sentence", end=' : ')
for token in py_doc:
print (token, end=', ')
suffixes = list (py_nlp.Defaults.suffixes)
suffixes.remove ("\(")
suffix_regex = spacy.util.compile_suffix_regex (suffixes)
py_nlp.tokenizer.suffix_search = suffix_regex.search
print ('\nSuffix removed text', end=' : ')
py_doc = py_nlp(py_text)
for token in py_doc:
print (token,end=', ')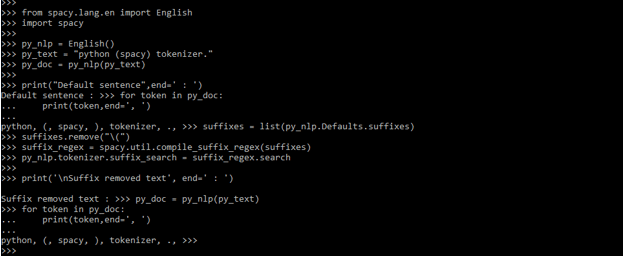
Conclusion
Tokenization is the process of breaking down a text into little chunks known as tokens. Tokenization can be done to generate sentence tokens, sentence tokenization to generate word tokens, or word tokenization to generate character tokens. The substring is divided into two tokens if it matches.
Recommended Articles
This is a guide to SpaCy tokenizer. Here we discuss the definition, What is spaCy tokenizer, Creating spaCy tokenizer, examples with code implementation. You may also have a look at the following articles to learn more –

