Updated March 4, 2023

Introduction to Spark RDD Operations
Spark RDDs support two types of operations:
- Transformation: A transformation is a function that returns a new RDD by modifying the existing RDD/RDDs. The input RDD is not modified as RDDs are immutable.
- Action: It returns a result to the driver program (or store data into some external storage like hdfs) after performing certain computations on the input data.
All transformations are executed by Spark in a lazy manner. The results have not computed right away. Computation of the transformations happens only when a certain action is performed on the RDD.
Transformations and Actions
Given below are the transformations and actions:
1. Transformations
They are broadly categorized into two types:
Narrow Transformation:
- All the data required to compute records in one partition reside in one partition of the parent RDD.
- It occurs in the case of the following methods:
map(), flatMap(), filter(), sample(), union() etc.
Wide Transformation:
- All the data required to compute records in one partition reside in more than one partitions in the parent RDDs.
- It occurs in the case of the following methods:
distinct(), groupByKey(), reduceByKey(), join(), repartition() etc.
2. Actions
Transformations just create an RDD from another RDD/RDDs, but when we want to see any result we have to call an action upon it. When an action is called upon any RDD, the result is not an RDD, rather some result is thrown to the driver program, or some data gets stored in some external storage. Thus, action is a way of sending back some result from the executors to the driver.
Some commonly performer actions are:
count(), collect(), take(), reduce(), saveAsTextFile() etc.
Examples of Spark RDD Operations
Given below are the examples of Spark RDD Operations:
Transformations:
Example #1 map()
This function takes a function as a parameter and applies this function to every element of the RDD.
Code:
val conf = new SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(10,15,50,100))
println("Base RDD is:")
rdd.foreach(x => print(x+" "))
println()
val rddNew = rdd.map(x => x+10)
println("RDD after applying MAP method:")
rddNew.foreach(x => print(x+" "))
Output:
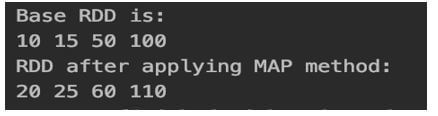
In the above MAP method, we are adding each element by 10 and that is reflected in the output.
Example #2: filter()
It takes a function as a parameter and returns all elements of the RDD for which the function returns true.
Code:
val conf = new SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array("com.whatsapp.prod","com.facebook.prod","com.instagram.prod","com.whatsapp.test"))
println("Base RDD is:")
rdd.foreach(x => print(x+" "))
println()
val rddNew = rdd.filter (x => !x.contains("test"))
println("RDD after applying MAP method:")
rddNew.foreach(x => print(x+" "))
Output:

In the above code, we are taking strings that don’t have the word “test”.
Example #3: distinct()
This method returns the distinct elements of the RDD.
Code:
val conf = new
SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(1,1,3,4,5,5,5))
println("Base RDD is:")
rdd.foreach(x => print(x+" "))
println()
val rddNew = rdd.distinct()
println("RDD after applying MAP method:")
rddNew.foreach(x => print(x+" "))
Output:
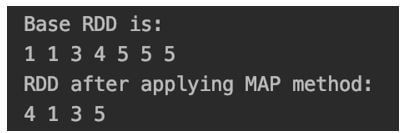
We are getting the distinct elements 4,1,3,5 in the output.
Example #4: join()
The join operation is applicable to pair-wise RDDs. A pair-wise RDD is one whose each element is a tuple where the first element is the key and the second element is the value. The join method combines two datasets based on the key.
Code:
val conf = new SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd1 = sc.parallelize(Array(("key1",10),("key2",15),("key3",100)))
val rdd2 = sc.parallelize(Array(("key2",11),("key2",20),("key1",75)))
val rddJoined = rdd1.join(rdd2)
println("RDD after join:")
rddJoined.foreach(x => print(x+" "))
Output:

Actions:
Example #5: count()
This function gives the number of elements in the RDD.
Code:
val conf = new
SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10))
val cnt= rdd.count()
println("The count is "+cnt)
Output:

As expected we are getting the count of elements in the RDD.
Example #6: collect()
This method brings all the elements in the RDD as an array to the driver. The constraint with this method is that all the data must fit in the driver. This method is generally used while writing test cases where the expected number of elements is smaller and known beforehand.
Code:
val conf = new
SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10))
val arr= rdd.collect()
println("Printing the elements in the array")
arr.foreach(x => print(x+" "))
Output:

In the above code, we are fetching all the elements in the RDD into the array “arr” and then printing each element.
Example #7: countByKey()
This function is applicable to pair-wise RDDs. We have previously discussed what are pair-wise RDDs. It returns a hash map containing the count of each key.
Code:
val conf = new SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(("a",10),("a",5),("b",1),("b",4),("a",5),("c",20)))
val map= rdd.countByKey()
Output:

In the above cases, there are 3 keys a,b and c and in the output, we are getting how many times each key occurs in the input.
Example #8: reduce()
This function takes another function as a parameter which in turn takes two elements of the RDD at a time and returns one element. This is used for aggregation.
Code:
val conf = new
SparkConf().setMaster("local").setAppName("testApp")
val sc= SparkContext.getOrCreate(conf)
sc.setLogLevel("ERROR")
Output:
![]()
In the above code, we are passing a function to reduce which adds the two elements it receives, thus in the output we are getting the SUM of all the elements in the input.
Conclusion
In this article, we saw how to use transformations to produce different RDDs. We also saw the transformation are lazy in nature and only computed when some action is called upon. We also saw various actions that are performed frequently on RDDs.
Recommended Articles
This is a guide to Spark RDD Operations. Here we discuss the introduction, transformations, and actions, examples respectively. You may also have a look at the following articles to learn more –
