Updated August 8, 2023
Introduction to SQL COUNT DISTINCT
SQL, standing for Structured Query Language, wields significant prowess as a versatile instrument in the realm of database management and querying. One of the fundamental operations in SQL is data aggregation, which involves summarizing and analyzing data to gain insights. The COUNT DISTINCT function is a valuable component of SQL’s aggregation capabilities.
When working with data, knowing how many total records exist and how many unique values are present in a specific column is essential. This is where the COUNT DISTINCT function comes into play. Unlike the regular COUNT function, which counts the total number of rows, COUNT DISTINCT focuses on counting the number of distinct (unique) values within a particular column.
Using the count function, we can find the number of records for values of the resultset of the particular query in SQL. Further, there can be redundancy which means repetition of the same values for the specific result set. We can use distinct SQL functions to retrieve the unique values from the result set of the specific query statement’s output. We can use the functions count and distinct togetherly to find the number of records with different values from the resultset. Using both functions togetherly can prove helpful in many situations in real-time case scenarios, such as retrieving the count of the grouped values with distinct records.
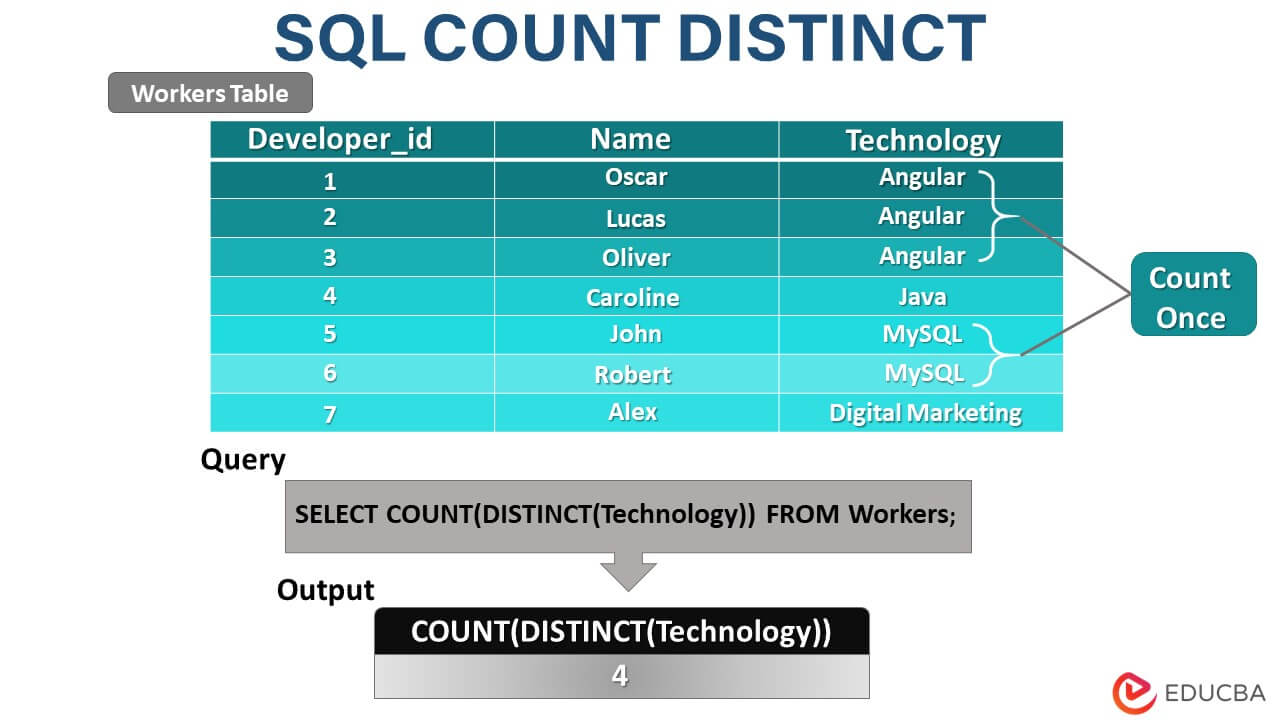
Table of Contents
Key Takeaways
- A SQL function called COUNT DISTINCT determines how many values in a table column are distinct and do not repeat.
