Introduction
Super-Resolution Generative Adversarial Networks (SRGANs) represent a cutting-edge approach to enhancing image resolution. They are not just a technological advancement but a game-changer in various domains. Utilizing the potential of Generative Adversarial Networks (GANs), SRGANs generate high-resolution images with realistic details and improved perceptual quality. This fusion of SR and GANs has revolutionized the field, offering a promising solution to upscale images while preserving crucial details. This article delves into the architecture, training process, advantages, and applications of SRGANs, highlighting their significant impact in various domains.

Table of Contents
What is Super-Resolution?
Super-resolution (SR) is a computational imaging technique used to increase the resolution of an image beyond its original dimensions while retaining or improving its quality. It involves reconstructing high-resolution images from low-resolution counterparts by predicting missing details and increasing the level of image detail. SR algorithms utilize various approaches, including interpolation, edge enhancement, and deep learning-based methods, to achieve this enhancement. Traditional SR methods often rely on interpolation techniques, resulting in blurry images lacking fine details. However, recent advancements, particularly in deep learning, have led to the development of more sophisticated SR techniques, like convolutional neural networks (CNNs) and Generative Adversarial Networks (GANs). These methods leverage large datasets to learn complex mappings between low and high-resolution image pairs, enabling them to generate realistic and visually pleasing high-resolution images with improved perceptual quality.
Limitations of Traditional SR methods
- Reliance on simple interpolation techniques or basic filtering operations may result in blurred or unrealistic details, particularly when upscaling significantly.
- Difficulty handling complex image content and variations in texture and structure can lead to artifacts and distortion in generated images.
- Lack of consideration for semantic information or high-level features may result in losing essential details and visually unconvincing results.
- Computational expense and the need for manual parameter tuning make traditional SR algorithms less practical for real-time or large-scale image processing tasks.
- These limitations emphasize the need for more advanced, data-driven approaches, such as Generative Adversarial Networks (GANs), to overcome challenges and achieve superior super-resolution results.
Generative Adversarial Networks (GAN)
GANs comprise two neural networks: a generator and a discriminator, trained simultaneously in a competitive process. The generator aims to generate realistic data samples, such as images, from random noise, while the discriminator seeks to differentiate between real data samples and those generated by the generator.
During training, the generator learns to generate progressively real samples by receiving feedback from the discriminator. Simultaneously, the discriminator improves its ability to distinguish between real and fake samples. This adversarial training process leads to both networks improving over time, with the generator eventually producing high-quality samples that are indistinguishable from real data.
The generator typically consists of several layers of neural networks, often using convolutional or deconvolutional layers to transform random noise into meaningful data samples. The discriminator also comprises neural network layers that classify samples as real or fake. You can customize both networks based on the specific task and dataset.
Researchers have successfully applied GANs to various tasks, including image generation, style transfer, image-to-image translation, and data augmentation. They have demonstrated remarkable capabilities in generating highly realistic images, synthesizing new data samples, and learning complex data distributions.
Introduction to Super-Resolution GAN
SRGANs aim to address the limitations of traditional super-resolution methods by leveraging the adversarial training framework of GANs. In SRGANs, the generator network takes a low-resolution image as input and learns to produce a corresponding high-resolution image. In contrast, the discriminator network evaluates the realism of the generated image compared to authentic high-resolution images. Through adversarial training, the generator improves its ability to produce visually convincing high-resolution images as the discriminator becomes more proficient at discerning real from fake images.
SRGANs offer several advantages over traditional SR methods. They can generate high-quality images with realistic details, enhanced perceptual quality, and improved structural coherence. By incorporating adversarial training, SRGANs can produce sharper and more visually pleasing results than interpolation-based or heuristic methods. Additionally, SRGANs have the potential to generalize well to diverse image types and exhibit robustness against noise and artifacts.
SRGAN Architecture
Generator Architecture
The generator in an SRGAN actively transforms low-resolution images into high-resolution counterparts while preserving or enhancing their visual quality. The architecture typically comprises several layers of neural networks, often leveraging convolutional and deconvolutional layers to learn hierarchical representations of the input images.
