Updated March 23, 2023
Introduction to Spark Functions
Spark Functions are the operations on the dataset that are mostly related to analytics computation. Spark framework is known for processing huge data set with less time because of its memory-processing capabilities. There are several functions associated with Spark for data processing such as custom transformation, spark SQL functions, Columns Function, User Defined functions known as UDF. Spark defines the dataset as data frames. It helps to add, write, modify and remove the columns of the data frames. It support built-in syntax through multiple languages such as R, Python, Java, and Scala. The Spark functions are evolving with new features.
List of Spark Functions
Now let us see some spark functions used in Spark.
1. Custom Transformation
Whenever we are adding columns, removing columns, adding rows or removing from a Data Frame we can use this custom transformation function of Spark.
The generic method signature for this is:-
def customTransformName(arg1: String)(df: DataFrame): DataFrame = {
// code that returns a DataFrame
}
Let us suppose we are working over a data frame and adding a column into it using the with column function.
The same thing can be achieved with the help of custom transformations in spark. We can refactor the code and eliminate the other dependent variable that makes the code well structured.
Let us see an example over custom transformation:-
Suppose we have a data frame:-
Val df = List((“Arpit”),(“Anand”)).toDF(“Name”)
Now we want to add two columns over the DF with the Address and State:-
Val df2 = df.withcolumn(“Address”,lit(“Bangalore”))
Val df3 = df2.withcolumn(“State”,lit(“karnataka”))
Df3.show()
This will show the dataframe that is produced with the new columns added as Address and State.

The same can be achieved with custom transformation as we can use the transform method over the dataframe to transform the data frame accordingly.
Let us see how it works:-
def Address()(df: DataFrame): DataFrame = {
df.withColumn(
"Address",
lit("Bangalore")
)
}
def State()(df: DataFrame): DataFrame = {
df.withColumn(
"State",
lit("karnataka")
)
}
Using the above data frame used and using the .transform function it will be like:-
transform(Address())
.tansform(State()).show()
It will have the same data frame result as above so here we can see how by using the transform method.
2. SPARK SQL FUNCTIONS
Spark comes over with the property of Spark SQL and it has many inbuilt functions that helps over for the sql operations.
Some of the Spark SQL Functions are :-
Count,avg,collect_list,first,mean,max,variance,sum .
Suppose we want to count the no of elements there over the DF we made.
A simple .count () function will count over the number of rows present over the dataframe.
df3.count()
2 // It will give the output as 2 counting the rows over the dataframe.
In this way only there are lots of SQL functions over there which we can use all over the code.
These functions are used for the columns of a data frame producing the type of result designed for.
3. COLUMNS FUNCTIONS
It returns the Column Objects. It can be used as the spark SQL functions with the columns over which needed to be implemented.
So here we are passing a column value as an input parameter, a set of action is performed over that functions and the result is returned back into data Frame.
4. USER DEFINED FUNCTIONS
There are several user-defined functions also that are used in spark under which a user can create an own set of functions with the rule defined in it all over and can use it over the code when needed.
They are similar to column function but they use Scala over Spark API.
Now let us create a UDF and check how It can help over the spark applications:-
def toUpperFunction(str: String): Option[String] = {
val s = Option(str).getOrElse(return None)
Some(s.toUpperCase())
}
val toUpper = udf[Option[String], String](toUpperFunction)
Here we made a UDF that converts the word to upper Case so whatever the column value we will be passing over there it will convert that into uppercase.
So this is a function which we are defining over own and using it over the data frames in spark application.
So the Dataframe we had earlier
Val df = List((“Arpit”),(“Anand”)).toDF(“Name”)
While passing our function over the column name we will get a new data frame as the changed one.
df.withcolumn(“toUpper”,toUpper(col(“Name”))).show()
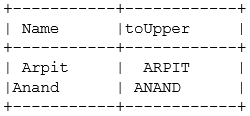
So here we can see that these set of functions can be explicitly defined by the user and can be passed over desired results.
Conclusion
So by this above article, we can see that we are having a scope of large no of spark functions that we can use over and over again in our spark application.
Recommended Articles
This is a guide to Spark Functions. Here we discuss some of the spark functions used in Spark along with the examples and workings. You may also have a look at the following articles to learn more –