- It enables you to obtain a count of unique occurrences while eliminating duplicates, giving you important information about the cardinality of the data.
- It aids in effectively gathering and summarising unique values and is especially helpful when working with large datasets.
Syntax
1. Basic Syntax of SQL COUNT DISTINCT
COUNT ([DISTINCT] expression_or_value);The expression_or_value can be any of the column names of expression involving other aggregated functions, leading to the retrieval of many values that might have duplicate values.
To get unique values from the records, we will use the DISTINCT keyword before the expressions, and finally, to get only the number of records of those distinct values, we can use the COUNT function that will wrap the contents.
2. Including column names in COUNT DISTINCT
SELECT COUNT(DISTINCT column1)
FROM table_name;When using the COUNT DISTINCT syntax, you can specify several columns by enclosing each column’s name in parentheses.
3. Using Aliases with COUNT DISTINCT
SELECT COUNT(DISTINCT column_name) AS alias_name
FROM table_name;For easier reading, you can give the outcome of the count operation a name or an alias when using COUNT DISTINCT in SQL syntax.
Performance and Optimization of SQL COUNT DISTINCT
There are a few important factors to consider regarding the performance and optimization of the SQL COUNT DISTINCT operation.
- Indexing: Check if the column you are running, COUNT DISTINCT, is indexed. Indexes improve query performance by enabling the database to quickly find and obtain the required data. If the field is not indexed, the database may have to run a full table scan, which would slow down query execution.
- Data Distribution: Examine the data distribution in the counted column. The query should function effectively if the values are distributed equally. High-skewed distributions can affect performance, in which some values occur noticeably more frequently than others. You might consider using different strategies to boost performance in certain situations, such as sampling or pre-aggregating data.
- Query Optimization: Review the execution plan produced by the database optimizer to improve the query. The optimizer chooses the most effective strategy to execute the query depending on variables, including the availability of indexes, statistics, and query structure. Make that the query is well-formed, and if required, rewrite it to optimize performance.
- Data Modeling: Check your data model to ensure the design fits the queries being run. The COUNT DISTINCT searches can occasionally be made more efficient by denormalizing or reorganizing the data. To save aggregated data, this can need adding extra columns or tables.
Purpose and Benefits of Using SQL COUNT DISTINCT
The COUNT Distinct in SQL determines the number of unique or distinct values in a specific column or a combination of the columns within a table. It allows you to count only the individual value occurrences, excluding duplicates.
Here are some benefits of using COUNT Distinct:
- Counting Distinct Values: The COUNT Distinct function allows you to find the number of distinct values in a column. This is helpful when determining the diversity or uniqueness of the data included inside a dataset.
- Data Analysis: By using COUNT Distinct, you may analyze data and learn more about how values are distributed and vary. It aids in the discovery of trends, outliers, or anomalies in your data.
- Eliminating Duplicates: COUNT Distinct allows you to eliminate duplicates from the count if a table contains duplicate data, and you need to calculate the number of unique occurrences.
- Data Reporting and Synthesis: COUNT Distinct is frequently used in data reporting and synthesis. It offers useful data that can be used to create statistical reports, compute averages, recognize distinct groupings, or give summaries depending on particular values.
Limitations of Using SQL COUNT DISTINCT
Here are a few limitations to consider:
- Memory Requirements: COUNT DISTINCT may use a lot of memory, especially when processing columns with many unique values. The query may become slow or fail if the number of different values exceeds the available RAM.
- Understanding Context: COUNT DISTINCT does not consider the context or connections between columns. It only works independently on one column, making it less useful to count distinct data sets across several columns.