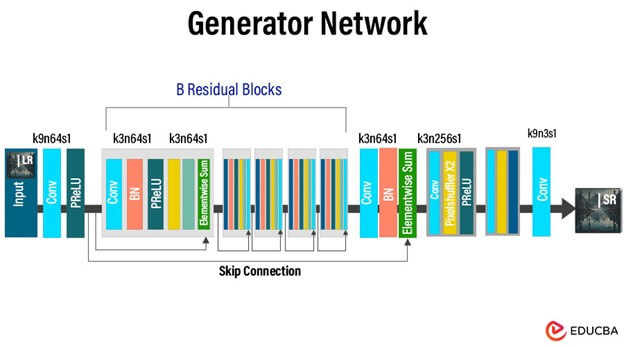
Here’s a breakdown of the key components:
- Input Layer: This layer accepts low-resolution images as input, usually represented as tensors.
- Feature Extraction Layers: The layers comprise convolutional layers specifically engineered to extract features from input images. These layers capture low-level details and spatial information.
- Non-linear Activation Functions: Interspersed between the convolutional layers, activation functions like ReLU (Rectified Linear Unit) introducing non-linearity into the network allows it to capture intricate relationships within the data.
- Upsampling Layers: Utilize transposed convolution (deconvolution) or pixel shuffling to upscale the feature maps, gradually increasing the image’s resolution.
- Residual Blocks: Optional components that facilitate the learning of residual mappings between low-resolution and high-resolution images, helping to alleviate the vanishing gradient problem and improve convergence.
- Output Layer: This layer generates the final high-resolution image, often employing a suitable activation function (e.g., sigmoid or tanh) to normalize pixel values.
Discriminator Architecture
The discriminator in an SRGAN is responsible for distinguishing between real high-resolution images and images generated by the generator. Its architecture accurately classifies images as real or fake.
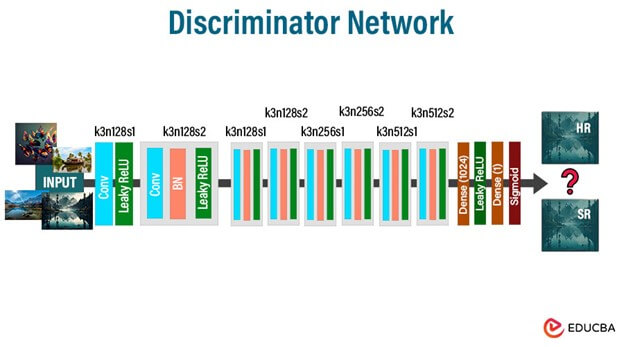
- Input Layer: Accepts either real high-resolution images or images generated by the generator as input.
- Feature Extraction Layers: These layers comprise convolutional layers that extract discriminative features from the input images. They capture high-level semantic information.
- Downsampling Layers: Employ techniques such as max-pooling or convolution with a stride to reduce the spatial dimensions of the feature maps, gradually downsampling the image.
- Non-linear Activation Functions: Like the generator, activation functions like ReLU introduce non-linearity into the network.
- Output Layer: This layer produces a probability score expressing the probability that the input image is authentic. It typically utilizes a sigmoid activation function to squash the output into the range [0, 1], where values closer to 1 correspond to real images and values closer to 0 correspond to fake images.
Loss Function in SRGAN
Why Mean-Squared Error (MSE) Loss isn’t Ideal for SR
Traditionally, Researchers widely use Mean Squared Error (MSE) loss in image reconstruction tasks, including super-resolution. However, MSE loss tends to produce overly smooth results in SR due to its inability to capture high-frequency details. It is because MSE loss penalizes differences in pixel values without considering perceptual similarity, leading to blurry outputs lacking in sharpness and texture. As a result, using MSE loss alone may not effectively capture the fine-grained details necessary for high-quality super-resolution images.
Perceptual Loss
Perceptual loss addresses the shortcomings of MSE loss by incorporating perceptual similarity metrics derived from deep neural networks, such as VGG networks, and adversarial training. It comprises two main components:
Content Loss
Content loss measures the similarity between the features extracted from the generated image and the high-resolution ground truth using a pre-trained deep neural network, often a VGG network.
