Updated February 27, 2023

Introduction to Spark Parallelize
Parallelize is a method to create an RDD from an existing collection (For e.g Array) present in the driver. The elements present in the collection are copied to form a distributed dataset on which we can operate on in parallel. In this topic, we are going to learn about Spark Parallelize.
Parallelize is one of the three methods of creating an RDD in spark, the other two methods being:
- From an external data-source like a local filesystem, HDFS, Cassandra, etc.
- By running a transformation operation on an existing RDD.
Syntax:
sc.parallelize (seq: Seq[T],numSlices: Int)
Here sc is the SparkContext object,
seq is a collection object which is present in the driver program,
numSlices is an optional parameter and it denotes the number of partitions that will be created for the dataset. Spark runs one task for each partition. Thus, it’s important in the sense that governs the number of parallel operations being performed.
How to Use the method?
In order to use the parallelize() method, the first thing that has to be created is a SparkContext object.
It can be created in the following way:
1. Import following classes :
org.apache.spark.SparkContext
org.apache.spark.SparkConf
2. Create SparkConf object :
val conf = new SparkConf().setMaster("local").setAppName("testApp")
Master and AppName are the minimum properties that have to be set in order to run a spark application.
3. Create SparkContext object using the SparkConf object created in above step:
val sc = new SparkContext(conf)
The next step is to create a collection object.
Let’s see some commonly used collections which can be parallelized to form RDD:
Array: It is a special type of collection in Scala. It is of fixed size and can store elements of same type. The values stored in an Array are mutable.
An array can be created in the following ways:
var arr=new Array[dataType](size)
After creating the variable arr we have to insert the values at each index.
var arr=Array(1,2,3,4,5,6)
Here we are providing the elements of the array directly and datatype and size are inferred automatically.
Sequence: Sequences are special cases of iterable collections of class iterable. But contrary to iterables, the sequence always has defined order of elements. A sequence can be created by:
var mySeq=Seq(1,2,3,4,5,6)
List: Lists are similar to Arrays in the sense that they can have only same type of elements. But there’s two significant differences: 1) Elements of a list cannot be modified unlike Array and 2) A list represent a linked list.
A list can be created by:
Val myList=List(1,2,3,4,5,6)
Now that we have all the required objects, we can call the parallelize() method available on the sparkContext object and pass the collection as the parameter.
Examples of Spark Parallelize
Here are the following examples mention below:
Example #1
Code:
val conf= new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd1= sc.parallelize(Array(1,2,3,4,5))
println("elements of rdd1")
rdd1.foreach(x=>print(x+","))
println()
val rdd2 = sc.parallelize(List(6,7,8,9,10))
println("elements of rdd2")
rdd2.foreach(x=>print(x+","))
println()
val rdd3=rdd1.union(rdd2)
println("elements of rdd3")
rdd3.foreach(x=>print(x+","))
Output:
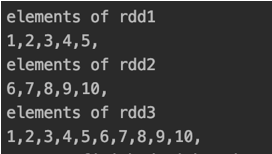
In the above code First, we created sparkContext object (sc) and the created rdd1 by passing an array to parallelize method. Then we created rdd2 by passing a List and finally, we merged the two rdds by calling the union method one rdd1 and passing rdd2 as the argument.
Example #2
Code:
val conf= new SparkConf().setAppName("test").setMaster("local")
val sc =new SparkContext(conf)
val spark=SparkSession.builder().config(conf).getOrCreate()
sc.setLogLevel("ERROR")
val line1 = "live life enjoy detox"
val line2="learn apply live motivate"
val line3="life detox motivate live learn"
val rdd =sc.parallelize(Array(line1,line2,line3))
val rdd1 = rdd.flatMap(=>x.split(" "))
import spark.implicits x._
val df = rdd1.toDF("word")
df.createOrReplaceTempView("tempTable")
val rslt=spark.sql("select word,COUNT(1) from tempTable GROUP BY word ")
rslt.show(1000,false)
Output:
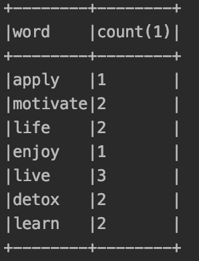
The above code represents the classical word-count program. We used spark-sql to do it. To use sql, we converted the rdd1 into a dataFrame by calling the toDF method. To use this method, we have to import spark.implicits._. We registered the dataFrame(df ) as a temp table and ran the query on top of it.
Example #3
Code:
val conf= new SparkConf().setAppName("test").setMaster("local")
val sc =new SparkContext(conf)
sc.setLogLevel("ERROR")
val myRdd=sc.parallelize(Seq(1,1,1,10,10,5,100,100,100,200,400),10)
println("Printing myRdd: ")
myRdd.foreach(x=>print(x+" "))
println()
val newRdd= myRdd.distinct()
println("Printing newRdd: ")
newRdd.foreach(x=>print(x+" "))
Output:
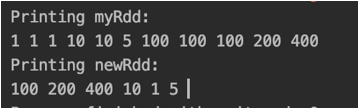
In the above code, we have created an RDD(myRdd) using a sequence and have passed numSlices as 10. Then, we have called the distinct method which gives the distinct elements of in the RDD. As expected the output prints the distinct elements.
Conclusion
In this article, we have learned how to create RDDs using the parallelize() method. This method is mostly used by beginners who are learning spark for the first time and in a production environment, it’s often used for writing test cases.
Recommended Articles
This is a guide to Spark Parallelize. Here we discuss how to use the Spark Parallelize method and examples for better understanding. You may also look at the following articles to learn more –