- Scalability: The effectiveness and scalability of COUNT DISTINCT may decline as the dataset gets bigger. Complex conditions or queries that require counting distinct values across numerous columns may be harder to optimize and efficiently execute.
- Considerations for Data Types: COUNT DISTINCT distinguishes values based on their data type rather than semantic content. For instance, if a column contains the same values in both uppercase and lowercase, COUNT separately will treat them as different, which could produce unreliable results.
Difference Between SQL COUNT and SQL COUNT DISTINCT
| Aspects | SQL COUNT | SQL COUNT DISTINCT |
| Purpose | It is used to COUNT a total number of rows or occurrences. | It is used to count the UNIQUE/DISTINCT occurrences. |
| Performance | It is faster since it counts all occurrences. | It is slower as it identifies unique/distinct values. |
| Counts | It counts all occurrences, including duplicates. | It counts unique occurrences excluding duplicates. |
| Usage | It is useful for determining the total number of records in a table. | It is useful for identifying the number of unique or distinct values. |
| Results | It returns a single value representing the count. | It returns a single value representing the count of unique/ Distinct occurrences. |
Example of SQL COUNT DISTINCT
Consider one example; we will create one table named workers with the help of the following CREATE TABLE statement in SQL.
CREATE TABLE Workers (
Developer_id INT(11) NOT NULL,
Team_id INT(11) NOT NULL,
Name VARCHAR(100) DEFAULT NULL,
Position VARCHAR(100) DEFAULT NULL,
Technology VARCHAR(100) DEFAULT NULL,
Salary INT(11) DEFAULT NULL
);Let us insert some records in the table workers with the help of the following INSERT query statement.
INSERT INTO Workers (Developer_id, Team_id, Name, Position, Technology, Salary)
VALUES
(1, 1, 'Oscar', 'Developer', 'Angular', 30000),
(2, 1, 'Lucas', 'Developer', 'Angular', 10000),
(3, 3, 'Elias', 'Manager', 'Maven', 25000),
(4, 3, 'Alex', 'Support', 'Digital Marketing', 15000),
(5, 3, 'Siddhesh', 'Tester', 'Maven', 20000),
(6, 7, 'Caroline', 'Manager', 'Java', 25000),
(7, 4, 'Brahma', 'Developer', 'Digital Marketing', 30000),
(8, 1, 'Oliver', 'Tester', 'Angular', 19000),
(9, 2, 'John', 'Developer', 'MySQL', 20000),
(10, 2, 'Robert', 'Administrator', 'MySQL', 30000),
(11, 2, 'David', 'Admin', NULL, 20000),
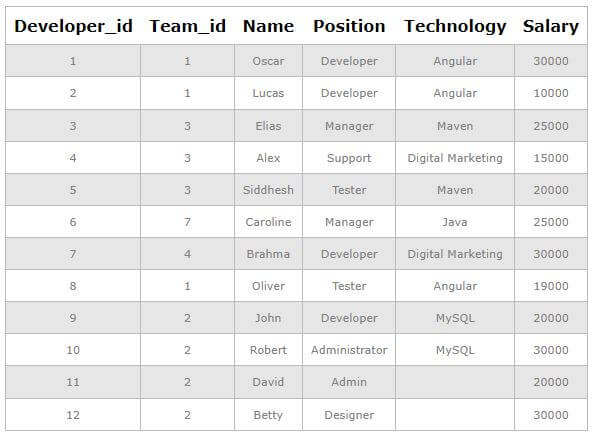
(12, 2, 'Betty', 'Designer', NULL, 30000);Let us retrieve the records from the worker’s table by using the select query statement.
SELECT * FROM Workers;Output:
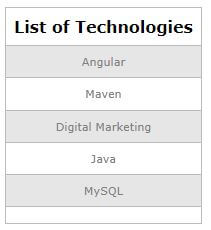
Suppose we want to retrieve all the workers’ technologies at the table. We will use the column technology to get the list of all the technologies. But it can be seen from the above output that there are many duplicate records for each technology value. Hence, we must use the DISTINCT() function to get the list of unique technologies stored in the workers’ table.