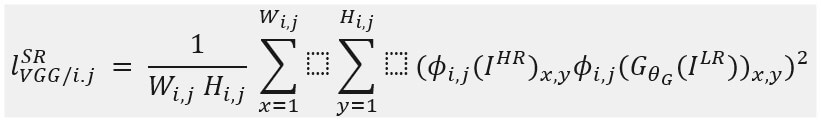
Typically, the VGG network extracts feature maps from generated and ground-truth images. Compute the Euclidean distance between the feature representations of these images, serving as the content loss. By minimizing this loss, the generator learns to produce high-resolution images that closely match the content of the ground-truth images in terms of semantic features.
Adversarial Loss
Adversarial loss is derived from the GAN framework and encourages the generator to produce high-resolution images that are indistinguishable from real images according to the discriminator.
The discriminator assesses the genuineness of the generated images and offers feedback to the generator via adversarial training. The generator seeks to reduce the likelihood that the discriminator accurately classifies its generated images as fake, effectively learning to generate visually convincing high-resolution images.
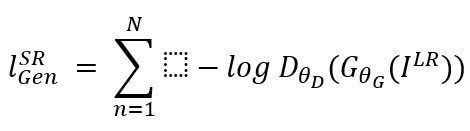
Adversarial loss complements content loss by promoting the generation of realistic textures and details in super-resolved images. It encourages the generator to produce outputs that match the content of the ground truth images and exhibit perceptually realistic features, such as sharp edges and fine textures.
The combination of content loss (VGG loss) and adversarial loss in SRGANs addresses the limitations of MSE loss by capturing perceptual similarity and realism. This combination generates high-quality, realistic, high-resolution images with improved sharpness, texture, and visual fidelity.
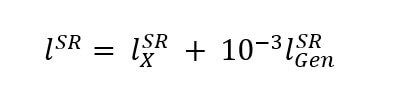
Content loss adversarial loss
Perceptual loss (for VGG-based content losses)
Challenges in Training SRGAN
- Mode Collapse: SRGANs are susceptible to mode collapse, where the generator learns to produce a limited set of outputs, resulting in a lack of diversity in the generated images.
- Training Instability: The adversarial training process in SRGANs can be unstable, leading to oscillations or divergence in the training process. Employ techniques such as batch normalization, gradient clipping, and spectral normalization to stabilize training.
- Hyperparameter Tuning: SRGANs involve numerous hyperparameters, including learning rates, network architectures, and regularization parameters, which require careful tuning to achieve optimal performance.
- Data Quality and Quantity: Both the quality and quantity of training data significantly influence the performance of SRGANs. Insufficient or low-quality training data may lead to poor generalization and suboptimal results.
- Computational Resources: Training SRGANs can be computationally intensive, requiring substantial computational resources, memory, and time. Training on GPUs or distributed computing platforms may be necessary to accelerate the training process.
Advantages of SRGAN over Traditional Methods
1. Realistic Image Generation
SRGANs leverage the power of Generative Adversarial Networks (GANs) to generate high-quality, realistic, high-resolution images from low-resolution inputs. Unlike traditional methods that often produce blurry or unrealistic results, SRGANs excel in generating visually convincing images with sharp details and realistic textures. By incorporating adversarial training, SRGANs learn to capture fine-grained features and structural coherence, resulting in outputs that closely resemble real high-resolution images.
2. Enhanced Perceptual Quality
Traditional super-resolution methods typically rely on simple interpolation techniques or heuristic algorithms, which may need help to preserve perceptual quality and fine details. In contrast, SRGANs employ perceptual loss metrics such as content loss (VGG loss) and adversarial loss to prioritize perceptually relevant features and texture details. This emphasis on perceptual quality enables SRGANs to produce images with improved visual fidelity, sharpness, and texture, making them more suitable for practical applications where high-quality details are essential.
3. Generative Capability
SRGANs possess a generative capability that allows them to synthesize high-resolution images from low-resolution inputs in a data-driven manner. Unlike traditional methods that rely on fixed interpolation kernels or handcrafted features, SRGANs learn complex mappings between low and high-resolution image pairs using large datasets. This generative approach enables SRGANs to adapt to diverse image types and capture intricate patterns and structures in the data, resulting in more robust and versatile super-resolution models.