Code:
SELECT DISTINCT(Technology) AS 'List of Technologies' FROM Workers;Output:
Now, let us calculate the total number of workers with technology in the table using the COUNT() function in the following query statement.
Code:
SELECT COUNT(*) as Technology FROM Workers;Output:

Hence, we can see 12 workers with technology in total. This count will contain all the records with duplicate technology values in it. If we want to get the number of technologies with distinct values considered, we can use the COUNT and DISTINCT functions together, as shown in the query statement below.
Code:
SELECT COUNT(DISTINCT(Technology)) FROM Workers;Output:
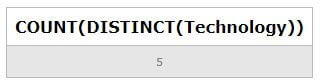
Let us change the values of the NULL technology column and then find the distinct count of technologies again.
We will use the following update query to replace the NULL value in technology with SQL.
Code:
UPDATE Workers SET Technology = 'SQL' WHERE Technology IS NULL;Let us retrieve and check the records of the table.
Code:
SELECT * FROM Workers;Output:
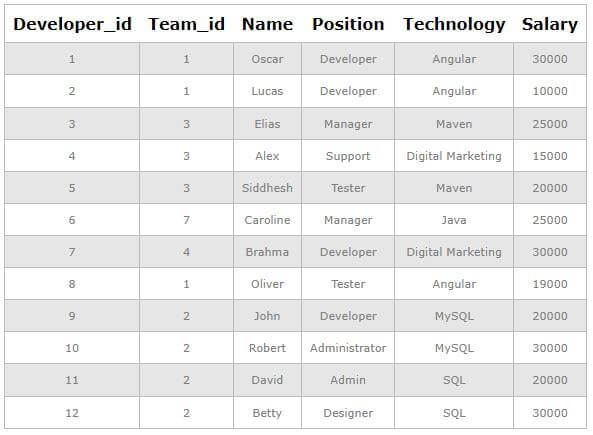
Now, we will again find out the count of distinct technologies, and not SQL will also be considered in that count.
Code:
SELECT COUNT(DISTINCT(Technology)) FROM Workers ;Output:
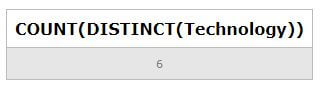
Suppose we have to find out the workers’ table’s unique positions; then, we will use the following query statement.
Code:
SELECT DISTINCT(Position) AS 'List of Positions' FROM Workers;Output:

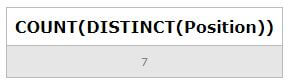
In the following query statement lets us retrieve the count of distinct positions in the workers’ table.
Code:
SELECT COUNT(DISTINCT(Position)) FROM Workers;Output:
FAQs
Q1. How do I count distinct in SQL?
Ans: To count distinct values in SQL, you can use the COUNT(DISTINCT column_name) function. This function will return the number of unique or non-repeated values in the specified column.
Q2. How to remove duplicates in SQL?
Ans: To remove duplicates from the table in SQL, you can use the DISTINCT keyword in combination with the INSERT INTO statement. The DISTINCT keyword completely removes duplicate rows from the result set.
Q3. How to check duplicate data in SQL queries?
Ans: You can use the GROUP BY and HAVING clauses to check duplicate data in SQL. The GROUP BY clause groups the rows based on the specified columns, and the HAVING clause filters the groups based on specified conditions.
Conclusion
We can use the COUNT function to get the number of records from a particular table. We can add the DISTINCT keyword inside the COUNT function, which will lead to considering unique records while getting the count of records in SQL. DISTINCT keywords and functions help us to retrieve the unique records in SQL.
Recommended Articles
We hope this EDUCBA information on “SQL COUNT DISTINCT” benefited you. You can view EDUCBA’s recommended articles for more information.