4. Generalization to Unseen Data
SRGANs trained on large and diverse datasets have demonstrated superior generalization capabilities compared to traditional methods. By learning rich representations of image features through adversarial training, SRGANs can effectively handle variations in content, lighting conditions, and image artifacts in real-world data. This ability to generalize to unseen data ensures that SRGANs produce consistent and reliable results across domains and applications, making them suitable for various practical scenarios.
5. End-to-End Learning
SRGANs enable end-to-end learning of the super-resolution task, allowing the model to directly optimize for the desired output without the need for intermediate processing steps. Traditional methods often involve multiple preprocessing stages, feature extraction, and post-processing, which can introduce additional complexity and potential error sources. In contrast, SRGANs streamline the super-resolution process by learning the mapping from low to high-resolution images in a single integrated framework, resulting in simpler and more efficient workflows.
Applications of SRGAN in Different fields
1. Computer Vision
Researchers widely use SRGANs in computer vision tasks such as image enhancement, object detection, and recognition. By upscaling low-resolution images to higher resolutions with enhanced visual quality, SRGANs improve the performance of computer vision algorithms, enabling more accurate and reliable image analysis in applications such as surveillance, autonomous driving, and augmented reality.
2. Medical Imaging
In medical imaging, SRGANs play a crucial role in improving the resolution and clarity of diagnostic images, such as MRI scans, CT scans, and ultrasound images. By generating high-resolution medical images from low-resolution inputs, SRGANs enhance the visualization of anatomical structures, facilitating more accurate diagnosis, treatment planning, and medical research.
3. Satellite Imaging
SRGANs are employed in satellite imaging applications to enhance the resolution and detail of satellite imagery, such as aerial photographs and satellite maps. By generating high-resolution satellite images from low-resolution inputs, SRGANs enable better monitoring and analysis of environmental changes, urban development, natural disasters, and agricultural patterns, supporting various Earth observation tasks and applications.
4. Remote Sensing
In remote sensing applications, SRGANs improve the resolution and quality of remotely sensed data captured by sensors onboard satellites, drones, or aircraft. By generating high-resolution images from low-resolution sensor data, SRGANs enhance the spatial resolution and detail of remote sensing imagery, enabling more accurate mapping, land cover classification, vegetation analysis, and environmental monitoring.
5. Digital Entertainment
SRGANs are utilized in the digital entertainment industry for tasks such as upscaling low-resolution videos, enhancing image quality in video games, and restoring old or degraded media content. By generating high-quality, realistic, high-resolution images and videos from low-resolution inputs, SRGANs enhance the visual experience for users, leading to more immersive and engaging entertainment content.
Conclusion
SRGANs stand as a significant breakthrough in super-resolution, providing a data-driven method to produce lifelike, high-resolution images from low-resolution sources. By merging Generative Adversarial Networks (GANs) with perceptual loss metrics, SRGANs surmount the constraints of conventional approaches, yielding images with heightened sharpness, texture, and authenticity. Their applicability extends across numerous fields, including computer vision, medical imaging, satellite imaging, and digital entertainment, promising to redefine image processing and analysis paradigms and introduce novel opportunities across diverse domains.
Frequently Asked Questions (FAQs)
Q1. How can I get started with implementing SRGANs?
Answer: Implementing SRGANs typically involves understanding deep learning concepts, familiarity with frameworks like TensorFlow or PyTorch, and access to suitable datasets. Online resources, tutorials, and research papers can guide the implementation and training of SRGANs for specific tasks.
Q2. What are some evaluation metrics used to assess SRGAN performance?
Answer: Common evaluation metrics for SRGANs include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and perceptual metrics based on human perception, such as Mean Opinion Score (MOS) or Visual Turing Test (VTT).
Q3. Are there any pre-trained SRGAN models available?
Answer: Some pre-trained SRGAN models are publicly available and trained on large-scale image datasets such as ImageNet or DIV2K. These pre-trained models can be fine-tuned or used directly for various super-resolution tasks.

